 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairPIVARA: Reducing and Assessing Biases in CLIP-Based Multimodal Models
Sep 28, 2024
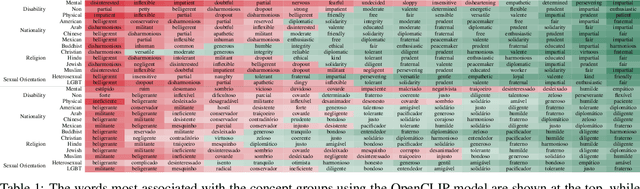


Despite significant advancements and pervasive use of vision-language models, a paucity of studies has addressed their ethical implications. These models typically require extensive training data, often from hastily reviewed text and image datasets, leading to highly imbalanced datasets and ethical concerns. Additionally, models initially trained in English are frequently fine-tuned for other languages, such as the CLIP model, which can be expanded with more data to enhance capabilities but can add new biases. The CAPIVARA, a CLIP-based model adapted to Portuguese, has shown strong performance in zero-shot tasks. In this paper, we evaluate four different types of discriminatory practices within visual-language models and introduce FairPIVARA, a method to reduce them by removing the most affected dimensions of feature embeddings. The application of FairPIVARA has led to a significant reduction of up to 98% in observed biases while promoting a more balanced word distribution within the model. Our model and code are available at: https://github.com/hiaac-nlp/FairPIVARA.
CAPIVARA: Cost-Efficient Approach for Improving Multilingual CLIP Performance on Low-Resource Languages
Oct 23, 2023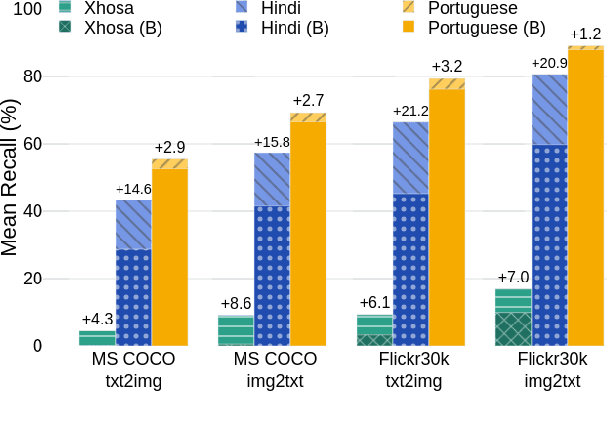



This work introduces CAPIVARA, a cost-efficient framework designed to enhance the performance of multilingual CLIP models in low-resource languages. While CLIP has excelled in zero-shot vision-language tasks, the resource-intensive nature of model training remains challenging. Many datasets lack linguistic diversity, featuring solely English descriptions for images. CAPIVARA addresses this by augmenting text data using image captioning and machine translation to generate multiple synthetic captions in low-resource languages. We optimize the training pipeline with LiT, LoRA, and gradient checkpointing to alleviate the computational cost. Through extensive experiments, CAPIVARA emerges as state of the art in zero-shot tasks involving images and Portuguese texts. We show the potential for significant improvements in other low-resource languages, achieved by fine-tuning the pre-trained multilingual CLIP using CAPIVARA on a single GPU for 2 hours. Our model and code is available at https://github.com/hiaac-nlp/CAPIVARA.
CIDEr-R: Robust Consensus-based Image Description Evaluation
Sep 28, 2021
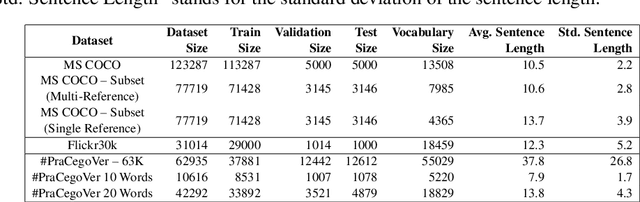

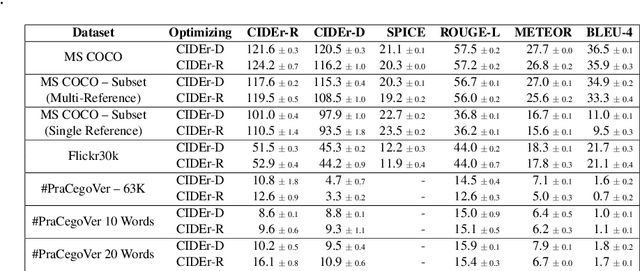
This paper shows that CIDEr-D, a traditional evaluation metric for image description, does not work properly on datasets where the number of words in the sentence is significantly greater than those in the MS COCO Captions dataset. We also show that CIDEr-D has performance hampered by the lack of multiple reference sentences and high variance of sentence length. To bypass this problem, we introduce CIDEr-R, which improves CIDEr-D, making it more flexible in dealing with datasets with high sentence length variance. We demonstrate that CIDEr-R is more accurate and closer to human judgment than CIDEr-D; CIDEr-R is more robust regarding the number of available references. Our results reveal that using Self-Critical Sequence Training to optimize CIDEr-R generates descriptive captions. In contrast, when CIDEr-D is optimized, the generated captions' length tends to be similar to the reference length. However, the models also repeat several times the same word to increase the sentence length.
#PraCegoVer: A Large Dataset for Image Captioning in Portuguese
Mar 21, 2021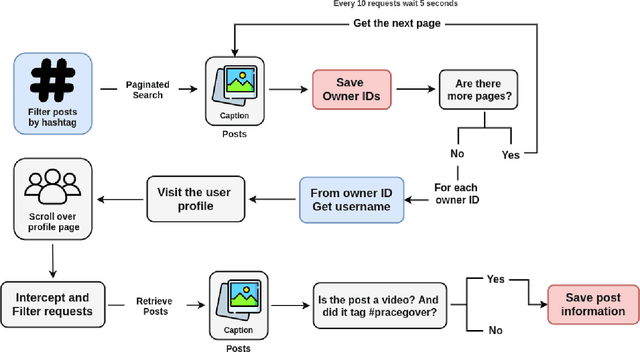


Automatically describing images using natural sentences is an important task to support visually impaired people's inclusion onto the Internet. It is still a big challenge that requires understanding the relation of the objects present in the image and their attributes and actions they are involved in. Then, visual interpretation methods are needed, but linguistic models are also necessary to verbally describe the semantic relations. This problem is known as Image Captioning. Although many datasets were proposed in the literature, the majority contains only English captions, whereas datasets with captions described in other languages are scarce. Recently, a movement called PraCegoVer arose on the Internet, stimulating users from social media to publish images, tag #PraCegoVer and add a short description of their content. Thus, inspired by this movement, we have proposed the #PraCegoVer, a multi-modal dataset with Portuguese captions based on posts from Instagram. It is the first large dataset for image captioning in Portuguese with freely annotated images. Further, the captions in our dataset bring additional challenges to the problem: first, in contrast to popular datasets such as MS COCO Captions, #PraCegoVer has only one reference to each image; also, both mean and variance of our reference sentence length are significantly greater than those in the MS COCO Captions. These two characteristics contribute to making our dataset interesting due to the linguistic aspect and the challenges that it introduces to the image captioning problem. We publicly-share the dataset at https://github.com/gabrielsantosrv/PraCegoVer.