 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueensCAMP: an RGB-D dataset for robust Visual SLAM
Oct 16, 2024



Visual Simultaneous Localization and Mapping (VSLAM) is a fundamental technology for robotics applications. While VSLAM research has achieved significant advancements, its robustness under challenging situations, such as poor lighting, dynamic environments, motion blur, and sensor failures, remains a challenging issue. To address these challenges, we introduce a novel RGB-D dataset designed for evaluating the robustness of VSLAM systems. The dataset comprises real-world indoor scenes with dynamic objects, motion blur, and varying illumination, as well as emulated camera failures, including lens dirt, condensation, underexposure, and overexposure. Additionally, we offer open-source scripts for injecting camera failures into any images, enabling further customization by the research community. Our experiments demonstrate that ORB-SLAM2, a traditional VSLAM algorithm, and TartanVO, a Deep Learning-based VO algorithm, can experience performance degradation under these challenging conditions. Therefore, this dataset and the camera failure open-source tools provide a valuable resource for developing more robust VSLAM systems capable of handling real-world challenges.
LIFT-SLAM: a deep-learning feature-based monocular visual SLAM method
Mar 31, 2021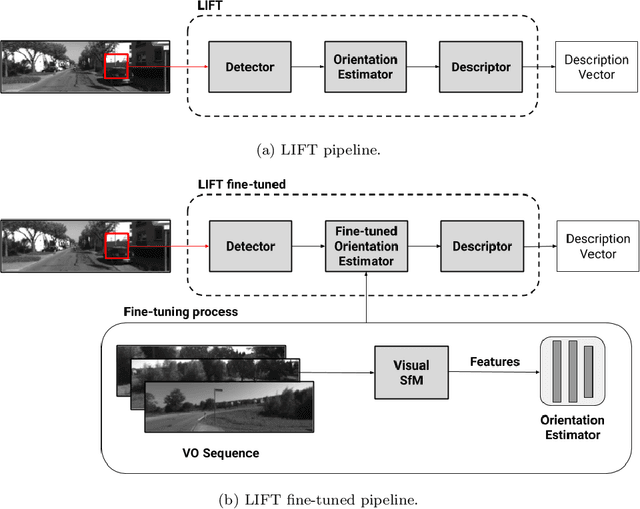
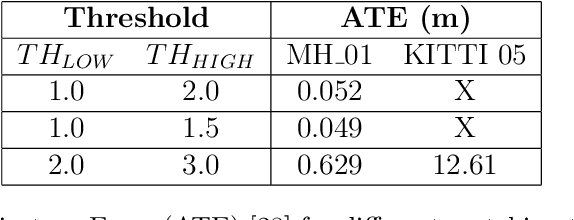
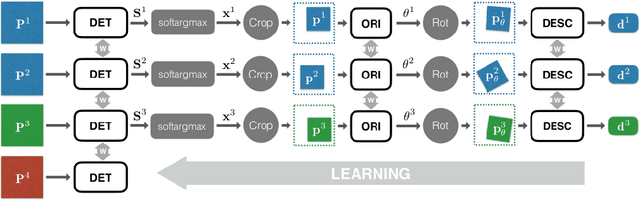
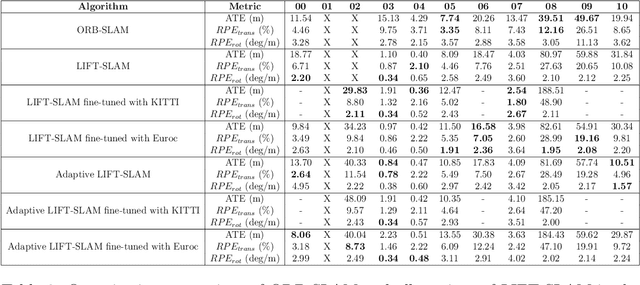
The Simultaneous Localization and Mapping (SLAM) problem addresses the possibility of a robot to localize itself in an unknown environment and simultaneously build a consistent map of this environment. Recently, cameras have been successfully used to get the environment's features to perform SLAM, which is referred to as visual SLAM (VSLAM). However, classical VSLAM algorithms can be easily induced to fail when either the motion of the robot or the environment is too challenging. Although new approaches based on Deep Neural Networks (DNNs) have achieved promising results in VSLAM, they still are unable to outperform traditional methods. To leverage the robustness of deep learning to enhance traditional VSLAM systems, we propose to combine the potential of deep learning-based feature descriptors with the traditional geometry-based VSLAM, building a new VSLAM system called LIFT-SLAM. Experiments conducted on KITTI and Euroc datasets show that deep learning can be used to improve the performance of traditional VSLAM systems, as the proposed approach was able to achieve results comparable to the state-of-the-art while being robust to sensorial noise. We enhance the proposed VSLAM pipeline by avoiding parameter tuning for specific datasets with an adaptive approach while evaluating how transfer learning can affect the quality of the features extracted.
A comparative evaluation of learned feature descriptors on hybrid monocular visual SLAM methods
Mar 31, 2021



Classical Visual Simultaneous Localization and Mapping (VSLAM) algorithms can be easily induced to fail when either the robot's motion or the environment is too challenging. The use of Deep Neural Networks to enhance VSLAM algorithms has recently achieved promising results, which we call hybrid methods. In this paper, we compare the performance of hybrid monocular VSLAM methods with different learned feature descriptors. To this end, we propose a set of experiments to evaluate the robustness of the algorithms under different environments, camera motion, and camera sensor noise. Experiments conducted on KITTI and Euroc MAV datasets confirm that learned feature descriptors can create more robust VSLAM systems.
* 6 pages, Published in 2020 Latin American Robotics Symposium (LARS)