 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Tree-Reweighted Belief Propagation and Mean Field for Tracking Extended Targets
Dec 26, 2024This paper proposes a unified tree-reweighted belief propagation (BP) and mean field (MF) approach for scalable detection and tracking of extended targets within the framework of factor graph. The factor graph is partitioned into a BP region and an MF region so that the messages in each region are updated according to the corresponding region rules. The BP region exploits the tree-reweighted BP, which offers improved convergence than the standard BP for graphs with massive cycles, to resolve data association. The MF region approximates the posterior densities of the measurement rate, kinematic state and extent. For linear Gaussian target models and gamma Gaussian inverse Wishart distributed state density, the unified approach provides a closed-form recursion for the state density. Hence, the proposed algorithm is more efficient than particle-based BP algorithms for extended target tracking. This method also avoids measurement clustering and gating since it solves the data association problem in a probabilistic fashion. We compare the proposed approach with algorithms such as the Poisson multi-Bernoulli mixture filter and the BP-based Poisson multi-Bernoulli filter. Simulation results demonstrate that the proposed algorithm achieves enhanced tracking performance.
Fast Personalized Text-to-Image Syntheses With Attention Injection
Mar 17, 2024Currently, personalized image generation methods mostly require considerable time to finetune and often overfit the concept resulting in generated images that are similar to custom concepts but difficult to edit by prompts. We propose an effective and fast approach that could balance the text-image consistency and identity consistency of the generated image and reference image. Our method can generate personalized images without any fine-tuning while maintaining the inherent text-to-image generation ability of diffusion models. Given a prompt and a reference image, we merge the custom concept into generated images by manipulating cross-attention and self-attention layers of the original diffusion model to generate personalized images that match the text description. Comprehensive experiments highlight the superiority of our method.
SSR-Encoder: Encoding Selective Subject Representation for Subject-Driven Generation
Dec 26, 2023



Recent advancements in subject-driven image generation have led to zero-shot generation, yet precise selection and focus on crucial subject representations remain challenging. Addressing this, we introduce the SSR-Encoder, a novel architecture designed for selectively capturing any subject from single or multiple reference images. It responds to various query modalities including text and masks, without necessitating test-time fine-tuning. The SSR-Encoder combines a Token-to-Patch Aligner that aligns query inputs with image patches and a Detail-Preserving Subject Encoder for extracting and preserving fine features of the subjects, thereby generating subject embeddings. These embeddings, used in conjunction with original text embeddings, condition the generation process. Characterized by its model generalizability and efficiency, the SSR-Encoder adapts to a range of custom models and control modules. Enhanced by the Embedding Consistency Regularization Loss for improved training, our extensive experiments demonstrate its effectiveness in versatile and high-quality image generation, indicating its broad applicability. Project page: https://ssr-encoder.github.io
CLIPVG: Text-Guided Image Manipulation Using Differentiable Vector Graphics
Dec 05, 2022



Considerable progress has recently been made in leveraging CLIP (Contrastive Language-Image Pre-Training) models for text-guided image manipulation. However, all existing works rely on additional generative models to ensure the quality of results, because CLIP alone cannot provide enough guidance information for fine-scale pixel-level changes. In this paper, we introduce CLIPVG, a text-guided image manipulation framework using differentiable vector graphics, which is also the first CLIP-based general image manipulation framework that does not require any additional generative models. We demonstrate that CLIPVG can not only achieve state-of-art performance in both semantic correctness and synthesis quality, but also is flexible enough to support various applications far beyond the capability of all existing methods.
Ghost-free High Dynamic Range Imaging via Hybrid CNN-Transformer and Structure Tensor
Dec 01, 2022Eliminating ghosting artifacts due to moving objects is a challenging problem in high dynamic range (HDR) imaging. In this letter, we present a hybrid model consisting of a convolutional encoder and a Transformer decoder to generate ghost-free HDR images. In the encoder, a context aggregation network and non-local attention block are adopted to optimize multi-scale features and capture both global and local dependencies of multiple low dynamic range (LDR) images. The decoder based on Swin Transformer is utilized to improve the reconstruction capability of the proposed model. Motivated by the phenomenal difference between the presence and absence of artifacts under the field of structure tensor (ST), we integrate the ST information of LDR images as auxiliary inputs of the network and use ST loss to further constrain artifacts. Different from previous approaches, our network is capable of processing an arbitrary number of input LDR images. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed method by comparing it with existing state-of-the-art HDR deghosting models. Codes are available at https://github.com/pandayuanyu/HSTHdr.
Learning to Kindle the Starlight
Nov 16, 2022Capturing highly appreciated star field images is extremely challenging due to light pollution, the requirements of specialized hardware, and the high level of photographic skills needed. Deep learning-based techniques have achieved remarkable results in low-light image enhancement (LLIE) but have not been widely applied to star field image enhancement due to the lack of training data. To address this problem, we construct the first Star Field Image Enhancement Benchmark (SFIEB) that contains 355 real-shot and 854 semi-synthetic star field images, all having the corresponding reference images. Using the presented dataset, we propose the first star field image enhancement approach, namely StarDiffusion, based on conditional denoising diffusion probabilistic models (DDPM). We introduce dynamic stochastic corruptions to the inputs of conditional DDPM to improve the performance and generalization of the network on our small-scale dataset. Experiments show promising results of our method, which outperforms state-of-the-art low-light image enhancement algorithms. The dataset and codes will be open-sourced.
Multimodal Image Fusion based on Hybrid CNN-Transformer and Non-local Cross-modal Attention
Oct 18, 2022



The fusion of images taken by heterogeneous sensors helps to enrich the information and improve the quality of imaging. In this article, we present a hybrid model consisting of a convolutional encoder and a Transformer-based decoder to fuse multimodal images. In the encoder, a non-local cross-modal attention block is proposed to capture both local and global dependencies of multiple source images. A branch fusion module is designed to adaptively fuse the features of the two branches. We embed a Transformer module with linear complexity in the decoder to enhance the reconstruction capability of the proposed network. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed method by comparing it with existing state-of-the-art fusion models. The source code of our work is available at https://github.com/pandayuanyu/HCFusion.
A Hybrid Labeled Multi-Bernoulli Filter With Amplitude For Tracking Fluctuating Targets
Sep 19, 2022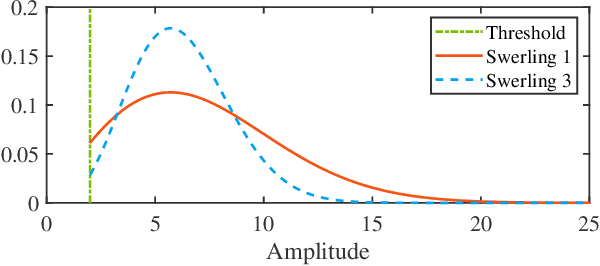
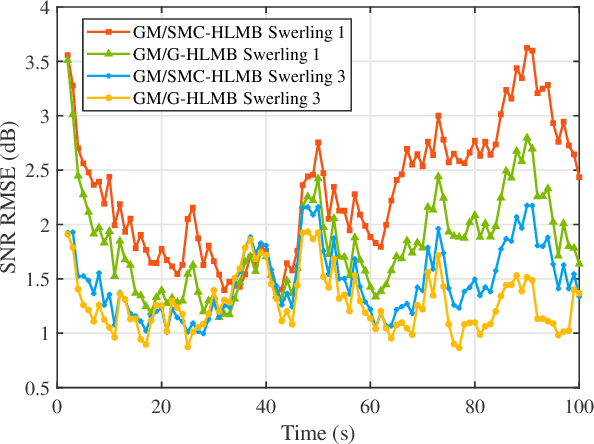
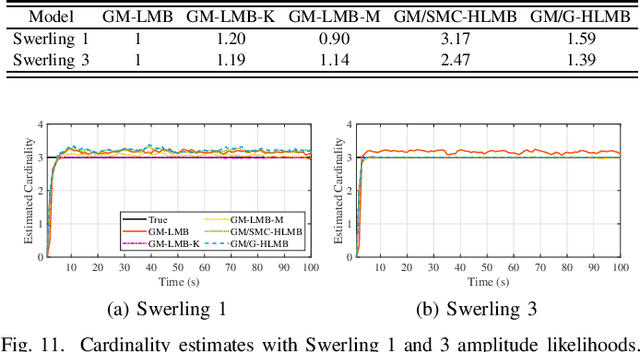

The amplitude information of target returns has been incorporated into many tracking algorithms for performance improvements. One of the limitations of employing amplitude feature is that the signal-to-noise ratio (SNR) of the target, i.e., the parameter of amplitude likelihood, is usually assumed to be known and constant. In practice, the target SNR is always unknown, and is dependent on aspect angle hence it will fluctuate. In this paper we propose a hybrid labeled multi-Bernoulli (LMB) filter that introduces the signal amplitude into the LMB filter for tracking targets with unknown and fluctuating SNR. The fluctuation of target SNR is modeled by an autoregressive gamma process and amplitude likelihoods for Swerling 1 and 3 targets are considered. Under Rao-Blackwell decomposition, an approximate Gamma estimator based on Laplace transform and Markov Chain Monte Carlo method is proposed to estimate the target SNR, and the kinematic state is estimated by a Gaussian mixture filter conditioned on the target SNR. The performance of the proposed hybrid filter is analyzed via a tracking scenario including three crossing targets. Simulation results verify the efficacy of the proposed SNR estimator and quantify the benefits of incorporating amplitude information for multi-target tracking.
Self-Adaptive Partial Domain Adaptation
Sep 18, 2021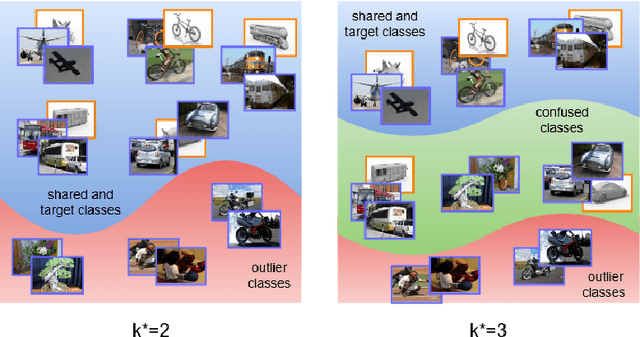
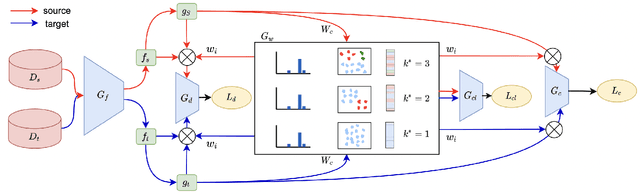
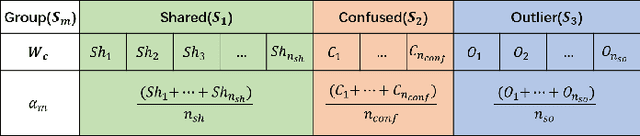

Partial Domain adaptation (PDA) aims to solve a more practical cross-domain learning problem that assumes target label space is a subset of source label space. However, the mismatched label space causes significant negative transfer. A traditional solution is using soft weights to increase weights of source shared domain and reduce those of source outlier domain. But it still learns features of outliers and leads to negative immigration. The other mainstream idea is to distinguish source domain into shared and outlier parts by hard binary weights, while it is unavailable to correct the tangled shared and outlier classes. In this paper, we propose an end-to-end Self-Adaptive Partial Domain Adaptation(SAPDA) Network. Class weights evaluation mechanism is introduced to dynamically self-rectify the weights of shared, outlier and confused classes, thus the higher confidence samples have the more sufficient weights. Meanwhile it can eliminate the negative transfer caused by the mismatching of label space greatly. Moreover, our strategy can efficiently measure the transferability of samples in a broader sense, so that our method can achieve competitive results on unsupervised DA task likewise. A large number of experiments on multiple benchmarks have demonstrated the effectiveness of our SAPDA.
Domain Adaptive YOLO for One-Stage Cross-Domain Detection
Jul 04, 2021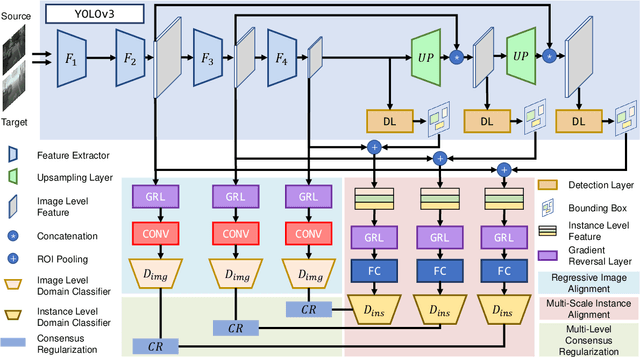



Domain shift is a major challenge for object detectors to generalize well to real world applications. Emerging techniques of domain adaptation for two-stage detectors help to tackle this problem. However, two-stage detectors are not the first choice for industrial applications due to its long time consumption. In this paper, a novel Domain Adaptive YOLO (DA-YOLO) is proposed to improve cross-domain performance for one-stage detectors. Image level features alignment is used to strictly match for local features like texture, and loosely match for global features like illumination. Multi-scale instance level features alignment is presented to reduce instance domain shift effectively , such as variations in object appearance and viewpoint. A consensus regularization to these domain classifiers is employed to help the network generate domain-invariant detections. We evaluate our proposed method on popular datasets like Cityscapes, KITTI, SIM10K and etc.. The results demonstrate significant improvement when tested under different cross-domain scenarios.