 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructRobot: A Model-Free Framework for Mapping Natural Language Instructions into Robot Motion
Feb 18, 2025The ability to communicate with robots using natural language is a significant step forward in human-robot interaction. However, accurately translating verbal commands into physical actions is promising, but still presents challenges. Current approaches require large datasets to train the models and are limited to robots with a maximum of 6 degrees of freedom. To address these issues, we propose a framework called InstructRobot that maps natural language instructions into robot motion without requiring the construction of large datasets or prior knowledge of the robot's kinematics model. InstructRobot employs a reinforcement learning algorithm that enables joint learning of language representations and inverse kinematics model, simplifying the entire learning process. The proposed framework is validated using a complex robot with 26 revolute joints in object manipulation tasks, demonstrating its robustness and adaptability in realistic environments. The framework can be applied to any task or domain where datasets are scarce and difficult to create, making it an intuitive and accessible solution to the challenges of training robots using linguistic communication. Open source code for the InstructRobot framework and experiments can be accessed at https://github.com/icleveston/InstructRobot.
Learning To Explore With Predictive World Model Via Self-Supervised Learning
Feb 18, 2025Autonomous artificial agents must be able to learn behaviors in complex environments without humans to design tasks and rewards. Designing these functions for each environment is not feasible, thus, motivating the development of intrinsic reward functions. In this paper, we propose using several cognitive elements that have been neglected for a long time to build an internal world model for an intrinsically motivated agent. Our agent performs satisfactory iterations with the environment, learning complex behaviors without needing previously designed reward functions. We used 18 Atari games to evaluate what cognitive skills emerge in games that require reactive and deliberative behaviors. Our results show superior performance compared to the state-of-the-art in many test cases with dense and sparse rewards.
QueensCAMP: an RGB-D dataset for robust Visual SLAM
Oct 16, 2024



Visual Simultaneous Localization and Mapping (VSLAM) is a fundamental technology for robotics applications. While VSLAM research has achieved significant advancements, its robustness under challenging situations, such as poor lighting, dynamic environments, motion blur, and sensor failures, remains a challenging issue. To address these challenges, we introduce a novel RGB-D dataset designed for evaluating the robustness of VSLAM systems. The dataset comprises real-world indoor scenes with dynamic objects, motion blur, and varying illumination, as well as emulated camera failures, including lens dirt, condensation, underexposure, and overexposure. Additionally, we offer open-source scripts for injecting camera failures into any images, enabling further customization by the research community. Our experiments demonstrate that ORB-SLAM2, a traditional VSLAM algorithm, and TartanVO, a Deep Learning-based VO algorithm, can experience performance degradation under these challenging conditions. Therefore, this dataset and the camera failure open-source tools provide a valuable resource for developing more robust VSLAM systems capable of handling real-world challenges.
RAM-VO: Less is more in Visual Odometry
Jul 07, 2021
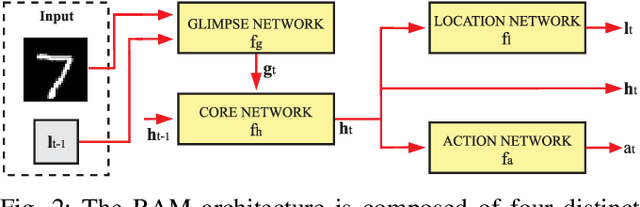
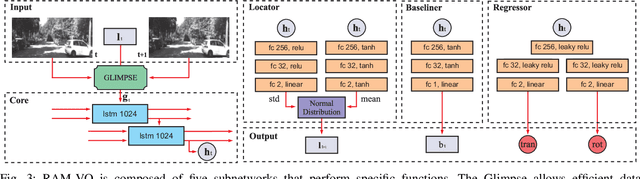
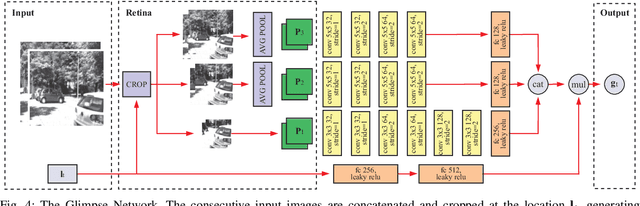
Building vehicles capable of operating without human supervision requires the determination of the agent's pose. Visual Odometry (VO) algorithms estimate the egomotion using only visual changes from the input images. The most recent VO methods implement deep-learning techniques using convolutional neural networks (CNN) extensively, which add a substantial cost when dealing with high-resolution images. Furthermore, in VO tasks, more input data does not mean a better prediction; on the contrary, the architecture may filter out useless information. Therefore, the implementation of computationally efficient and lightweight architectures is essential. In this work, we propose the RAM-VO, an extension of the Recurrent Attention Model (RAM) for visual odometry tasks. RAM-VO improves the visual and temporal representation of information and implements the Proximal Policy Optimization (PPO) algorithm to learn robust policies. The results indicate that RAM-VO can perform regressions with six degrees of freedom from monocular input images using approximately 3 million parameters. In addition, experiments on the KITTI dataset demonstrate that RAM-VO achieves competitive results using only 5.7% of the available visual information.
LIFT-SLAM: a deep-learning feature-based monocular visual SLAM method
Mar 31, 2021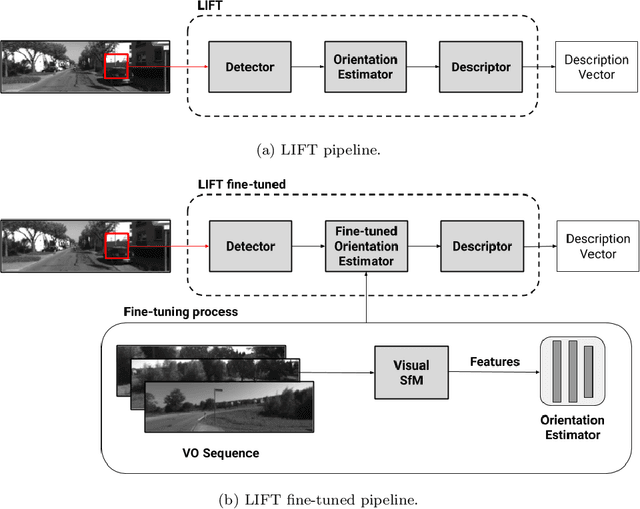
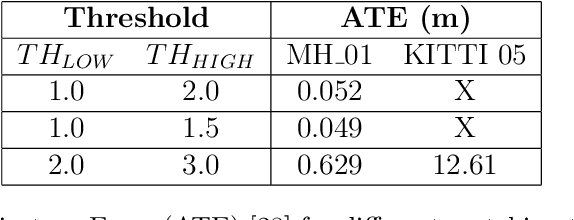
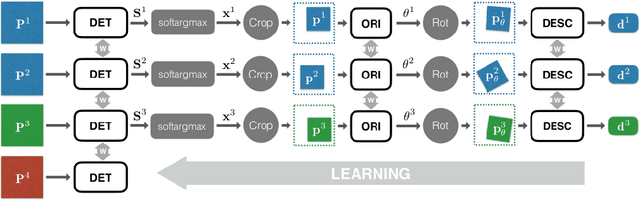
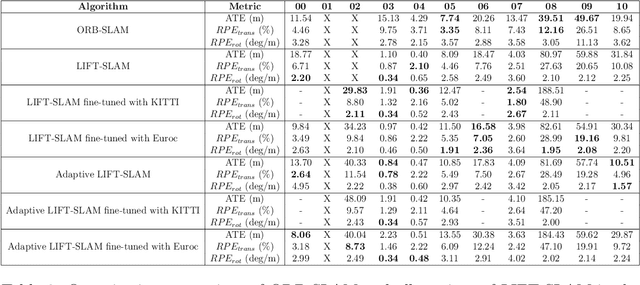
The Simultaneous Localization and Mapping (SLAM) problem addresses the possibility of a robot to localize itself in an unknown environment and simultaneously build a consistent map of this environment. Recently, cameras have been successfully used to get the environment's features to perform SLAM, which is referred to as visual SLAM (VSLAM). However, classical VSLAM algorithms can be easily induced to fail when either the motion of the robot or the environment is too challenging. Although new approaches based on Deep Neural Networks (DNNs) have achieved promising results in VSLAM, they still are unable to outperform traditional methods. To leverage the robustness of deep learning to enhance traditional VSLAM systems, we propose to combine the potential of deep learning-based feature descriptors with the traditional geometry-based VSLAM, building a new VSLAM system called LIFT-SLAM. Experiments conducted on KITTI and Euroc datasets show that deep learning can be used to improve the performance of traditional VSLAM systems, as the proposed approach was able to achieve results comparable to the state-of-the-art while being robust to sensorial noise. We enhance the proposed VSLAM pipeline by avoiding parameter tuning for specific datasets with an adaptive approach while evaluating how transfer learning can affect the quality of the features extracted.
A comparative evaluation of learned feature descriptors on hybrid monocular visual SLAM methods
Mar 31, 2021



Classical Visual Simultaneous Localization and Mapping (VSLAM) algorithms can be easily induced to fail when either the robot's motion or the environment is too challenging. The use of Deep Neural Networks to enhance VSLAM algorithms has recently achieved promising results, which we call hybrid methods. In this paper, we compare the performance of hybrid monocular VSLAM methods with different learned feature descriptors. To this end, we propose a set of experiments to evaluate the robustness of the algorithms under different environments, camera motion, and camera sensor noise. Experiments conducted on KITTI and Euroc MAV datasets confirm that learned feature descriptors can create more robust VSLAM systems.
* 6 pages, Published in 2020 Latin American Robotics Symposium (LARS)
Top-down and Bottom-up Feature Combination for Multi-sensor Attentive Robots
Jul 22, 2013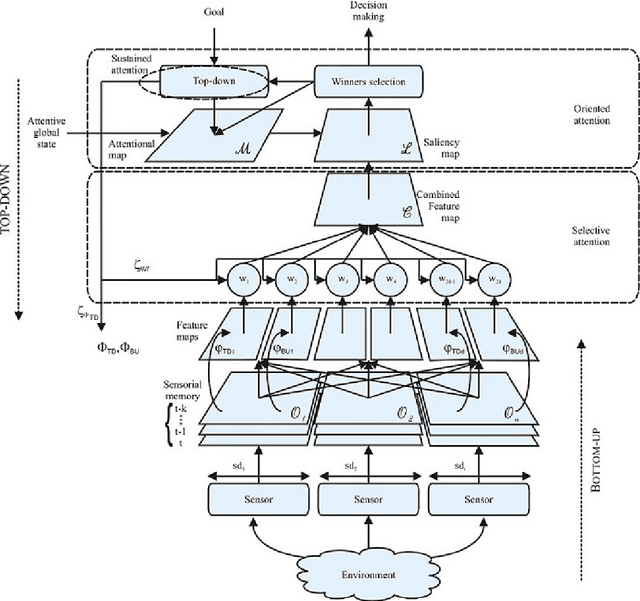
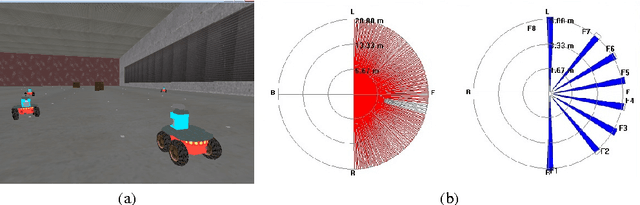
The information available to robots in real tasks is widely distributed both in time and space, requiring the agent to search for relevant data. In humans, that face the same problem when sounds, images and smells are presented to their sensors in a daily scene, a natural system is applied: Attention. As vision plays an important role in our routine, most research regarding attention has involved this sensorial system and the same has been replicated to the robotics field. However,most of the robotics tasks nowadays do not rely only in visual data, that are still costly. To allow the use of attentive concepts with other robotics sensors that are usually used in tasks such as navigation, self-localization, searching and mapping, a generic attentional model has been previously proposed. In this work, feature mapping functions were designed to build feature maps to this attentive model from data from range scanner and sonar sensors. Experiments were performed in a high fidelity simulated robotics environment and results have demonstrated the capability of the model on dealing with both salient stimuli and goal-driven attention over multiple features extracted from multiple sensors.