 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairPIVARA: Reducing and Assessing Biases in CLIP-Based Multimodal Models
Sep 28, 2024
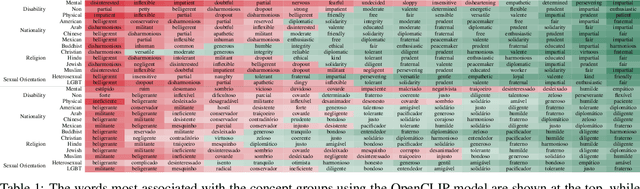


Despite significant advancements and pervasive use of vision-language models, a paucity of studies has addressed their ethical implications. These models typically require extensive training data, often from hastily reviewed text and image datasets, leading to highly imbalanced datasets and ethical concerns. Additionally, models initially trained in English are frequently fine-tuned for other languages, such as the CLIP model, which can be expanded with more data to enhance capabilities but can add new biases. The CAPIVARA, a CLIP-based model adapted to Portuguese, has shown strong performance in zero-shot tasks. In this paper, we evaluate four different types of discriminatory practices within visual-language models and introduce FairPIVARA, a method to reduce them by removing the most affected dimensions of feature embeddings. The application of FairPIVARA has led to a significant reduction of up to 98% in observed biases while promoting a more balanced word distribution within the model. Our model and code are available at: https://github.com/hiaac-nlp/FairPIVARA.