 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Equitable Access to AI in Housing and Homelessness System of Care through Federated Learning
Aug 14, 2024



The top priority of a Housing and Homelessness System of Care (HHSC) is to connect people experiencing homelessness to supportive housing. An HHSC typically consists of many agencies serving the same population. Information technology platforms differ in type and quality between agencies, so their data are usually isolated from one agency to another. Larger agencies may have sufficient data to train and test artificial intelligence (AI) tools but smaller agencies typically do not. To address this gap, we introduce a Federated Learning (FL) approach enabling all agencies to train a predictive model collaboratively without sharing their sensitive data. We demonstrate how FL can be used within an HHSC to provide all agencies equitable access to quality AI and further assist human decision-makers in the allocation of resources within HHSC. This is achieved while preserving the privacy of the people within the data by not sharing identifying information between agencies without their consent. Our experimental results using real-world HHSC data from Calgary, Alberta, demonstrate that our FL approach offers comparable performance with the idealized scenario of training the predictive model with data fully shared and linked between agencies.
Efficient Observation Time Window Segmentation for Administrative Data Machine Learning
Jan 29, 2024
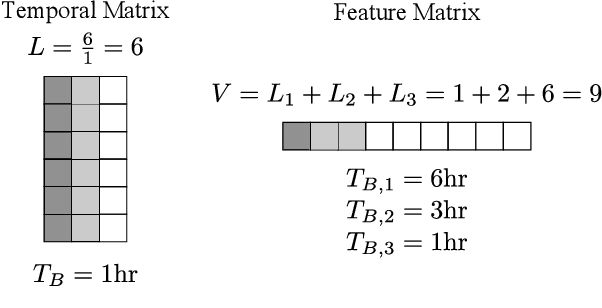

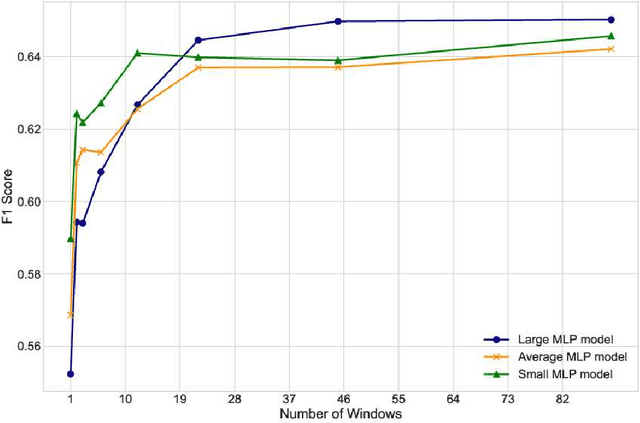
Utilizing administrative data to predict outcomes is an important application area of machine learning, particularly in healthcare. Most administrative data records are timestamped and the pattern of records over time is a key input for machine learning models. This paper explores how best to divide the observation window of a machine learning model into time segments or "bins". A computationally efficient process is presented that identifies which data features benefit most from smaller, higher resolution time segments. Results generated on healthcare and housing/homelessness administrative data demonstrate that optimizing the time bin size of these high priority features while using a single time bin for the other features achieves machine learning models that are simpler and quicker to train. This approach also achieves similar and sometimes better performance than more complex models that default to representing all data features with the same time resolution.