 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Reasoning Models Ask Better Questions? A Formal Information-Theoretic Analysis on Multi-Turn LLM Games
Jan 25, 2026Large Language Models (LLMs) excel at many tasks but still struggle with a critical ability for LLM-based agents: asking good questions for resolving ambiguity in user requests. While prior work has explored information-seeking behavior through word games, existing benchmarks lack comprehensive evaluation frameworks that provide both final and intermediate signals based on Information Gain (IG). Moreover, they rarely provide systematic comparisons between models that use chain-of-thought reasoning and those that do not. We propose a multi-turn dialogue framework that quantitatively measures how effectively LLMs gather information through yes/no questions in a hierarchical knowledge graph environment. Our framework employs a triad of interacting LLM agents that ask questions, answer them, and update the hypothesis space. We adopt IG as the main metric, grounded in Shannon entropy, to assess query effectiveness at each turn and cumulatively. We instantiate our framework in a geographical Guess My City game setting organized in a five-level taxonomy and evaluate multiple LLM variants under fully and partially observable conditions, with and without Chain-of-Thought reasoning. Our experiments demonstrate that, among the evaluated models, the ones with explicit reasoning capabilities achieve higher IG per turn and reach solutions in fewer steps, particularly in partially observable settings. Analysis of reasoning traces reveals that smaller models compensate for limited capacity through more aggressive exploration of candidate questions, while larger models exhibit higher assertiveness in selecting optimal queries, generating candidates with greater potential IG.
Learning Without Critics? Revisiting GRPO in Classical Reinforcement Learning Environments
Nov 05, 2025Group Relative Policy Optimization (GRPO) has emerged as a scalable alternative to Proximal Policy Optimization (PPO) by eliminating the learned critic and instead estimating advantages through group-relative comparisons of trajectories. This simplification raises fundamental questions about the necessity of learned baselines in policy-gradient methods. We present the first systematic study of GRPO in classical single-task reinforcement learning environments, spanning discrete and continuous control tasks. Through controlled ablations isolating baselines, discounting, and group sampling, we reveal three key findings: (1) learned critics remain essential for long-horizon tasks: all critic-free baselines underperform PPO except in short-horizon environments like CartPole where episodic returns can be effective; (2) GRPO benefits from high discount factors (gamma = 0.99) except in HalfCheetah, where lack of early termination favors moderate discounting (gamma = 0.9); (3) smaller group sizes outperform larger ones, suggesting limitations in batch-based grouping strategies that mix unrelated episodes. These results reveal both the limitations of critic-free methods in classical control and the specific conditions where they remain viable alternatives to learned value functions.
InfoQuest: Evaluating Multi-Turn Dialogue Agents for Open-Ended Conversations with Hidden Context
Feb 17, 2025



While large language models excel at following explicit instructions, they often struggle with ambiguous or incomplete user requests, defaulting to verbose, generic responses rather than seeking clarification. We introduce InfoQuest, a multi-turn chat benchmark designed to evaluate how dialogue agents handle hidden context in open-ended user requests. The benchmark presents intentionally ambiguous scenarios that require models to engage in information-seeking dialogue through clarifying questions before providing appropriate responses. Our evaluation of both open and closed-source models reveals that while proprietary models generally perform better, all current assistants struggle with effectively gathering critical information, often requiring multiple turns to infer user intent and frequently defaulting to generic responses without proper clarification. We provide a systematic methodology for generating diverse scenarios and evaluating models' information-seeking capabilities, offering insights into the current limitations of language models in handling ambiguous requests through multi-turn interactions.
Sliding Puzzles Gym: A Scalable Benchmark for State Representation in Visual Reinforcement Learning
Oct 17, 2024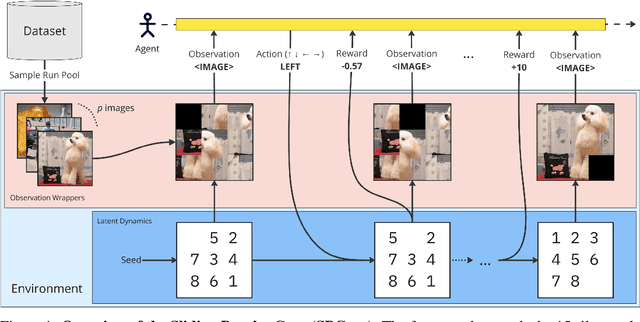


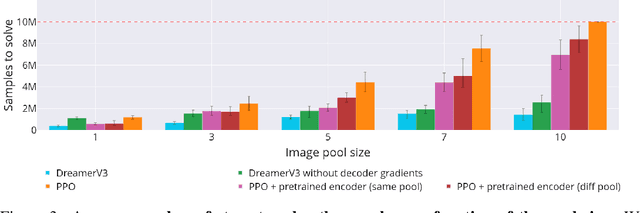
Learning effective visual representations is crucial in open-world environments where agents encounter diverse and unstructured observations. This ability enables agents to extract meaningful information from raw sensory inputs, like pixels, which is essential for generalization across different tasks. However, evaluating representation learning separately from policy learning remains a challenge in most reinforcement learning (RL) benchmarks. To address this, we introduce the Sliding Puzzles Gym (SPGym), a benchmark that extends the classic 15-tile puzzle with variable grid sizes and observation spaces, including large real-world image datasets. SPGym allows scaling the representation learning challenge while keeping the latent environment dynamics and algorithmic problem fixed, providing a targeted assessment of agents' ability to form compositional and generalizable state representations. Experiments with both model-free and model-based RL algorithms, with and without explicit representation learning components, show that as the representation challenge scales, SPGym effectively distinguishes agents based on their capabilities. Moreover, SPGym reaches difficulty levels where no tested algorithm consistently excels, highlighting key challenges and opportunities for advancing representation learning for decision-making research.