 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalization for Scalable Short-term Load Forecasting
Jul 15, 2025Forecasting load in power transmission networks is essential across various hierarchical levels, from the system level down to individual points of delivery (PoD). While intuitive and locally accurate, traditional local forecasting models (LFMs) face significant limitations, particularly in handling generalizability, overfitting, data drift, and the cold start problem. These methods also struggle with scalability, becoming computationally expensive and less efficient as the network's size and data volume grow. In contrast, global forecasting models (GFMs) offer a new approach to enhance prediction generalizability, scalability, accuracy, and robustness through globalization and cross-learning. This paper investigates global load forecasting in the presence of data drifts, highlighting the impact of different modeling techniques and data heterogeneity. We explore feature-transforming and target-transforming models, demonstrating how globalization, data heterogeneity, and data drift affect each differently. In addition, we examine the role of globalization in peak load forecasting and its potential for hierarchical forecasting. To address data heterogeneity and the balance between globality and locality, we propose separate time series clustering (TSC) methods, introducing model-based TSC for feature-transforming models and new weighted instance-based TSC for target-transforming models. Through extensive experiments on a real-world dataset of Alberta's electricity load, we demonstrate that global target-transforming models consistently outperform their local counterparts, especially when enriched with global features and clustering techniques. In contrast, global feature-transforming models face challenges in balancing local and global dynamics, often requiring TSC to manage data heterogeneity effectively.
Unifying Tree-Reweighted Belief Propagation and Mean Field for Tracking Extended Targets
Dec 26, 2024This paper proposes a unified tree-reweighted belief propagation (BP) and mean field (MF) approach for scalable detection and tracking of extended targets within the framework of factor graph. The factor graph is partitioned into a BP region and an MF region so that the messages in each region are updated according to the corresponding region rules. The BP region exploits the tree-reweighted BP, which offers improved convergence than the standard BP for graphs with massive cycles, to resolve data association. The MF region approximates the posterior densities of the measurement rate, kinematic state and extent. For linear Gaussian target models and gamma Gaussian inverse Wishart distributed state density, the unified approach provides a closed-form recursion for the state density. Hence, the proposed algorithm is more efficient than particle-based BP algorithms for extended target tracking. This method also avoids measurement clustering and gating since it solves the data association problem in a probabilistic fashion. We compare the proposed approach with algorithms such as the Poisson multi-Bernoulli mixture filter and the BP-based Poisson multi-Bernoulli filter. Simulation results demonstrate that the proposed algorithm achieves enhanced tracking performance.
LoRaWAN Based Dynamic Noise Mapping with Machine Learning for Urban Noise Enforcement
Jul 30, 2024Static noise maps depicting long-term noise levels over wide areas are valuable urban planning assets for municipalities in decreasing noise exposure of residents. However, non-traffic noise sources with transient behavior, which people complain frequently, are usually ignored by static maps. We propose here a dynamic noise mapping approach using the data collected via low-power wide-area network (LPWAN, specifically LoRaWAN) based internet of things (IoT) infrastructure, which is one of the most common communication backbones for smart cities. Noise mapping based on LPWAN is challenging due to the low data rates of these protocols. The proposed dynamic noise mapping approach diminishes the negative implications of data rate limitations using machine learning (ML) for event and location prediction of non-traffic sources based on the scarce data. The strength of these models lies in their consideration of the spatial variance in acoustic behavior caused by the buildings in urban settings. The effectiveness of the proposed method and the accuracy of the resulting dynamic maps are evaluated in field tests. The results show that the proposed system can decrease the map error caused by non-traffic sources up to 51% and can stay effective under significant packet losses.
Navigating High-Degree Heterogeneity: Federated Learning in Aerial and Space Networks
Jun 25, 2024



Federated learning offers a compelling solution to the challenges of networking and data privacy within aerial and space networks by utilizing vast private edge data and computing capabilities accessible through drones, balloons, and satellites. While current research has focused on optimizing the learning process, computing efficiency, and minimizing communication overhead, the issue of heterogeneity and class imbalance remains a significant barrier to rapid model convergence. In our study, we explore the influence of heterogeneity on class imbalance, which diminishes performance in ASN-based federated learning. We illustrate the correlation between heterogeneity and class imbalance within grouped data and show how constraints such as battery life exacerbate the class imbalance challenge. Our findings indicate that ASN-based FL faces heightened class imbalance issues even with similar levels of heterogeneity compared to other scenarios. Finally, we analyze the impact of varying degrees of heterogeneity on FL training and evaluate the efficacy of current state-of-the-art algorithms under these conditions. Our results reveal that the heterogeneity challenge is more pronounced in ASN-based federated learning and that prevailing algorithms often fail to effectively address high levels of heterogeneity.
FedGreen: Carbon-aware Federated Learning with Model Size Adaptation
Apr 23, 2024



Federated learning (FL) provides a promising collaborative framework to build a model from distributed clients, and this work investigates the carbon emission of the FL process. Cloud and edge servers hosting FL clients may exhibit diverse carbon footprints influenced by their geographical locations with varying power sources, offering opportunities to reduce carbon emissions by training local models with adaptive computations and communications. In this paper, we propose FedGreen, a carbon-aware FL approach to efficiently train models by adopting adaptive model sizes shared with clients based on their carbon profiles and locations using ordered dropout as a model compression technique. We theoretically analyze the trade-offs between the produced carbon emissions and the convergence accuracy, considering the carbon intensity discrepancy across countries to choose the parameters optimally. Empirical studies show that FedGreen can substantially reduce the carbon footprints of FL compared to the state-of-the-art while maintaining competitive model accuracy.
WeiAvg: Federated Learning Model Aggregation Promoting Data Diversity
May 24, 2023



Federated learning provides a promising privacy-preserving way for utilizing large-scale private edge data from massive Internet-of-Things (IoT) devices. While existing research extensively studied optimizing the learning process, computing efficiency, and communication overhead, one important and often overlooked aspect is that participants contribute predictive knowledge from their data, impacting the quality of the federated models learned. While FedAvg treats each client equally and assigns weight solely based on the number of samples, the diversity of samples on each client could greatly affect the local update performance and the final aggregated model. In this paper, we propose a novel approach to address this issue by introducing a Weighted Averaging (WeiAvg) framework that emphasizes updates from high-diversity clients and diminishes the influence of those from low-diversity clients. Specifically, we introduced a projection-based approximation method to estimate the diversity of client data, instead of the computation of an entropy. We use the approximation because the locally computed entropy may not be transmitted due to excess privacy risk. Extensive experimental results show that WeiAvg converges faster and achieves higher accuracy than the original FedAvg algorithm and FedProx.
Ghost-free High Dynamic Range Imaging via Hybrid CNN-Transformer and Structure Tensor
Dec 01, 2022Eliminating ghosting artifacts due to moving objects is a challenging problem in high dynamic range (HDR) imaging. In this letter, we present a hybrid model consisting of a convolutional encoder and a Transformer decoder to generate ghost-free HDR images. In the encoder, a context aggregation network and non-local attention block are adopted to optimize multi-scale features and capture both global and local dependencies of multiple low dynamic range (LDR) images. The decoder based on Swin Transformer is utilized to improve the reconstruction capability of the proposed model. Motivated by the phenomenal difference between the presence and absence of artifacts under the field of structure tensor (ST), we integrate the ST information of LDR images as auxiliary inputs of the network and use ST loss to further constrain artifacts. Different from previous approaches, our network is capable of processing an arbitrary number of input LDR images. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed method by comparing it with existing state-of-the-art HDR deghosting models. Codes are available at https://github.com/pandayuanyu/HSTHdr.
Learning to Kindle the Starlight
Nov 16, 2022Capturing highly appreciated star field images is extremely challenging due to light pollution, the requirements of specialized hardware, and the high level of photographic skills needed. Deep learning-based techniques have achieved remarkable results in low-light image enhancement (LLIE) but have not been widely applied to star field image enhancement due to the lack of training data. To address this problem, we construct the first Star Field Image Enhancement Benchmark (SFIEB) that contains 355 real-shot and 854 semi-synthetic star field images, all having the corresponding reference images. Using the presented dataset, we propose the first star field image enhancement approach, namely StarDiffusion, based on conditional denoising diffusion probabilistic models (DDPM). We introduce dynamic stochastic corruptions to the inputs of conditional DDPM to improve the performance and generalization of the network on our small-scale dataset. Experiments show promising results of our method, which outperforms state-of-the-art low-light image enhancement algorithms. The dataset and codes will be open-sourced.
Multimodal Image Fusion based on Hybrid CNN-Transformer and Non-local Cross-modal Attention
Oct 18, 2022



The fusion of images taken by heterogeneous sensors helps to enrich the information and improve the quality of imaging. In this article, we present a hybrid model consisting of a convolutional encoder and a Transformer-based decoder to fuse multimodal images. In the encoder, a non-local cross-modal attention block is proposed to capture both local and global dependencies of multiple source images. A branch fusion module is designed to adaptively fuse the features of the two branches. We embed a Transformer module with linear complexity in the decoder to enhance the reconstruction capability of the proposed network. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed method by comparing it with existing state-of-the-art fusion models. The source code of our work is available at https://github.com/pandayuanyu/HCFusion.
A Hybrid Labeled Multi-Bernoulli Filter With Amplitude For Tracking Fluctuating Targets
Sep 19, 2022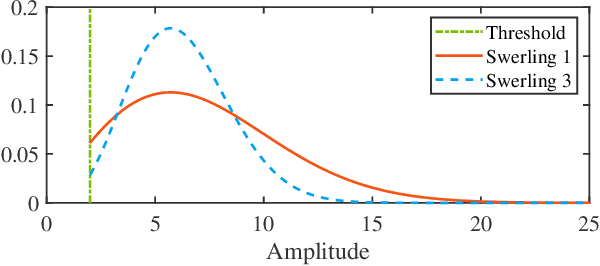
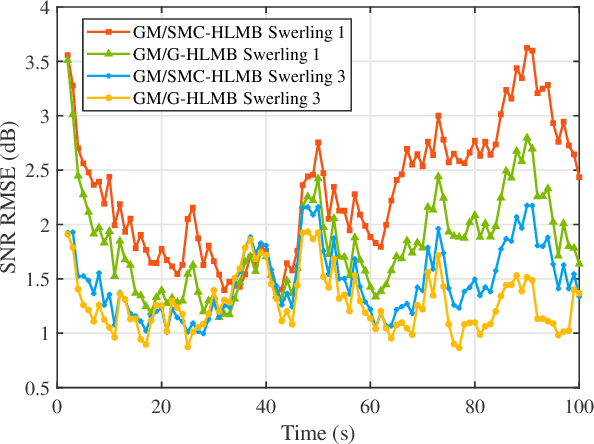
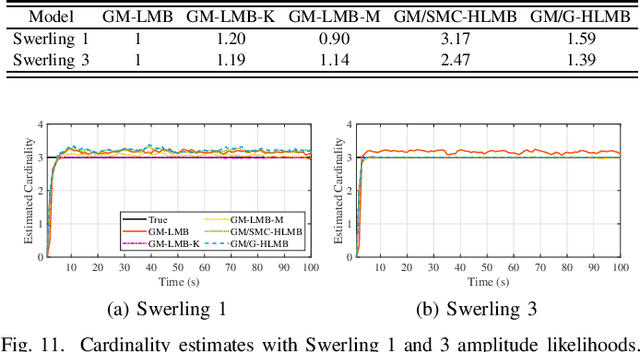

The amplitude information of target returns has been incorporated into many tracking algorithms for performance improvements. One of the limitations of employing amplitude feature is that the signal-to-noise ratio (SNR) of the target, i.e., the parameter of amplitude likelihood, is usually assumed to be known and constant. In practice, the target SNR is always unknown, and is dependent on aspect angle hence it will fluctuate. In this paper we propose a hybrid labeled multi-Bernoulli (LMB) filter that introduces the signal amplitude into the LMB filter for tracking targets with unknown and fluctuating SNR. The fluctuation of target SNR is modeled by an autoregressive gamma process and amplitude likelihoods for Swerling 1 and 3 targets are considered. Under Rao-Blackwell decomposition, an approximate Gamma estimator based on Laplace transform and Markov Chain Monte Carlo method is proposed to estimate the target SNR, and the kinematic state is estimated by a Gaussian mixture filter conditioned on the target SNR. The performance of the proposed hybrid filter is analyzed via a tracking scenario including three crossing targets. Simulation results verify the efficacy of the proposed SNR estimator and quantify the benefits of incorporating amplitude information for multi-target tracking.