 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrab: Multi Layer Contrastive Supervision to Improve Speech Emotion Recognition Under Both Acted and Natural Speech Condition
Mar 24, 2026Speech Emotion Recognition (SER) in real-world scenarios remains challenging due to severe class imbalance and the prevalence of spontaneous, natural speech. While recent approaches leverage self-supervised learning (SSL) representations and multimodal fusion of speech and text, most existing methods apply supervision only at the final classification layer, limiting the discriminative power of intermediate representations. In this work, we propose Crab (Contrastive Representation and Multimodal Aligned Bottleneck), a bimodal Cross-Modal Transformer architecture that integrates speech representations from WavLM and textual representations from RoBERTa, together with a novel \textit{Multi Layer Contrastive Supervision} (MLCS) strategy. MLCS injects multi-positive contrastive learning signals at multiple layers of the network, encouraging emotionally discriminative representations throughout the model without introducing additional parameters at inference time. To further address data imbalance, we adopt weighted cross-entropy during training. We evaluate the proposed approach on three benchmark datasets covering different degrees of emotional naturalness: IEMOCAP, MELD, and MSP-Podcast 2.0. Experimental results demonstrate that Crab consistently outperforms strong unimodal and multimodal baselines across all datasets, with particularly large gains under naturalistic and highly imbalanced conditions. These findings highlight the effectiveness of \textit{Multi Layer Contrastive Supervision} as a general and robust strategy for SER. Official implementation can be found in https://github.com/AI-Unicamp/Crab.
SelfTTS: cross-speaker style transfer through explicit embedding disentanglement and self-refinement using self-augmentation
Mar 23, 2026This paper presents SelfTTS, a text-to-speech (TTS) model designed for cross-speaker style transfer that eliminates the need for external pre-trained speaker or emotion encoders. The architecture achieves emotional expressivity in neutral speakers through an explicit disentanglement strategy utilizing Gradient Reversal Layers (GRL) combined with cosine similarity loss to decouple speaker and emotion information. We introduce Multi Positive Contrastive Learning (MPCL) to induce clustered representations of speaker and emotion embeddings based on their respective labels. Furthermore, SelfTTS employs a self-refinement strategy via Self-Augmentation, exploiting the model's voice conversion capabilities to enhance the naturalness of synthesized speech. Experimental results demonstrate that SelfTTS achieves superior emotional naturalness (eMOS) and robust stability in target timbre and emotion compared to state-of-the-art baselines.
InstructRobot: A Model-Free Framework for Mapping Natural Language Instructions into Robot Motion
Feb 18, 2025The ability to communicate with robots using natural language is a significant step forward in human-robot interaction. However, accurately translating verbal commands into physical actions is promising, but still presents challenges. Current approaches require large datasets to train the models and are limited to robots with a maximum of 6 degrees of freedom. To address these issues, we propose a framework called InstructRobot that maps natural language instructions into robot motion without requiring the construction of large datasets or prior knowledge of the robot's kinematics model. InstructRobot employs a reinforcement learning algorithm that enables joint learning of language representations and inverse kinematics model, simplifying the entire learning process. The proposed framework is validated using a complex robot with 26 revolute joints in object manipulation tasks, demonstrating its robustness and adaptability in realistic environments. The framework can be applied to any task or domain where datasets are scarce and difficult to create, making it an intuitive and accessible solution to the challenges of training robots using linguistic communication. Open source code for the InstructRobot framework and experiments can be accessed at https://github.com/icleveston/InstructRobot.
Improving Data Augmentation-based Cross-Speaker Style Transfer for TTS with Singing Voice, Style Filtering, and F0 Matching
Oct 08, 2024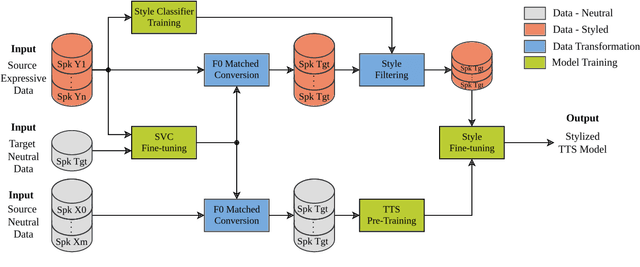


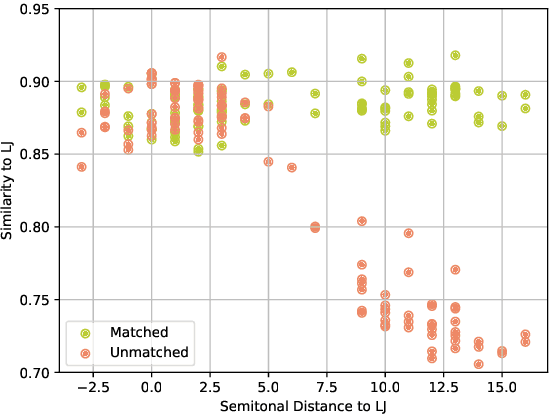
The goal of cross-speaker style transfer in TTS is to transfer a speech style from a source speaker with expressive data to a target speaker with only neutral data. In this context, we propose using a pre-trained singing voice conversion (SVC) model to convert the expressive data into the target speaker's voice. In the conversion process, we apply a fundamental frequency (F0) matching technique to mitigate tonal variances between speakers with significant timbral differences. A style classifier filter is proposed to select the most expressive output audios for the TTS training. Our approach is comparable to state-of-the-art with only a few minutes of neutral data from the target speaker, while other methods require hours. A perceptual assessment showed improvements brought by the SVC and the style filter in naturalness and style intensity for the styles that display more vocal effort. Also, increased speaker similarity is obtained with the proposed F0 matching algorithm.
Exploring synthetic data for cross-speaker style transfer in style representation based TTS
Sep 25, 2024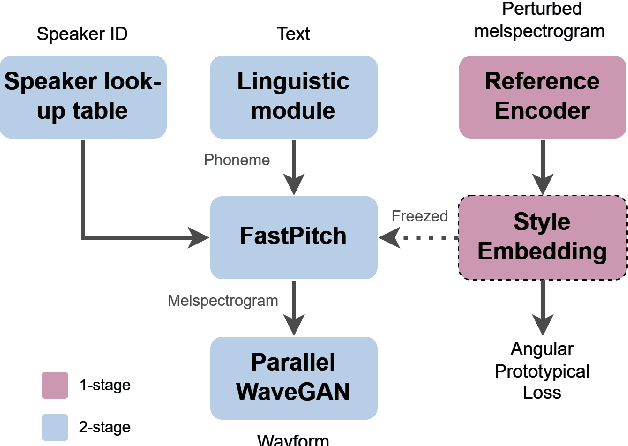
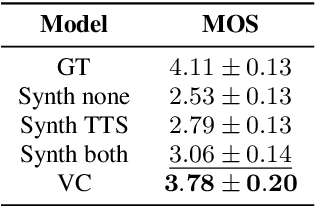
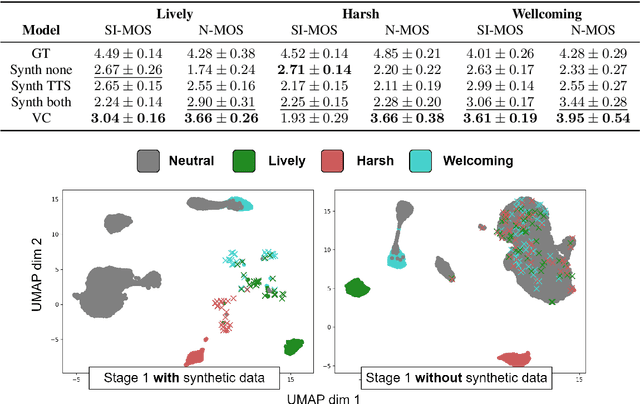
Incorporating cross-speaker style transfer in text-to-speech (TTS) models is challenging due to the need to disentangle speaker and style information in audio. In low-resource expressive data scenarios, voice conversion (VC) can generate expressive speech for target speakers, which can then be used to train the TTS model. However, the quality and style transfer ability of the VC model are crucial for the overall TTS model quality. In this work, we explore the use of synthetic data generated by a VC model to assist the TTS model in cross-speaker style transfer tasks. Additionally, we employ pre-training of the style encoder using timbre perturbation and prototypical angular loss to mitigate speaker leakage. Our results show that using VC synthetic data can improve the naturalness and speaker similarity of TTS in cross-speaker scenarios. Furthermore, we extend this approach to a cross-language scenario, enhancing accent transfer.
Spectro-ViT: A Vision Transformer Model for GABA-edited MRS Reconstruction Using Spectrograms
Nov 26, 2023Purpose: To investigate the use of a Vision Transformer (ViT) to reconstruct/denoise GABA-edited magnetic resonance spectroscopy (MRS) from a quarter of the typically acquired number of transients using spectrograms. Theory and Methods: A quarter of the typically acquired number of transients collected in GABA-edited MRS scans are pre-processed and converted to a spectrogram image representation using the Short-Time Fourier Transform (STFT). The image representation of the data allows the adaptation of a pre-trained ViT for reconstructing GABA-edited MRS spectra (Spectro-ViT). The Spectro-ViT is fine-tuned and then tested using \textit{in vivo} GABA-edited MRS data. The Spectro-ViT performance is compared against other models in the literature using spectral quality metrics and estimated metabolite concentration values. Results: The Spectro-ViT model significantly outperformed all other models in four out of five quantitative metrics (mean squared error, shape score, GABA+/water fit error, and full width at half maximum). The metabolite concentrations estimated (GABA+/water, GABA+/Cr, and Glx/water) were consistent with the metabolite concentrations estimated using typical GABA-edited MRS scans reconstructed with the full amount of typically collected transients. Conclusion: The proposed Spectro-ViT model achieved state-of-the-art results in reconstructing GABA-edited MRS, and the results indicate these scans could be up to four times faster.