 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-decentralized Federated Time Series Prediction with Client Availability Budgets
Sep 03, 2025Federated learning (FL) effectively promotes collaborative training among distributed clients with privacy considerations in the Internet of Things (IoT) scenarios. Despite of data heterogeneity, FL clients may also be constrained by limited energy and availability budgets. Therefore, effective selection of clients participating in training is of vital importance for the convergence of the global model and the balance of client contributions. In this paper, we discuss the performance impact of client availability with time-series data on federated learning. We set up three different scenarios that affect the availability of time-series data and propose FedDeCAB, a novel, semi-decentralized client selection method applying probabilistic rankings of available clients. When a client is disconnected from the server, FedDeCAB allows obtaining partial model parameters from the nearest neighbor clients for joint optimization, improving the performance of offline models and reducing communication overhead. Experiments based on real-world large-scale taxi and vessel trajectory datasets show that FedDeCAB is effective under highly heterogeneous data distribution, limited communication budget, and dynamic client offline or rejoining.
FedVSR: Towards Model-Agnostic Federated Learning in Video Super-Resolution
Mar 17, 2025



Video Super-Resolution (VSR) reconstructs high-resolution videos from low-resolution inputs to restore fine details and improve visual clarity. While deep learning-based VSR methods achieve impressive results, their centralized nature raises serious privacy concerns, particularly in applications with strict privacy requirements. Federated Learning (FL) offers an alternative approach, but existing FL methods struggle with low-level vision tasks, leading to suboptimal reconstructions. To address this, we propose FedVSR1, a novel, architecture-independent, and stateless FL framework for VSR. Our approach introduces a lightweight loss term that improves local optimization and guides global aggregation with minimal computational overhead. To the best of our knowledge, this is the first attempt at federated VSR. Extensive experiments show that FedVSR outperforms general FL methods by an average of 0.85 dB in PSNR, highlighting its effectiveness. The code is available at: https://github.com/alimd94/FedVSR
Trustworthy and Responsible AI for Human-Centric Autonomous Decision-Making Systems
Sep 02, 2024Artificial Intelligence (AI) has paved the way for revolutionary decision-making processes, which if harnessed appropriately, can contribute to advancements in various sectors, from healthcare to economics. However, its black box nature presents significant ethical challenges related to bias and transparency. AI applications are hugely impacted by biases, presenting inconsistent and unreliable findings, leading to significant costs and consequences, highlighting and perpetuating inequalities and unequal access to resources. Hence, developing safe, reliable, ethical, and Trustworthy AI systems is essential. Our team of researchers working with Trustworthy and Responsible AI, part of the Transdisciplinary Scholarship Initiative within the University of Calgary, conducts research on Trustworthy and Responsible AI, including fairness, bias mitigation, reproducibility, generalization, interpretability, and authenticity. In this paper, we review and discuss the intricacies of AI biases, definitions, methods of detection and mitigation, and metrics for evaluating bias. We also discuss open challenges with regard to the trustworthiness and widespread application of AI across diverse domains of human-centric decision making, as well as guidelines to foster Responsible and Trustworthy AI models.
Enhancing Equitable Access to AI in Housing and Homelessness System of Care through Federated Learning
Aug 14, 2024



The top priority of a Housing and Homelessness System of Care (HHSC) is to connect people experiencing homelessness to supportive housing. An HHSC typically consists of many agencies serving the same population. Information technology platforms differ in type and quality between agencies, so their data are usually isolated from one agency to another. Larger agencies may have sufficient data to train and test artificial intelligence (AI) tools but smaller agencies typically do not. To address this gap, we introduce a Federated Learning (FL) approach enabling all agencies to train a predictive model collaboratively without sharing their sensitive data. We demonstrate how FL can be used within an HHSC to provide all agencies equitable access to quality AI and further assist human decision-makers in the allocation of resources within HHSC. This is achieved while preserving the privacy of the people within the data by not sharing identifying information between agencies without their consent. Our experimental results using real-world HHSC data from Calgary, Alberta, demonstrate that our FL approach offers comparable performance with the idealized scenario of training the predictive model with data fully shared and linked between agencies.
Navigating High-Degree Heterogeneity: Federated Learning in Aerial and Space Networks
Jun 25, 2024



Federated learning offers a compelling solution to the challenges of networking and data privacy within aerial and space networks by utilizing vast private edge data and computing capabilities accessible through drones, balloons, and satellites. While current research has focused on optimizing the learning process, computing efficiency, and minimizing communication overhead, the issue of heterogeneity and class imbalance remains a significant barrier to rapid model convergence. In our study, we explore the influence of heterogeneity on class imbalance, which diminishes performance in ASN-based federated learning. We illustrate the correlation between heterogeneity and class imbalance within grouped data and show how constraints such as battery life exacerbate the class imbalance challenge. Our findings indicate that ASN-based FL faces heightened class imbalance issues even with similar levels of heterogeneity compared to other scenarios. Finally, we analyze the impact of varying degrees of heterogeneity on FL training and evaluate the efficacy of current state-of-the-art algorithms under these conditions. Our results reveal that the heterogeneity challenge is more pronounced in ASN-based federated learning and that prevailing algorithms often fail to effectively address high levels of heterogeneity.
FedGreen: Carbon-aware Federated Learning with Model Size Adaptation
Apr 23, 2024



Federated learning (FL) provides a promising collaborative framework to build a model from distributed clients, and this work investigates the carbon emission of the FL process. Cloud and edge servers hosting FL clients may exhibit diverse carbon footprints influenced by their geographical locations with varying power sources, offering opportunities to reduce carbon emissions by training local models with adaptive computations and communications. In this paper, we propose FedGreen, a carbon-aware FL approach to efficiently train models by adopting adaptive model sizes shared with clients based on their carbon profiles and locations using ordered dropout as a model compression technique. We theoretically analyze the trade-offs between the produced carbon emissions and the convergence accuracy, considering the carbon intensity discrepancy across countries to choose the parameters optimally. Empirical studies show that FedGreen can substantially reduce the carbon footprints of FL compared to the state-of-the-art while maintaining competitive model accuracy.
WeiAvg: Federated Learning Model Aggregation Promoting Data Diversity
May 24, 2023



Federated learning provides a promising privacy-preserving way for utilizing large-scale private edge data from massive Internet-of-Things (IoT) devices. While existing research extensively studied optimizing the learning process, computing efficiency, and communication overhead, one important and often overlooked aspect is that participants contribute predictive knowledge from their data, impacting the quality of the federated models learned. While FedAvg treats each client equally and assigns weight solely based on the number of samples, the diversity of samples on each client could greatly affect the local update performance and the final aggregated model. In this paper, we propose a novel approach to address this issue by introducing a Weighted Averaging (WeiAvg) framework that emphasizes updates from high-diversity clients and diminishes the influence of those from low-diversity clients. Specifically, we introduced a projection-based approximation method to estimate the diversity of client data, instead of the computation of an entropy. We use the approximation because the locally computed entropy may not be transmitted due to excess privacy risk. Extensive experimental results show that WeiAvg converges faster and achieves higher accuracy than the original FedAvg algorithm and FedProx.
A Privacy-Preserving Hybrid Federated Learning Framework for Financial Crime Detection
Feb 23, 2023



The recent decade witnessed a surge of increase in financial crimes across the public and private sectors, with an average cost of scams of \$102m to financial institutions in 2022. Developing a mechanism for battling financial crimes is an impending task that requires in-depth collaboration from multiple institutions, and yet such collaboration imposed significant technical challenges due to the privacy and security requirements of distributed financial data. For example, consider the Society for Worldwide Interbank Financial Telecommunications (SWIFT) system, which generates 42 million transactions per day across its 11,000 global institutions. Training a detection model of fraudulent transactions requires not only secured SWIFT transactions but also the private account activities of those involved in each transaction from corresponding bank systems. The distributed nature of both samples and features prevents most existing learning systems from being directly adopted to handle the data mining task. In this paper, we collectively address these challenges by proposing a hybrid federated learning system that offers secure and privacy-aware learning and inference for financial crime detection. We conduct extensive empirical studies to evaluate the proposed framework's detection performance and privacy-protection capability, evaluating its robustness against common malicious attacks of collaborative learning. We release our source code at https://github.com/illidanlab/HyFL .
FedLE: Federated Learning Client Selection with Lifespan Extension for Edge IoT Networks
Feb 14, 2023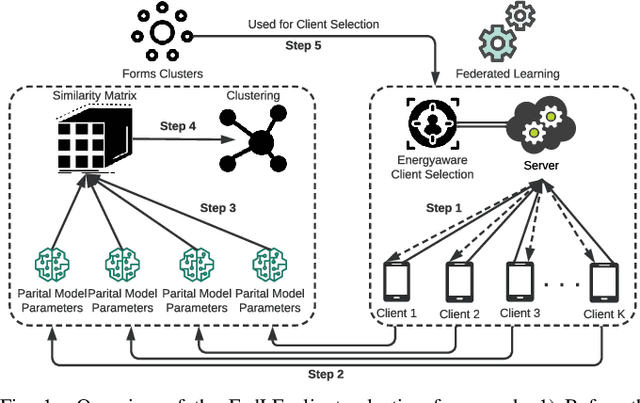
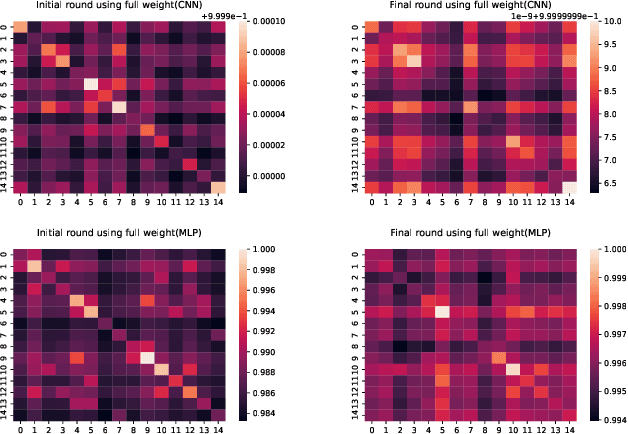
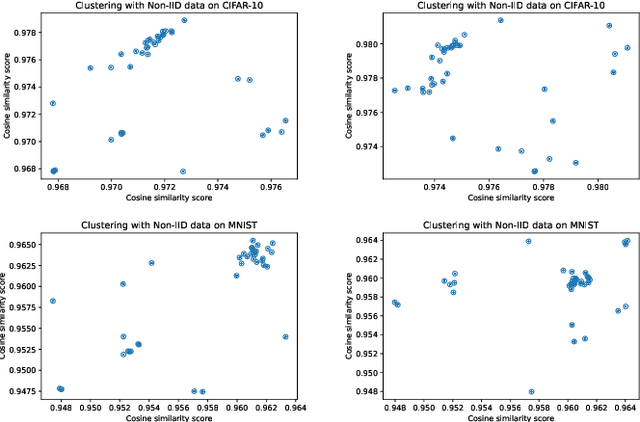
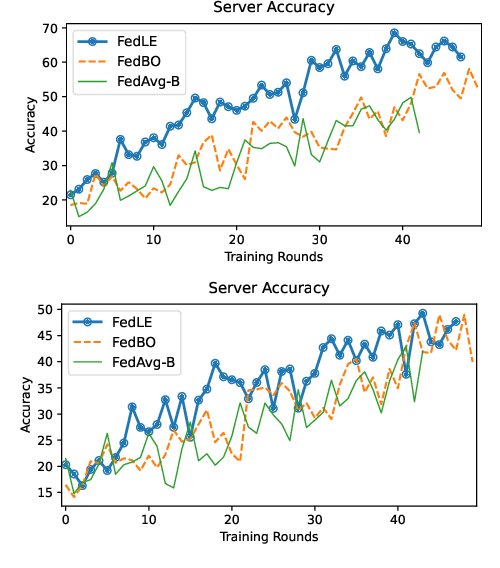
Federated learning (FL) is a distributed and privacy-preserving learning framework for predictive modeling with massive data generated at the edge by Internet of Things (IoT) devices. One major challenge preventing the wide adoption of FL in IoT is the pervasive power supply constraints of IoT devices due to the intensive energy consumption of battery-powered clients for local training and model updates. Low battery levels of clients eventually lead to their early dropouts from edge networks, loss of training data jeopardizing the performance of FL, and their availability to perform other designated tasks. In this paper, we propose FedLE, an energy-efficient client selection framework that enables lifespan extension of edge IoT networks. In FedLE, the clients first run for a minimum epoch to generate their local model update. The models are partially uploaded to the server for calculating similarities between each pair of clients. Clustering is performed against these client pairs to identify those with similar model distributions. In each round, low-powered clients have a lower probability of being selected, delaying the draining of their batteries. Empirical studies show that FedLE outperforms baselines on benchmark datasets and lasts more training rounds than FedAvg with battery power constraints.
Topology-aware Federated Learning in Edge Computing: A Comprehensive Survey
Feb 06, 2023



The ultra-low latency requirements of 5G/6G applications and privacy constraints call for distributed machine learning systems to be deployed at the edge. With its simple yet effective approach, federated learning (FL) is proved to be a natural solution for massive user-owned devices in edge computing with distributed and private training data. Most vanilla FL algorithms based on FedAvg follow a naive star topology, ignoring the heterogeneity and hierarchy of the volatile edge computing architectures and topologies in reality. In this paper, we conduct a comprehensive survey on the existing work of optimized FL models, frameworks, and algorithms with a focus on their network topologies. After a brief recap of FL and edge computing networks, we introduce various types of edge network topologies, along with the optimizations under the aforementioned network topologies. Lastly, we discuss the remaining challenges and future works for applying FL in topology-specific edge networks.