 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal expressive personality recognition in data non-ideal audiovisual based on multi-scale feature enhancement and modal augment
Mar 08, 2025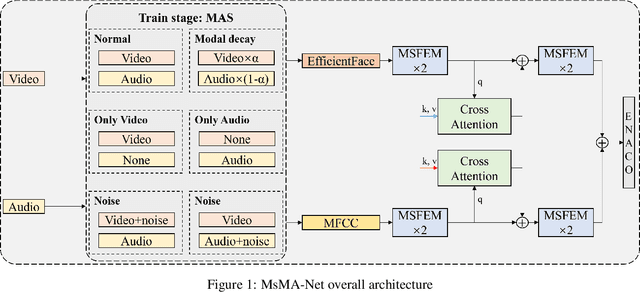

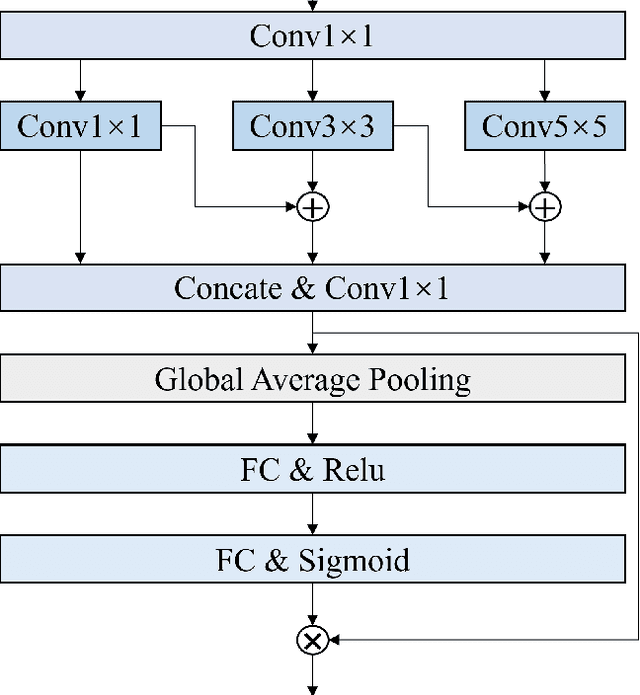

Automatic personality recognition is a research hotspot in the intersection of computer science and psychology, and in human-computer interaction, personalised has a wide range of applications services and other scenarios. In this paper, an end-to-end multimodal performance personality is established for both visual and auditory modal datarecognition network , and the through feature-level fusion , which effectively of the two modalities is carried out the cross-attention mechanismfuses the features of the two modal data; and a is proposed multiscale feature enhancement modalitiesmodule , which enhances for visual and auditory boththe expression of the information of effective the features and suppresses the interference of the redundant information. In addition, during the training process, this paper proposes a modal enhancement training strategy to simulate non-ideal such as modal loss and noise interferencedata situations , which enhances the adaptability ofand the model to non-ideal data scenarios improves the robustness of the model. Experimental results show that the method proposed in this paper is able to achieve an average Big Five personality accuracy of , which outperforms existing 0.916 on the personality analysis dataset ChaLearn First Impressionother methods based on audiovisual and audio-visual both modalities. The ablation experiments also validate our proposed , respectivelythe contribution of module and modality enhancement strategy to the model performance. Finally, we simulate in the inference phase multi-scale feature enhancement six non-ideal data scenarios to verify the modal enhancement strategy's improvement in model robustness.
GeoFormer: Learning Point Cloud Completion with Tri-Plane Integrated Transformer
Aug 13, 2024



Point cloud completion aims to recover accurate global geometry and preserve fine-grained local details from partial point clouds. Conventional methods typically predict unseen points directly from 3D point cloud coordinates or use self-projected multi-view depth maps to ease this task. However, these gray-scale depth maps cannot reach multi-view consistency, consequently restricting the performance. In this paper, we introduce a GeoFormer that simultaneously enhances the global geometric structure of the points and improves the local details. Specifically, we design a CCM Feature Enhanced Point Generator to integrate image features from multi-view consistent canonical coordinate maps (CCMs) and align them with pure point features, thereby enhancing the global geometry feature. Additionally, we employ the Multi-scale Geometry-aware Upsampler module to progressively enhance local details. This is achieved through cross attention between the multi-scale features extracted from the partial input and the features derived from previously estimated points. Extensive experiments on the PCN, ShapeNet-55/34, and KITTI benchmarks demonstrate that our GeoFormer outperforms recent methods, achieving the state-of-the-art performance. Our code is available at \href{https://github.com/Jinpeng-Yu/GeoFormer}{https://github.com/Jinpeng-Yu/GeoFormer}.
Fast Personalized Text-to-Image Syntheses With Attention Injection
Mar 17, 2024Currently, personalized image generation methods mostly require considerable time to finetune and often overfit the concept resulting in generated images that are similar to custom concepts but difficult to edit by prompts. We propose an effective and fast approach that could balance the text-image consistency and identity consistency of the generated image and reference image. Our method can generate personalized images without any fine-tuning while maintaining the inherent text-to-image generation ability of diffusion models. Given a prompt and a reference image, we merge the custom concept into generated images by manipulating cross-attention and self-attention layers of the original diffusion model to generate personalized images that match the text description. Comprehensive experiments highlight the superiority of our method.
SSR-Encoder: Encoding Selective Subject Representation for Subject-Driven Generation
Dec 26, 2023



Recent advancements in subject-driven image generation have led to zero-shot generation, yet precise selection and focus on crucial subject representations remain challenging. Addressing this, we introduce the SSR-Encoder, a novel architecture designed for selectively capturing any subject from single or multiple reference images. It responds to various query modalities including text and masks, without necessitating test-time fine-tuning. The SSR-Encoder combines a Token-to-Patch Aligner that aligns query inputs with image patches and a Detail-Preserving Subject Encoder for extracting and preserving fine features of the subjects, thereby generating subject embeddings. These embeddings, used in conjunction with original text embeddings, condition the generation process. Characterized by its model generalizability and efficiency, the SSR-Encoder adapts to a range of custom models and control modules. Enhanced by the Embedding Consistency Regularization Loss for improved training, our extensive experiments demonstrate its effectiveness in versatile and high-quality image generation, indicating its broad applicability. Project page: https://ssr-encoder.github.io
P$^2$SDF for Neural Indoor Scene Reconstruction
Mar 01, 2023Given only a set of images, neural implicit surface representation has shown its capability in 3D surface reconstruction. However, as the nature of per-scene optimization is based on the volumetric rendering of color, previous neural implicit surface reconstruction methods usually fail in low-textured regions, including the floors, walls, etc., which commonly exist for indoor scenes. Being aware of the fact that these low-textured regions usually correspond to planes, without introducing additional ground-truth supervisory signals or making additional assumptions about the room layout, we propose to leverage a novel Pseudo Plane-regularized Signed Distance Field (P$^2$SDF) for indoor scene reconstruction. Specifically, we consider adjacent pixels with similar colors to be on the same pseudo planes. The plane parameters are then estimated on the fly during training by an efficient and effective two-step scheme. Then the signed distances of the points on the planes are regularized by the estimated plane parameters in the training phase. As the unsupervised plane segments are usually noisy and inaccurate, we propose to assign different weights to the sampled points on the plane in plane estimation as well as the regularization loss. The weights come by fusing the plane segments from different views. As the sampled rays in the planar regions are redundant, leading to inefficient training, we further propose a keypoint-guided rays sampling strategy that attends to the informative textured regions with large color variations, and the implicit network gets a better reconstruction, compared with the original uniform ray sampling strategy. Experiments show that our P$^2$SDF achieves competitive reconstruction performance in Manhattan scenes. Further, as we do not introduce any additional room layout assumption, our P$^2$SDF generalizes well to the reconstruction of non-Manhattan scenes.