 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Data Augmentation-based Cross-Speaker Style Transfer for TTS with Singing Voice, Style Filtering, and F0 Matching
Paper and Code
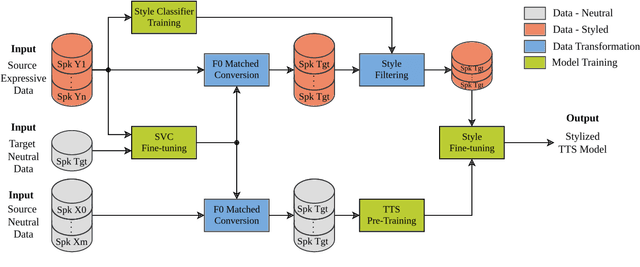


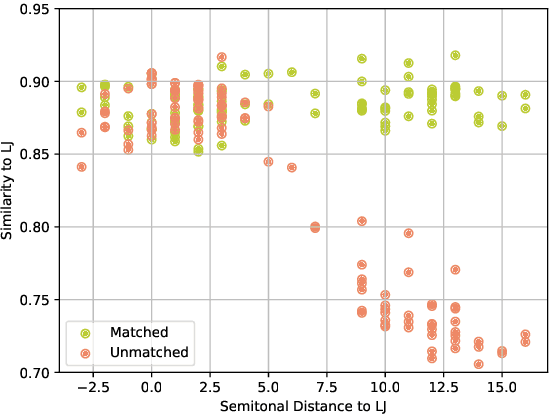
The goal of cross-speaker style transfer in TTS is to transfer a speech style from a source speaker with expressive data to a target speaker with only neutral data. In this context, we propose using a pre-trained singing voice conversion (SVC) model to convert the expressive data into the target speaker's voice. In the conversion process, we apply a fundamental frequency (F0) matching technique to mitigate tonal variances between speakers with significant timbral differences. A style classifier filter is proposed to select the most expressive output audios for the TTS training. Our approach is comparable to state-of-the-art with only a few minutes of neutral data from the target speaker, while other methods require hours. A perceptual assessment showed improvements brought by the SVC and the style filter in naturalness and style intensity for the styles that display more vocal effort. Also, increased speaker similarity is obtained with the proposed F0 matching algorithm.