 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgenegativas: a prototype for searching and classifying sentential negation in speech data
Apr 05, 2025
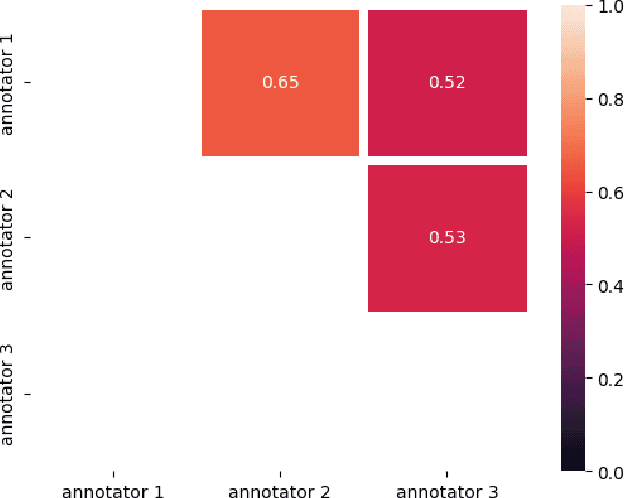

Negation is a universal feature of natural languages. In Brazilian Portuguese, the most commonly used negation particle is n\~ao, which can scope over nouns or verbs. When it scopes over a verb, n\~ao can occur in three positions: pre-verbal (NEG1), double negation (NEG2), or post-verbal (NEG3), e.g., n\~ao gosto, n\~ao gosto n\~ao, gosto n\~ao ("I do not like it"). From a variationist perspective, these structures are different forms of expressing negation. Pragmatically, they serve distinct communicative functions, such as politeness and modal evaluation. Despite their grammatical acceptability, these forms differ in frequency. NEG1 dominates across Brazilian regions, while NEG2 and NEG3 appear more rarely, suggesting its use is contextually restricted. This low-frequency challenges research, often resulting in subjective, non-generalizable interpretations of verbal negation with n\~ao. To address this, we developed negativas, a tool for automatically identifying NEG1, NEG2, and NEG3 in transcribed data. The tool's development involved four stages: i) analyzing a dataset of 22 interviews from the Falares Sergipanos database, annotated by three linguists, ii) creating a code using natural language processing (NLP) techniques, iii) running the tool, iv) evaluating accuracy. Inter-annotator consistency, measured using Fleiss' Kappa, was moderate (0.57). The tool identified 3,338 instances of n\~ao, classifying 2,085 as NEG1, NEG2, or NEG3, achieving a 93% success rate. However, negativas has limitations. NEG1 accounted for 91.5% of identified structures, while NEG2 and NEG3 represented 7.2% and 1.2%, respectively. The tool struggled with NEG2, sometimes misclassifying instances as overlapping structures (NEG1/NEG2/NEG3).
NLP and Education: using semantic similarity to evaluate filled gaps in a large-scale Cloze test in the classroom
Nov 02, 2024This study examines the applicability of the Cloze test, a widely used tool for assessing text comprehension proficiency, while highlighting its challenges in large-scale implementation. To address these limitations, an automated correction approach was proposed, utilizing Natural Language Processing (NLP) techniques, particularly word embeddings (WE) models, to assess semantic similarity between expected and provided answers. Using data from Cloze tests administered to students in Brazil, WE models for Brazilian Portuguese (PT-BR) were employed to measure the semantic similarity of the responses. The results were validated through an experimental setup involving twelve judges who classified the students' answers. A comparative analysis between the WE models' scores and the judges' evaluations revealed that GloVe was the most effective model, demonstrating the highest correlation with the judges' assessments. This study underscores the utility of WE models in evaluating semantic similarity and their potential to enhance large-scale Cloze test assessments. Furthermore, it contributes to educational assessment methodologies by offering a more efficient approach to evaluating reading proficiency.
Performance in a dialectal profiling task of LLMs for varieties of Brazilian Portuguese
Oct 14, 2024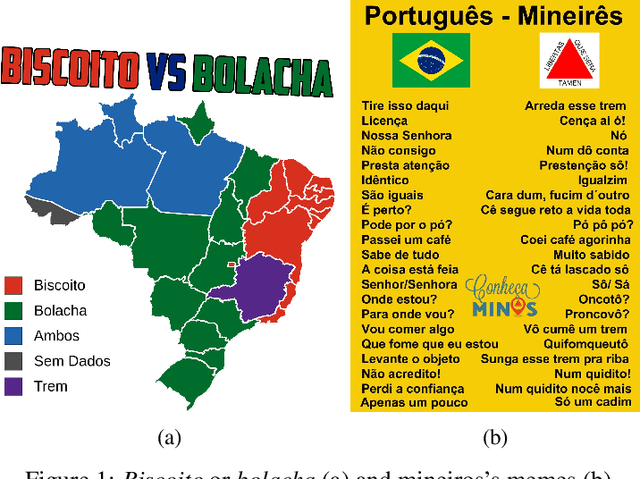

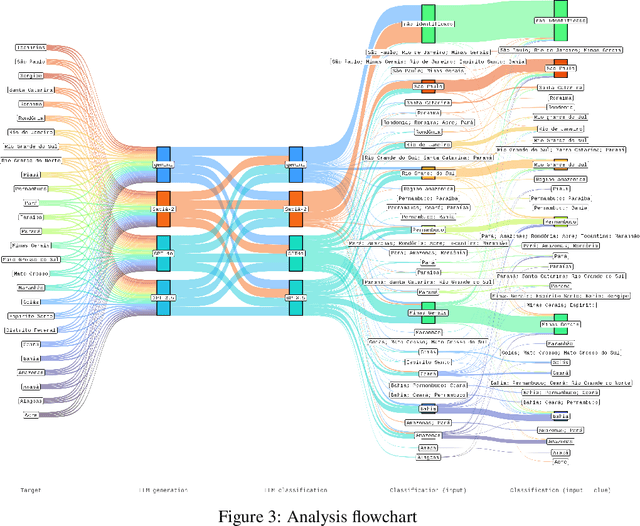

Different of biases are reproduced in LLM-generated responses, including dialectal biases. A study based on prompt engineering was carried out to uncover how LLMs discriminate varieties of Brazilian Portuguese, specifically if sociolinguistic rules are taken into account in four LLMs: GPT 3.5, GPT-4o, Gemini, and Sabi.-2. The results offer sociolinguistic contributions for an equity fluent NLP technology.