 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring synthetic data for cross-speaker style transfer in style representation based TTS
Paper and Code
Sep 25, 2024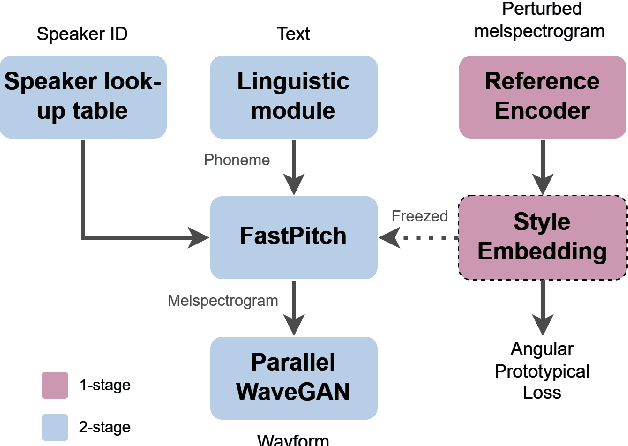
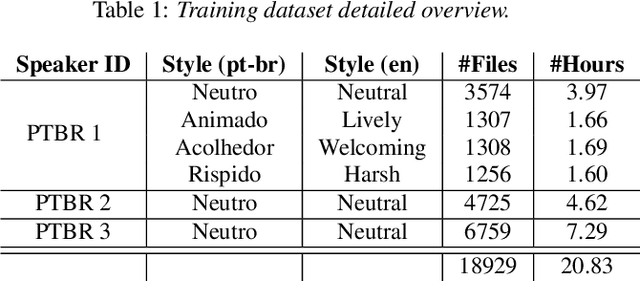
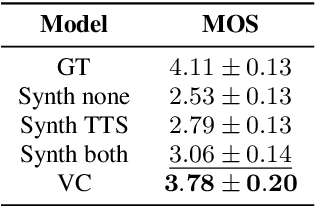
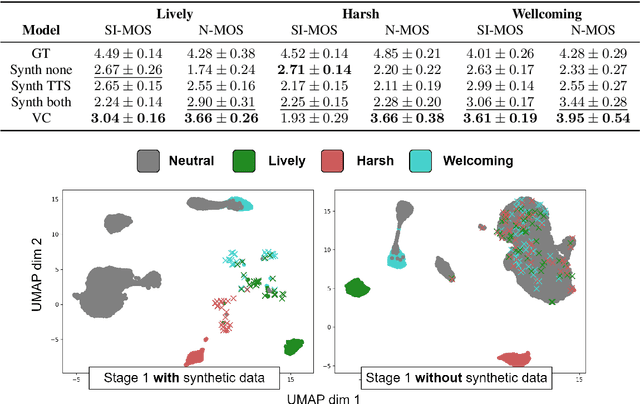
Incorporating cross-speaker style transfer in text-to-speech (TTS) models is challenging due to the need to disentangle speaker and style information in audio. In low-resource expressive data scenarios, voice conversion (VC) can generate expressive speech for target speakers, which can then be used to train the TTS model. However, the quality and style transfer ability of the VC model are crucial for the overall TTS model quality. In this work, we explore the use of synthetic data generated by a VC model to assist the TTS model in cross-speaker style transfer tasks. Additionally, we employ pre-training of the style encoder using timbre perturbation and prototypical angular loss to mitigate speaker leakage. Our results show that using VC synthetic data can improve the naturalness and speaker similarity of TTS in cross-speaker scenarios. Furthermore, we extend this approach to a cross-language scenario, enhancing accent transfer.