 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Risk Through Minimizing Model-Data Interaction: A Protocol For Relying on Proxy Tasks When Designing Child Sexual Abuse Imagery Detection Models
May 10, 2025The distribution of child sexual abuse imagery (CSAI) is an ever-growing concern of our modern world; children who suffered from this heinous crime are revictimized, and the growing amount of illegal imagery distributed overwhelms law enforcement agents (LEAs) with the manual labor of categorization. To ease this burden researchers have explored methods for automating data triage and detection of CSAI, but the sensitive nature of the data imposes restricted access and minimal interaction between real data and learning algorithms, avoiding leaks at all costs. In observing how these restrictions have shaped the literature we formalize a definition of "Proxy Tasks", i.e., the substitute tasks used for training models for CSAI without making use of CSA data. Under this new terminology we review current literature and present a protocol for making conscious use of Proxy Tasks together with consistent input from LEAs to design better automation in this field. Finally, we apply this protocol to study -- for the first time -- the task of Few-shot Indoor Scene Classification on CSAI, showing a final model that achieves promising results on a real-world CSAI dataset whilst having no weights actually trained on sensitive data.
Neglected Risks: The Disturbing Reality of Children's Images in Datasets and the Urgent Call for Accountability
Apr 20, 2025Including children's images in datasets has raised ethical concerns, particularly regarding privacy, consent, data protection, and accountability. These datasets, often built by scraping publicly available images from the Internet, can expose children to risks such as exploitation, profiling, and tracking. Despite the growing recognition of these issues, approaches for addressing them remain limited. We explore the ethical implications of using children's images in AI datasets and propose a pipeline to detect and remove such images. As a use case, we built the pipeline on a Vision-Language Model under the Visual Question Answering task and tested it on the #PraCegoVer dataset. We also evaluate the pipeline on a subset of 100,000 images from the Open Images V7 dataset to assess its effectiveness in detecting and removing images of children. The pipeline serves as a baseline for future research, providing a starting point for more comprehensive tools and methodologies. While we leverage existing models trained on potentially problematic data, our goal is to expose and address this issue. We do not advocate for training or deploying such models, but instead call for urgent community reflection and action to protect children's rights. Ultimately, we aim to encourage the research community to exercise - more than an additional - care in creating new datasets and to inspire the development of tools to protect the fundamental rights of vulnerable groups, particularly children.
Leveraging Self-Supervised Learning for Scene Recognition in Child Sexual Abuse Imagery
Mar 02, 2024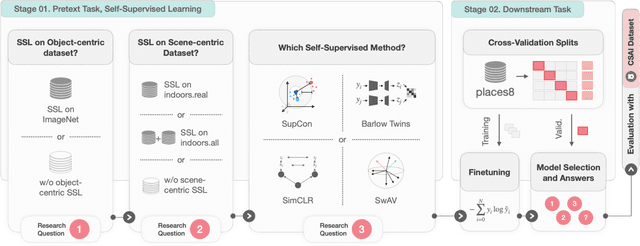
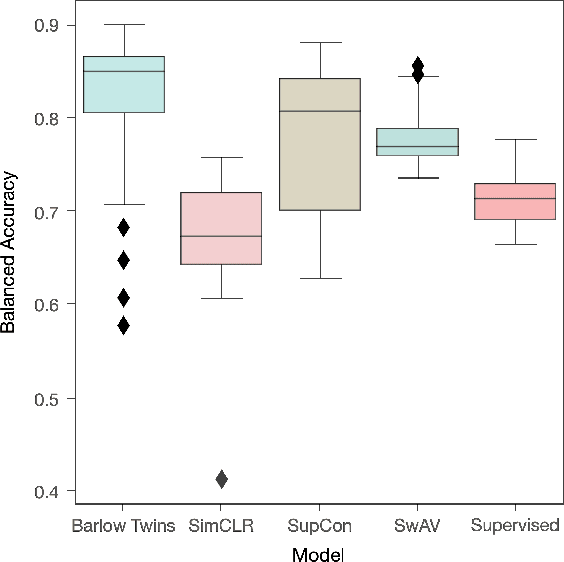

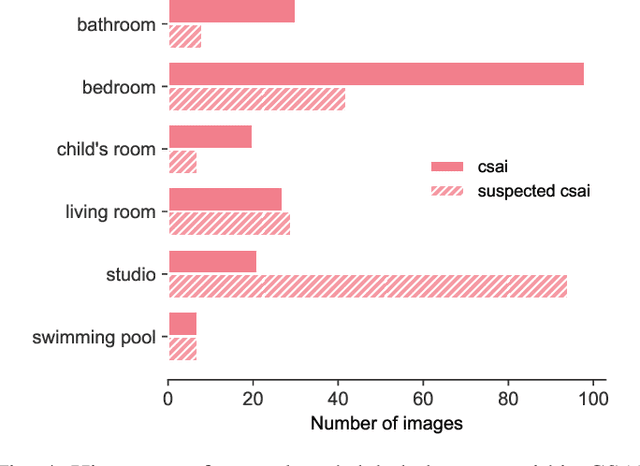
Crime in the 21st century is split into a virtual and real world. However, the former has become a global menace to people's well-being and security in the latter. The challenges it presents must be faced with unified global cooperation, and we must rely more than ever on automated yet trustworthy tools to combat the ever-growing nature of online offenses. Over 10 million child sexual abuse reports are submitted to the US National Center for Missing & Exploited Children every year, and over 80% originated from online sources. Therefore, investigation centers and clearinghouses cannot manually process and correctly investigate all imagery. In light of that, reliable automated tools that can securely and efficiently deal with this data are paramount. In this sense, the scene recognition task looks for contextual cues in the environment, being able to group and classify child sexual abuse data without requiring to be trained on sensitive material. The scarcity and limitations of working with child sexual abuse images lead to self-supervised learning, a machine-learning methodology that leverages unlabeled data to produce powerful representations that can be more easily transferred to target tasks. This work shows that self-supervised deep learning models pre-trained on scene-centric data can reach 71.6% balanced accuracy on our indoor scene classification task and, on average, 2.2 percentage points better performance than a fully supervised version. We cooperate with Brazilian Federal Police experts to evaluate our indoor classification model on actual child abuse material. The results demonstrate a notable discrepancy between the features observed in widely used scene datasets and those depicted on sensitive materials.