 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDA: Availability-Aware Federated Learning Client Selection
Nov 25, 2022Recently, a new distributed learning scheme called Federated Learning (FL) has been introduced. FL is designed so that server never collects user-owned data meaning it is great at preserving privacy. FL's process starts with the server sending a model to clients, then the clients train that model using their data and send the updated model back to the server. Afterward, the server aggregates all the updates and modifies the global model. This process is repeated until the model converges. This study focuses on an FL setting called cross-device FL, which trains based on a large number of clients. Since many devices may be unavailable in cross-device FL, and communication between the server and all clients is extremely costly, only a fraction of clients gets selected for training at each round. In vanilla FL, clients are selected randomly, which results in an acceptable accuracy but is not ideal from the overall training time perspective, since some clients are slow and can cause some training rounds to be slow. If only fast clients get selected the learning would speed up, but it will be biased toward only the fast clients' data, and the accuracy degrades. Consequently, new client selection techniques have been proposed to improve the training time by considering individual clients' resources and speed. This paper introduces the first availability-aware selection strategy called MDA. The results show that our approach makes learning faster than vanilla FL by up to 6.5%. Moreover, we show that resource heterogeneity-aware techniques are effective but can become even better when combined with our approach, making it faster than the state-of-the-art selectors by up to 16%. Lastly, our approach selects more unique clients for training compared to client selectors that only select fast clients, which reduces our technique's bias.
Towards Understanding Quality Challenges of the Federated Learning: A First Look from the Lens of Robustness
Jan 05, 2022
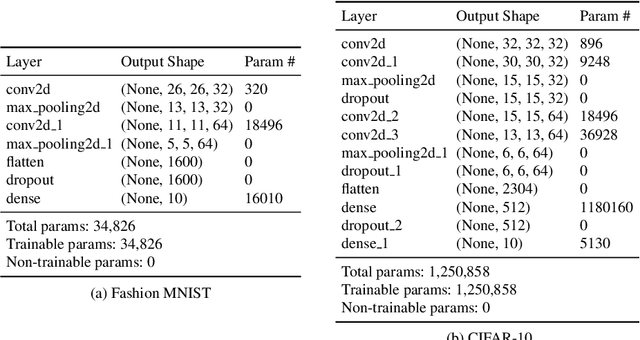
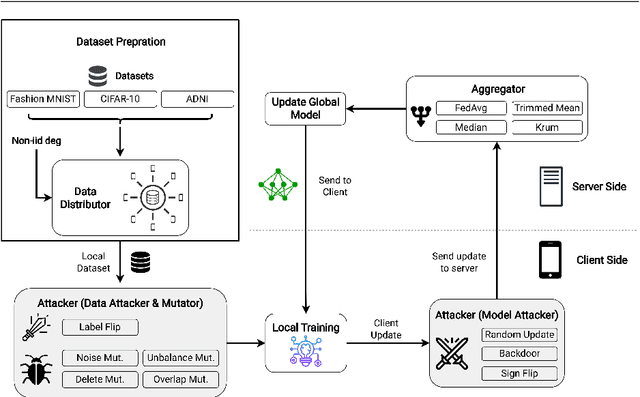
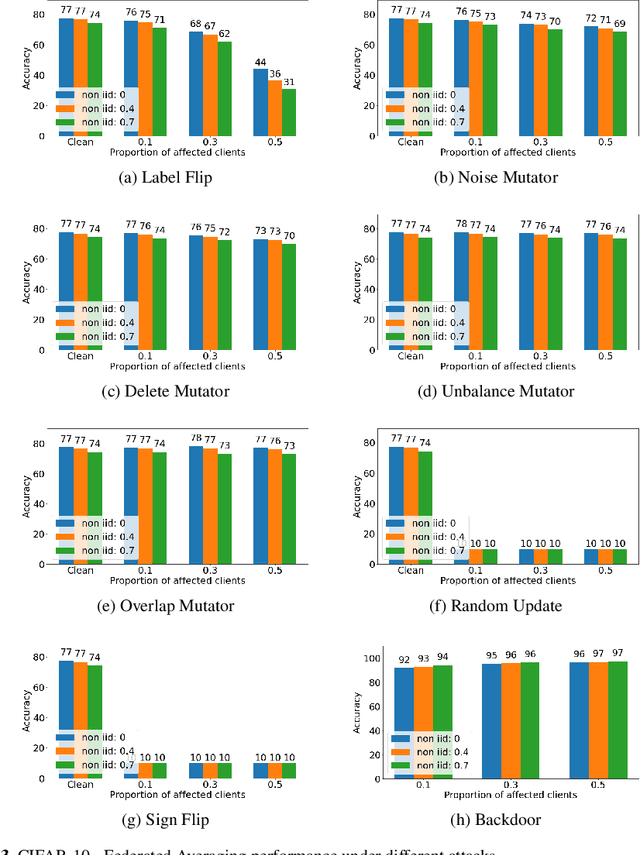
Federated learning (FL) is a widely adopted distributed learning paradigm in practice, which intends to preserve users' data privacy while leveraging the entire dataset of all participants for training. In FL, multiple models are trained independently on the users and aggregated centrally to update a global model in an iterative process. Although this approach is excellent at preserving privacy by design, FL still tends to suffer from quality issues such as attacks or byzantine faults. Some recent attempts have been made to address such quality challenges on the robust aggregation techniques for FL. However, the effectiveness of state-of-the-art (SOTA) robust FL techniques is still unclear and lacks a comprehensive study. Therefore, to better understand the current quality status and challenges of these SOTA FL techniques in the presence of attacks and faults, in this paper, we perform a large-scale empirical study to investigate the SOTA FL's quality from multiple angles of attacks, simulated faults (via mutation operators), and aggregation (defense) methods. In particular, we perform our study on two generic image datasets and one real-world federated medical image dataset. We also systematically investigate the effect of the distribution of attacks/faults over users and the independent and identically distributed (IID) factors, per dataset, on the robustness results. After a large-scale analysis with 496 configurations, we find that most mutators on each individual user have a negligible effect on the final model. Moreover, choosing the most robust FL aggregator depends on the attacks and datasets. Finally, we illustrate that it is possible to achieve a generic solution that works almost as well or even better than any single aggregator on all attacks and configurations with a simple ensemble model of aggregators.
Robustness Analysis of Deep Learning Frameworks on Mobile Platforms
Sep 20, 2021

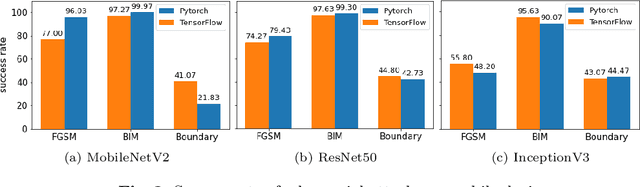
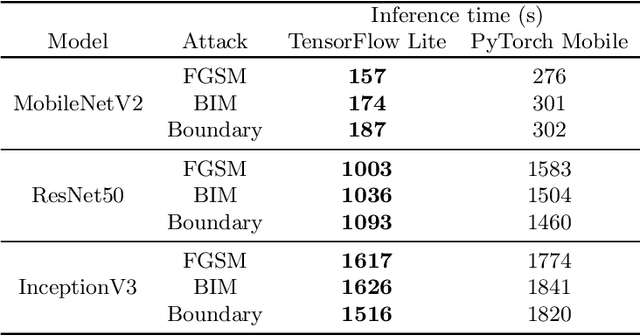
With the recent increase in the computational power of modern mobile devices, machine learning-based heavy tasks such as face detection and speech recognition are now integral parts of such devices. This requires frameworks to execute machine learning models (e.g., Deep Neural Networks) on mobile devices. Although there exist studies on the accuracy and performance of these frameworks, the quality of on-device deep learning frameworks, in terms of their robustness, has not been systematically studied yet. In this paper, we empirically compare two on-device deep learning frameworks with three adversarial attacks on three different model architectures. We also use both the quantized and unquantized variants for each architecture. The results show that, in general, neither of the deep learning frameworks is better than the other in terms of robustness, and there is not a significant difference between the PC and mobile frameworks either. However, in cases like Boundary attack, mobile version is more robust than PC. In addition, quantization improves robustness in all cases when moving from PC to mobile.