 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization of feature embeddings transferred from different video anomaly detection domains
Jan 28, 2019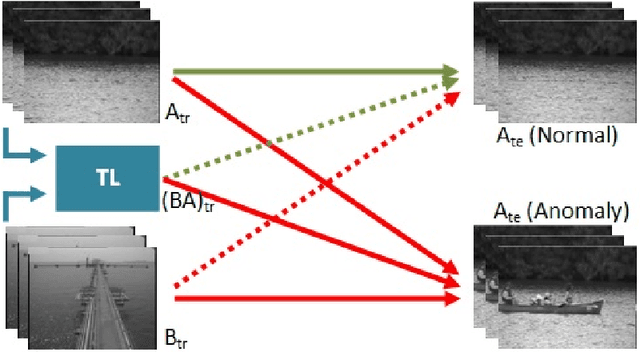


Detecting anomalous activity in video surveillance often involves using only normal activity data in order to learn an accurate detector. Due to lack of annotated data for some specific target domain, one could employ existing data from a source domain to produce better predictions. Hence, transfer learning presents itself as an important tool. But how to analyze the resulting data space? This paper investigates video anomaly detection, in particular feature embeddings of pre-trained CNN that can be used with non-fully supervised data. By proposing novel cross-domain generalization measures, we study how source features can generalize for different target video domains, as well as analyze unsupervised transfer learning. The proposed generalization measures are not only a theorical approach, but show to be useful in practice as a way to understand which datasets can be used or transferred to describe video frames, which it is possible to better discriminate between normal and anomalous activity.
Unsupervised representation learning using convolutional and stacked auto-encoders: a domain and cross-domain feature space analysis
Nov 01, 2018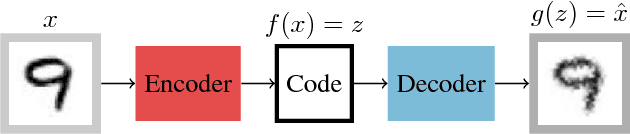
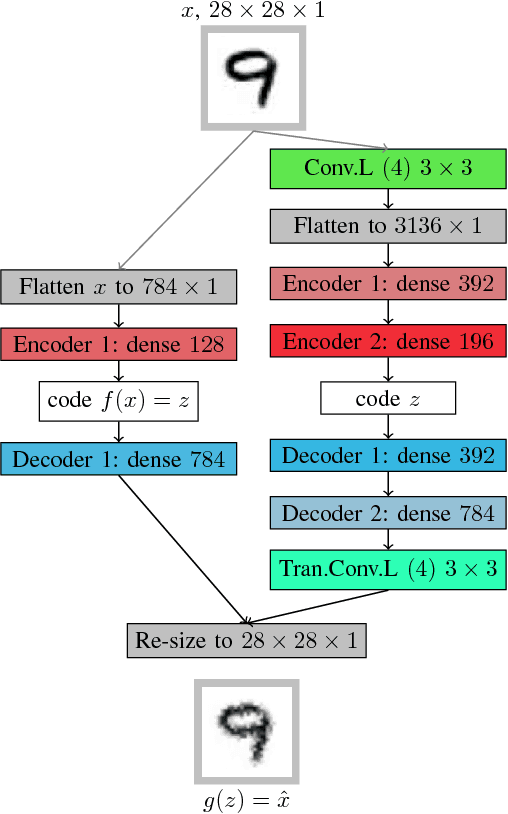


A feature learning task involves training models that are capable of inferring good representations (transformations of the original space) from input data alone. When working with limited or unlabelled data, and also when multiple visual domains are considered, methods that rely on large annotated datasets, such as Convolutional Neural Networks (CNNs), cannot be employed. In this paper we investigate different auto-encoder (AE) architectures, which require no labels, and explore training strategies to learn representations from images. The models are evaluated considering both the reconstruction error of the images and the feature spaces in terms of their discriminative power. We study the role of dense and convolutional layers on the results, as well as the depth and capacity of the networks, since those are shown to affect both the dimensionality reduction and the capability of generalising for different visual domains. Classification results with AE features were as discriminative as pre-trained CNN features. Our findings can be used as guidelines for the design of unsupervised representation learning methods within and across domains.