 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Grid-Based Framework for E-Scooter Demand Representation and Temporal Input Design for Deep Learning: Evidence from Austin, Texas
Mar 13, 2026Despite progress in deep learning for shared micromobility demand prediction, the systematic design and statistical validation of temporal input structures remain underexplored. Temporal features are often selected heuristically, even though historical demand strongly affects model performance and generalizability. This paper introduces a reproducible data-processing pipeline and a statistically grounded method for designing temporal input structures for image-to-image demand prediction. Using large-scale e-scooter data from Austin, Texas, we build a grid-based spatiotemporal dataset by converting trip records into hourly pickup and dropoff demand images. The pipeline includes trip filtering, mapping Census Tracts to spatial locations, grid construction, demand aggregation, and creation of a global activity mask that limits evaluation to historically active areas. This representation supports consistent spatial learning while preserving demand patterns. We then introduce a combined correlation- and error-based procedure to identify informative historical inputs. Optimal temporal depth is selected through an ablation study using a baseline UNET model with paired non-parametric tests and Holm correction. The resulting temporal structures capture short-term persistence as well as daily and weekly cycles. Compared with adjacent-hour and fixed-period baselines, the proposed design reduces mean squared error by up to 37 percent for next-hour prediction and 35 percent for next-24-hour prediction. These results highlight the value of principled dataset construction and statistically validated temporal input design for spatiotemporal micromobility demand prediction.
CCNeXt: An Effective Self-Supervised Stereo Depth Estimation Approach
Sep 26, 2025Depth Estimation plays a crucial role in recent applications in robotics, autonomous vehicles, and augmented reality. These scenarios commonly operate under constraints imposed by computational power. Stereo image pairs offer an effective solution for depth estimation since it only needs to estimate the disparity of pixels in image pairs to determine the depth in a known rectified system. Due to the difficulty in acquiring reliable ground-truth depth data across diverse scenarios, self-supervised techniques emerge as a solution, particularly when large unlabeled datasets are available. We propose a novel self-supervised convolutional approach that outperforms existing state-of-the-art Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) while balancing computational cost. The proposed CCNeXt architecture employs a modern CNN feature extractor with a novel windowed epipolar cross-attention module in the encoder, complemented by a comprehensive redesign of the depth estimation decoder. Our experiments demonstrate that CCNeXt achieves competitive metrics on the KITTI Eigen Split test data while being 10.18$\times$ faster than the current best model and achieves state-of-the-art results in all metrics in the KITTI Eigen Split Improved Ground Truth and Driving Stereo datasets when compared to recently proposed techniques. To ensure complete reproducibility, our project is accessible at \href{https://github.com/alelopes/CCNext}{\texttt{https://github.com/alelopes/CCNext}}.
Trustworthy and Responsible AI for Human-Centric Autonomous Decision-Making Systems
Sep 02, 2024Artificial Intelligence (AI) has paved the way for revolutionary decision-making processes, which if harnessed appropriately, can contribute to advancements in various sectors, from healthcare to economics. However, its black box nature presents significant ethical challenges related to bias and transparency. AI applications are hugely impacted by biases, presenting inconsistent and unreliable findings, leading to significant costs and consequences, highlighting and perpetuating inequalities and unequal access to resources. Hence, developing safe, reliable, ethical, and Trustworthy AI systems is essential. Our team of researchers working with Trustworthy and Responsible AI, part of the Transdisciplinary Scholarship Initiative within the University of Calgary, conducts research on Trustworthy and Responsible AI, including fairness, bias mitigation, reproducibility, generalization, interpretability, and authenticity. In this paper, we review and discuss the intricacies of AI biases, definitions, methods of detection and mitigation, and metrics for evaluating bias. We also discuss open challenges with regard to the trustworthiness and widespread application of AI across diverse domains of human-centric decision making, as well as guidelines to foster Responsible and Trustworthy AI models.
Spectro-ViT: A Vision Transformer Model for GABA-edited MRS Reconstruction Using Spectrograms
Nov 26, 2023Purpose: To investigate the use of a Vision Transformer (ViT) to reconstruct/denoise GABA-edited magnetic resonance spectroscopy (MRS) from a quarter of the typically acquired number of transients using spectrograms. Theory and Methods: A quarter of the typically acquired number of transients collected in GABA-edited MRS scans are pre-processed and converted to a spectrogram image representation using the Short-Time Fourier Transform (STFT). The image representation of the data allows the adaptation of a pre-trained ViT for reconstructing GABA-edited MRS spectra (Spectro-ViT). The Spectro-ViT is fine-tuned and then tested using \textit{in vivo} GABA-edited MRS data. The Spectro-ViT performance is compared against other models in the literature using spectral quality metrics and estimated metabolite concentration values. Results: The Spectro-ViT model significantly outperformed all other models in four out of five quantitative metrics (mean squared error, shape score, GABA+/water fit error, and full width at half maximum). The metabolite concentrations estimated (GABA+/water, GABA+/Cr, and Glx/water) were consistent with the metabolite concentrations estimated using typical GABA-edited MRS scans reconstructed with the full amount of typically collected transients. Conclusion: The proposed Spectro-ViT model achieved state-of-the-art results in reconstructing GABA-edited MRS, and the results indicate these scans could be up to four times faster.
Studying the Effects of Sex-related Differences on Brain Age Prediction using brain MR Imaging
Oct 17, 2023While utilizing machine learning models, one of the most crucial aspects is how bias and fairness affect model outcomes for diverse demographics. This becomes especially relevant in the context of machine learning for medical imaging applications as these models are increasingly being used for diagnosis and treatment planning. In this paper, we study biases related to sex when developing a machine learning model based on brain magnetic resonance images (MRI). We investigate the effects of sex by performing brain age prediction considering different experimental designs: model trained using only female subjects, only male subjects and a balanced dataset. We also perform evaluation on multiple MRI datasets (Calgary-Campinas(CC359) and CamCAN) to assess the generalization capability of the proposed models. We found disparities in the performance of brain age prediction models when trained on distinct sex subgroups and datasets, in both final predictions and decision making (assessed using interpretability models). Our results demonstrated variations in model generalizability across sex-specific subgroups, suggesting potential biases in models trained on unbalanced datasets. This underlines the critical role of careful experimental design in generating fair and reliable outcomes.
A voxel-level approach to brain age prediction: A method to assess regional brain aging
Oct 17, 2023



Brain aging is a regional phenomenon, a facet that remains relatively under-explored within the realm of brain age prediction research using machine learning methods. Voxel-level predictions can provide localized brain age estimates that can provide granular insights into the regional aging processes. This is essential to understand the differences in aging trajectories in healthy versus diseased subjects. In this work, a deep learning-based multitask model is proposed for voxel-level brain age prediction from T1-weighted magnetic resonance images. The proposed model outperforms the models existing in the literature and yields valuable clinical insights when applied to both healthy and diseased populations. Regional analysis is performed on the voxel-level brain age predictions to understand aging trajectories of known anatomical regions in the brain and show that there exist disparities in regional aging trajectories of healthy subjects compared to ones with underlying neurological disorders such as Dementia and more specifically, Alzheimer's disease. Our code is available at https://github.com/nehagianchandani/Voxel-level-brain-age-prediction.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
Reframing the Brain Age Prediction Problem to a More Interpretable and Quantitative Approach
Aug 23, 2023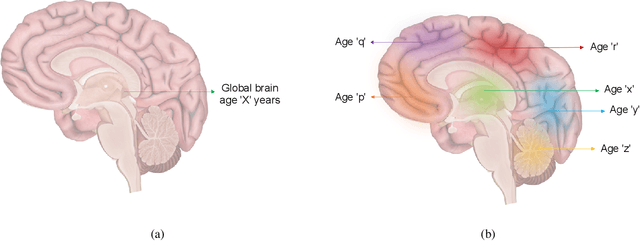

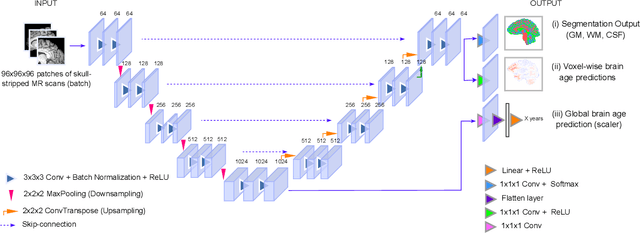
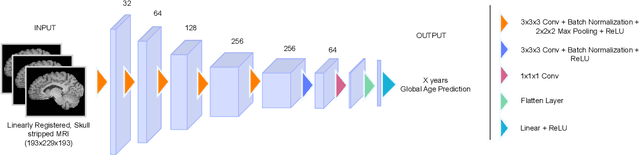
Deep learning models have achieved state-of-the-art results in estimating brain age, which is an important brain health biomarker, from magnetic resonance (MR) images. However, most of these models only provide a global age prediction, and rely on techniques, such as saliency maps to interpret their results. These saliency maps highlight regions in the input image that were significant for the model's predictions, but they are hard to be interpreted, and saliency map values are not directly comparable across different samples. In this work, we reframe the age prediction problem from MR images to an image-to-image regression problem where we estimate the brain age for each brain voxel in MR images. We compare voxel-wise age prediction models against global age prediction models and their corresponding saliency maps. The results indicate that voxel-wise age prediction models are more interpretable, since they provide spatial information about the brain aging process, and they benefit from being quantitative.
A Survey on RGB-D Datasets
Jan 15, 2022


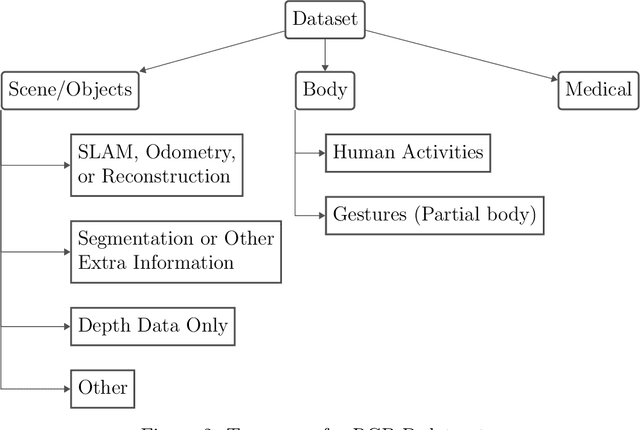
RGB-D data is essential for solving many problems in computer vision. Hundreds of public RGB-D datasets containing various scenes, such as indoor, outdoor, aerial, driving, and medical, have been proposed. These datasets are useful for different applications and are fundamental for addressing classic computer vision tasks, such as monocular depth estimation. This paper reviewed and categorized image datasets that include depth information. We gathered 203 datasets that contain accessible data and grouped them into three categories: scene/objects, body, and medical. We also provided an overview of the different types of sensors, depth applications, and we examined trends and future directions of the usage and creation of datasets containing depth data, and how they can be applied to investigate the development of generalizable machine learning models in the monocular depth estimation field.
Multi-channel MR Reconstruction (MC-MRRec) Challenge -- Comparing Accelerated MR Reconstruction Models and Assessing Their Genereralizability to Datasets Collected with Different Coils
Nov 10, 2020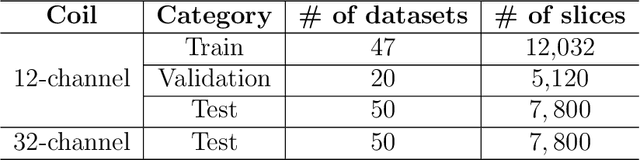
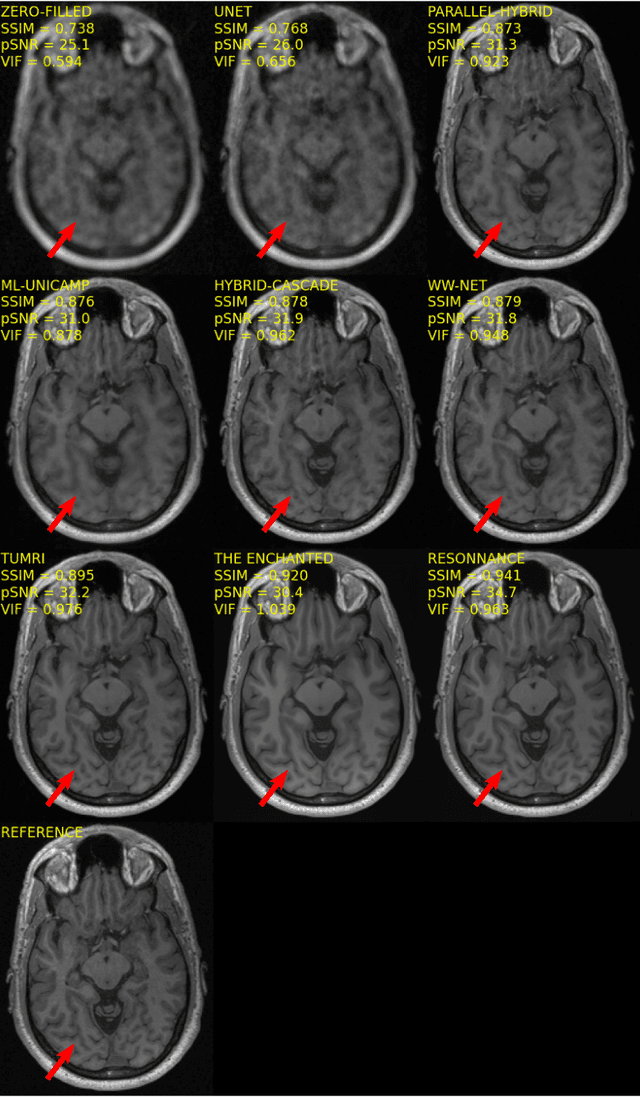
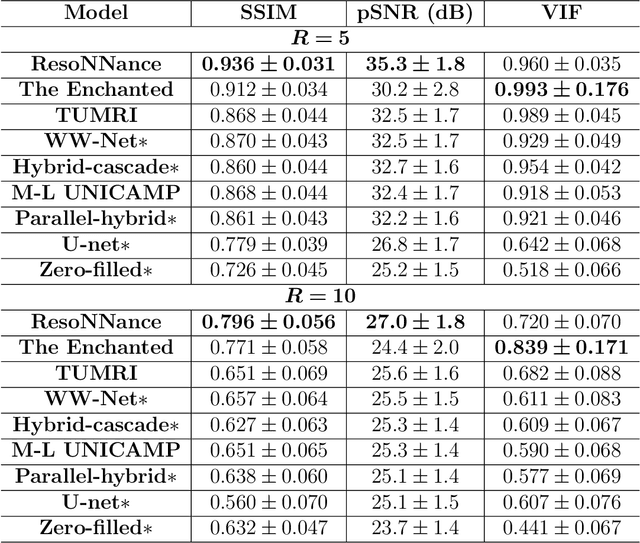
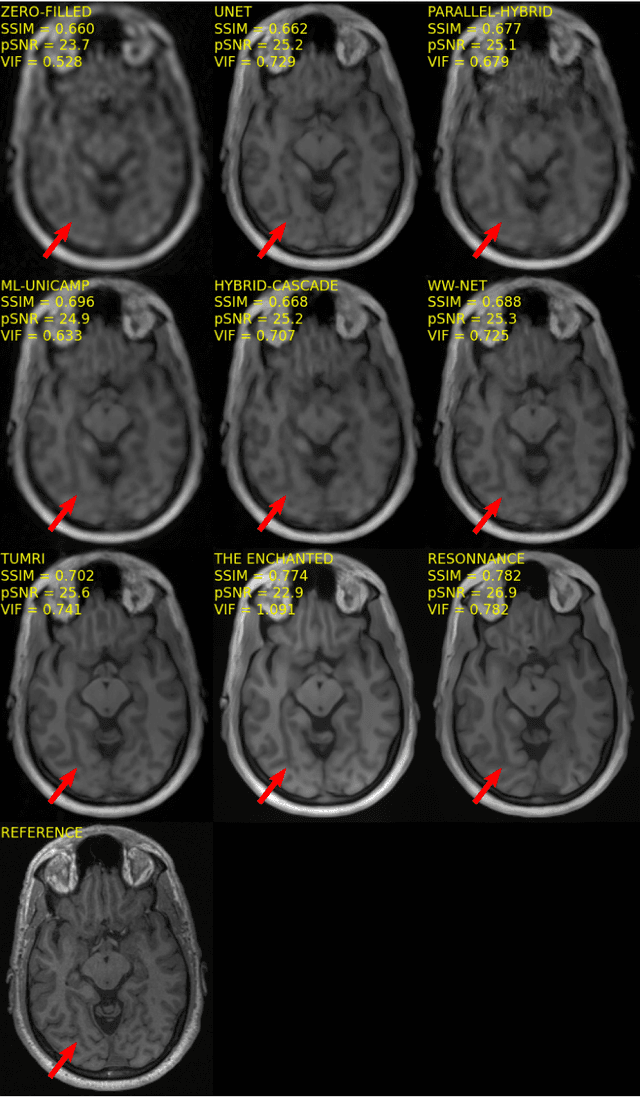
The 2020 Multi-channel Magnetic Resonance Reconstruction (MC-MRRec) Challenge had two primary goals: 1) compare different MR image reconstruction models on a large dataset and 2) assess the generalizability of these models to datasets acquired with a different number of receiver coils (i.e., multiple channels). The challenge had two tracks: Track 01 focused on assessing models trained and tested with 12-channel data. Track 02 focused on assessing models trained with 12-channel data and tested on both 12-channel and 32-channel data. While the challenge is ongoing, here we describe the first edition of the challenge and summarise submissions received prior to 5 September 2020. Track 01 had five baseline models and received four independent submissions. Track 02 had two baseline models and received two independent submissions. This manuscript provides relevant comparative information on the current state-of-the-art of MR reconstruction and highlights the challenges of obtaining generalizable models that are required prior to clinical adoption. Both challenge tracks remain open and will provide an objective performance assessment for future submissions. Subsequent editions of the challenge are proposed to investigate new concepts and strategies, such as the integration of potentially available longitudinal information during the MR reconstruction process. An outline of the proposed second edition of the challenge is presented in this manuscript.