 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversidade linguística e inclusão digital: desafios para uma ia brasileira
Nov 02, 2024Linguistic diversity is a human attribute which, with the advance of generative AIs, is coming under threat. This paper, based on the contributions of sociolinguistics, examines the consequences of the variety selection bias imposed by technological applications and the vicious circle of preserving a variety that becomes dominant and standardized because it has linguistic documentation to feed the large language models for machine learning.
Performance in a dialectal profiling task of LLMs for varieties of Brazilian Portuguese
Oct 14, 2024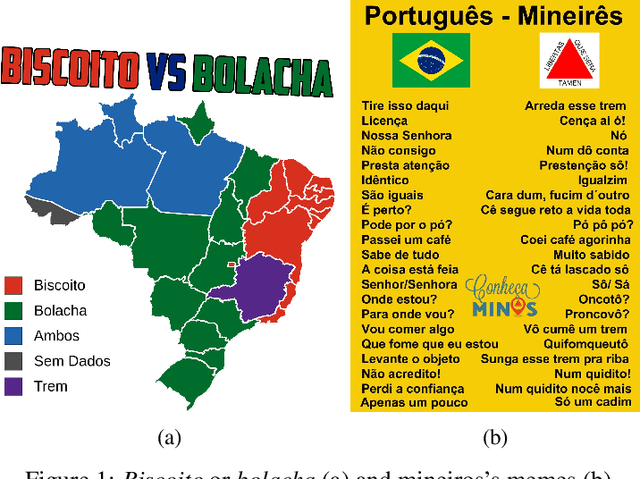

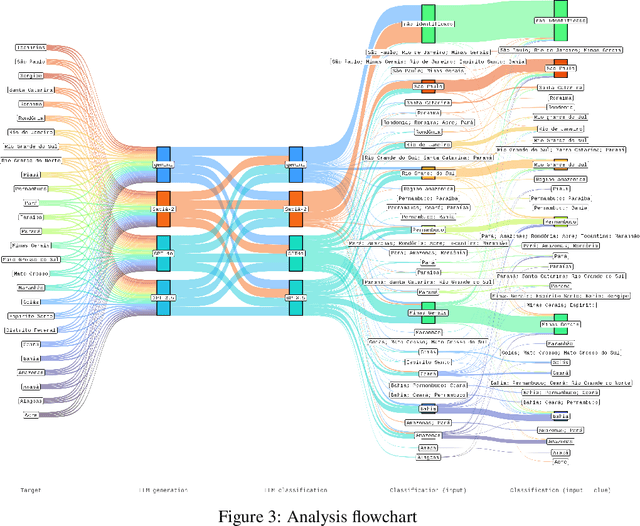

Different of biases are reproduced in LLM-generated responses, including dialectal biases. A study based on prompt engineering was carried out to uncover how LLMs discriminate varieties of Brazilian Portuguese, specifically if sociolinguistic rules are taken into account in four LLMs: GPT 3.5, GPT-4o, Gemini, and Sabi.-2. The results offer sociolinguistic contributions for an equity fluent NLP technology.
Análise de ambiguidade linguística em modelos de linguagem de grande escala (LLMs)
Apr 25, 2024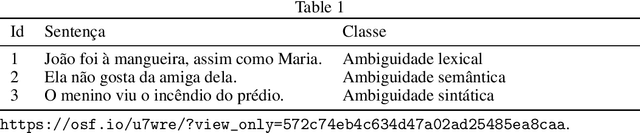
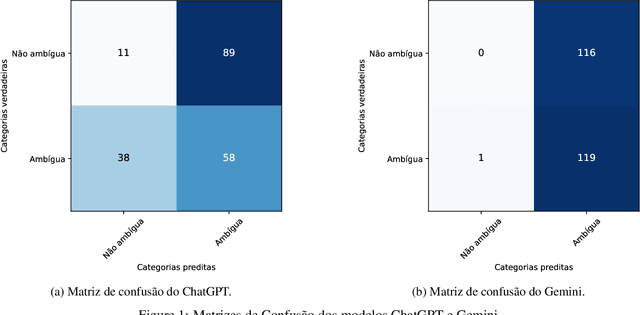
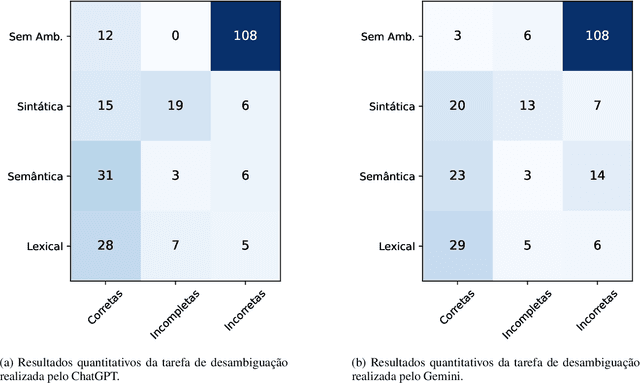

Linguistic ambiguity continues to represent a significant challenge for natural language processing (NLP) systems, notwithstanding the advancements in architectures such as Transformers and BERT. Inspired by the recent success of instructional models like ChatGPT and Gemini (In 2023, the artificial intelligence was called Bard.), this study aims to analyze and discuss linguistic ambiguity within these models, focusing on three types prevalent in Brazilian Portuguese: semantic, syntactic, and lexical ambiguity. We create a corpus comprising 120 sentences, both ambiguous and unambiguous, for classification, explanation, and disambiguation. The models capability to generate ambiguous sentences was also explored by soliciting sets of sentences for each type of ambiguity. The results underwent qualitative analysis, drawing on recognized linguistic references, and quantitative assessment based on the accuracy of the responses obtained. It was evidenced that even the most sophisticated models, such as ChatGPT and Gemini, exhibit errors and deficiencies in their responses, with explanations often providing inconsistent. Furthermore, the accuracy peaked at 49.58 percent, indicating the need for descriptive studies for supervised learning.