 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAM-VO: Less is more in Visual Odometry
Paper and Code
Jul 07, 2021
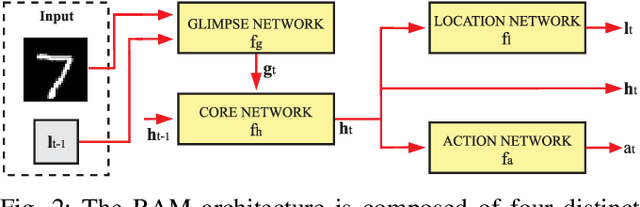
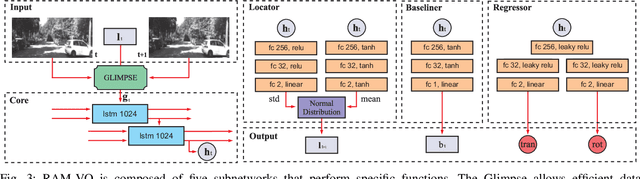
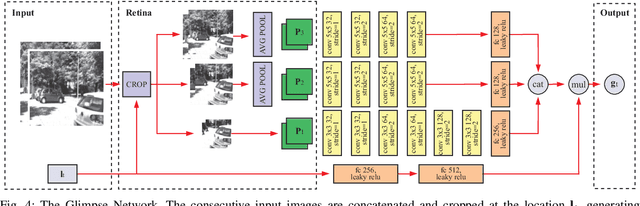
Building vehicles capable of operating without human supervision requires the determination of the agent's pose. Visual Odometry (VO) algorithms estimate the egomotion using only visual changes from the input images. The most recent VO methods implement deep-learning techniques using convolutional neural networks (CNN) extensively, which add a substantial cost when dealing with high-resolution images. Furthermore, in VO tasks, more input data does not mean a better prediction; on the contrary, the architecture may filter out useless information. Therefore, the implementation of computationally efficient and lightweight architectures is essential. In this work, we propose the RAM-VO, an extension of the Recurrent Attention Model (RAM) for visual odometry tasks. RAM-VO improves the visual and temporal representation of information and implements the Proximal Policy Optimization (PPO) algorithm to learn robust policies. The results indicate that RAM-VO can perform regressions with six degrees of freedom from monocular input images using approximately 3 million parameters. In addition, experiments on the KITTI dataset demonstrate that RAM-VO achieves competitive results using only 5.7% of the available visual information.