 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal-Difference Variational Continual Learning
Paper and Code
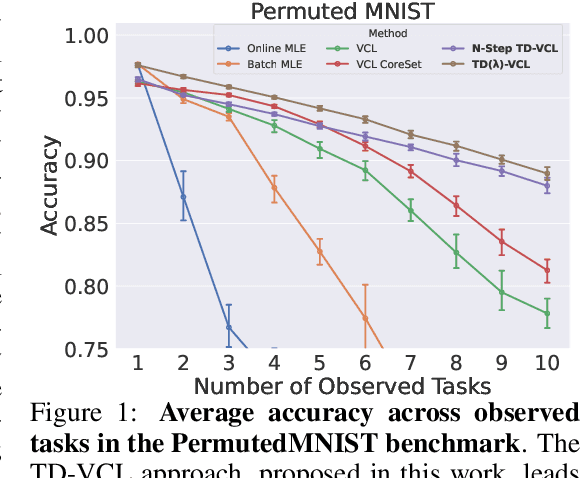
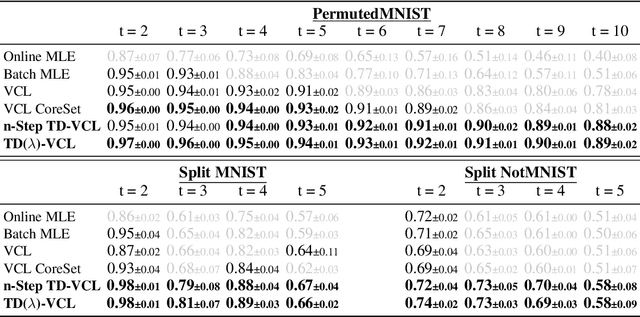
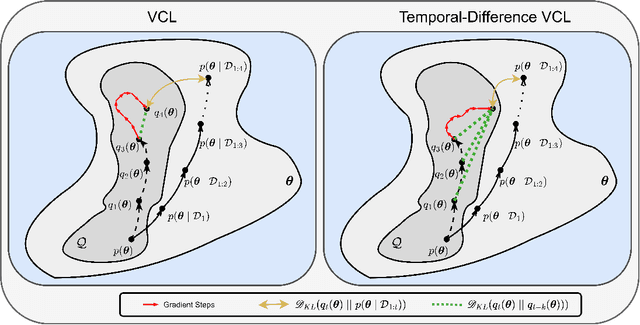

A crucial capability of Machine Learning models in real-world applications is the ability to continuously learn new tasks. This adaptability allows them to respond to potentially inevitable shifts in the data-generating distribution over time. However, in Continual Learning (CL) settings, models often struggle to balance learning new tasks (plasticity) with retaining previous knowledge (memory stability). Consequently, they are susceptible to Catastrophic Forgetting, which degrades performance and undermines the reliability of deployed systems. Variational Continual Learning methods tackle this challenge by employing a learning objective that recursively updates the posterior distribution and enforces it to stay close to the latest posterior estimate. Nonetheless, we argue that these methods may be ineffective due to compounding approximation errors over successive recursions. To mitigate this, we propose new learning objectives that integrate the regularization effects of multiple previous posterior estimations, preventing individual errors from dominating future posterior updates and compounding over time. We reveal insightful connections between these objectives and Temporal-Difference methods, a popular learning mechanism in Reinforcement Learning and Neuroscience. We evaluate the proposed objectives on challenging versions of popular CL benchmarks, demonstrating that they outperform standard Variational CL methods and non-variational baselines, effectively alleviating Catastrophic Forgetting.