 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructRobot: A Model-Free Framework for Mapping Natural Language Instructions into Robot Motion
Feb 18, 2025The ability to communicate with robots using natural language is a significant step forward in human-robot interaction. However, accurately translating verbal commands into physical actions is promising, but still presents challenges. Current approaches require large datasets to train the models and are limited to robots with a maximum of 6 degrees of freedom. To address these issues, we propose a framework called InstructRobot that maps natural language instructions into robot motion without requiring the construction of large datasets or prior knowledge of the robot's kinematics model. InstructRobot employs a reinforcement learning algorithm that enables joint learning of language representations and inverse kinematics model, simplifying the entire learning process. The proposed framework is validated using a complex robot with 26 revolute joints in object manipulation tasks, demonstrating its robustness and adaptability in realistic environments. The framework can be applied to any task or domain where datasets are scarce and difficult to create, making it an intuitive and accessible solution to the challenges of training robots using linguistic communication. Open source code for the InstructRobot framework and experiments can be accessed at https://github.com/icleveston/InstructRobot.
Análise de ambiguidade linguística em modelos de linguagem de grande escala (LLMs)
Apr 25, 2024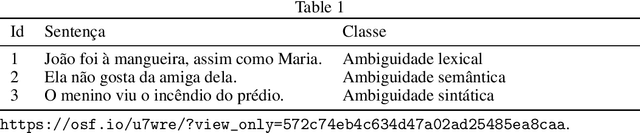
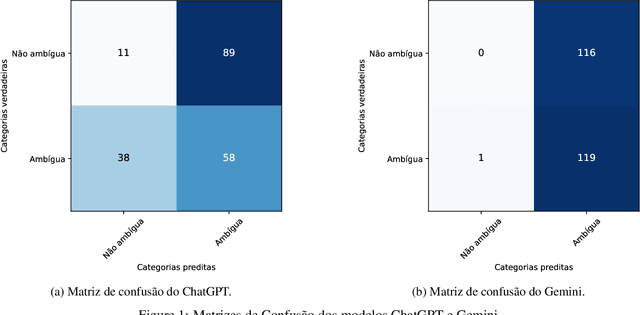
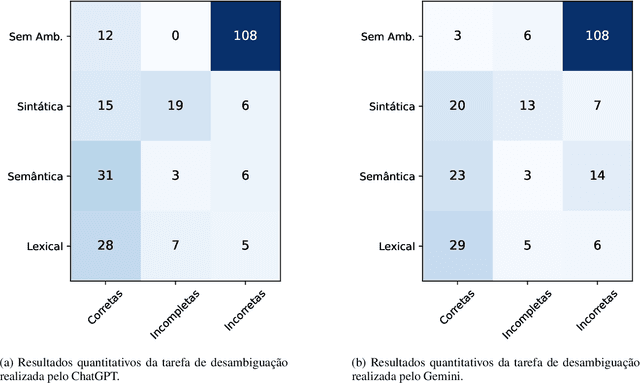

Linguistic ambiguity continues to represent a significant challenge for natural language processing (NLP) systems, notwithstanding the advancements in architectures such as Transformers and BERT. Inspired by the recent success of instructional models like ChatGPT and Gemini (In 2023, the artificial intelligence was called Bard.), this study aims to analyze and discuss linguistic ambiguity within these models, focusing on three types prevalent in Brazilian Portuguese: semantic, syntactic, and lexical ambiguity. We create a corpus comprising 120 sentences, both ambiguous and unambiguous, for classification, explanation, and disambiguation. The models capability to generate ambiguous sentences was also explored by soliciting sets of sentences for each type of ambiguity. The results underwent qualitative analysis, drawing on recognized linguistic references, and quantitative assessment based on the accuracy of the responses obtained. It was evidenced that even the most sophisticated models, such as ChatGPT and Gemini, exhibit errors and deficiencies in their responses, with explanations often providing inconsistent. Furthermore, the accuracy peaked at 49.58 percent, indicating the need for descriptive studies for supervised learning.
RAM-VO: Less is more in Visual Odometry
Jul 07, 2021
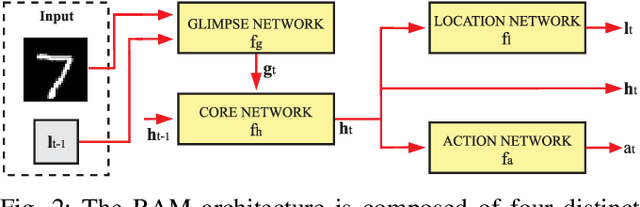
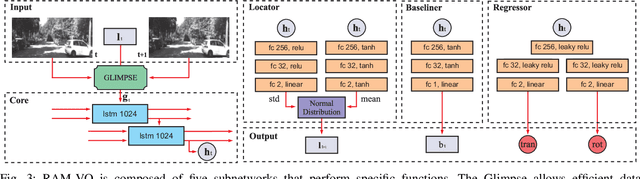
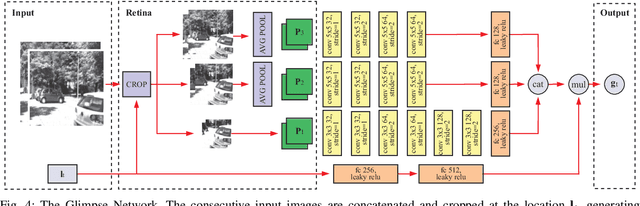
Building vehicles capable of operating without human supervision requires the determination of the agent's pose. Visual Odometry (VO) algorithms estimate the egomotion using only visual changes from the input images. The most recent VO methods implement deep-learning techniques using convolutional neural networks (CNN) extensively, which add a substantial cost when dealing with high-resolution images. Furthermore, in VO tasks, more input data does not mean a better prediction; on the contrary, the architecture may filter out useless information. Therefore, the implementation of computationally efficient and lightweight architectures is essential. In this work, we propose the RAM-VO, an extension of the Recurrent Attention Model (RAM) for visual odometry tasks. RAM-VO improves the visual and temporal representation of information and implements the Proximal Policy Optimization (PPO) algorithm to learn robust policies. The results indicate that RAM-VO can perform regressions with six degrees of freedom from monocular input images using approximately 3 million parameters. In addition, experiments on the KITTI dataset demonstrate that RAM-VO achieves competitive results using only 5.7% of the available visual information.