 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccFace: Unified Occlusion-Aware Facial Landmark Detection with Per-Point Visibility
Feb 11, 2026Accurate facial landmark detection under occlusion remains challenging, especially for human-like faces with large appearance variation and rotation-driven self-occlusion. Existing detectors typically localize landmarks while handling occlusion implicitly, without predicting per-point visibility that downstream applications can benefits. We present OccFace, an occlusion-aware framework for universal human-like faces, including humans, stylized characters, and other non-human designs. OccFace adopts a unified dense 100-point layout and a heatmap-based backbone, and adds an occlusion module that jointly predicts landmark coordinates and per-point visibility by combining local evidence with cross-landmark context. Visibility supervision mixes manual labels with landmark-aware masking that derives pseudo visibility from mask-heatmap overlap. We also create an occlusion-aware evaluation suite reporting NME on visible vs. occluded landmarks and benchmarking visibility with Occ AP, F1@0.5, and ROC-AUC, together with a dataset annotated with 100-point landmarks and per-point visibility. Experiments show improved robustness under external occlusion and large head rotations, especially on occluded regions, while preserving accuracy on visible landmarks.
PAPI-Reg: Patch-to-Pixel Solution for Efficient Cross-Modal Registration between LiDAR Point Cloud and Camera Image
Mar 19, 2025The primary requirement for cross-modal data fusion is the precise alignment of data from different sensors. However, the calibration between LiDAR point clouds and camera images is typically time-consuming and needs external calibration board or specific environmental features. Cross-modal registration effectively solves this problem by aligning the data directly without requiring external calibration. However, due to the domain gap between the point cloud and the image, existing methods rarely achieve satisfactory registration accuracy while maintaining real-time performance. To address this issue, we propose a framework that projects point clouds into several 2D representations for matching with camera images, which not only leverages the geometric characteristic of LiDAR point clouds more effectively but also bridge the domain gap between the point cloud and image. Moreover, to tackle the challenges of cross modal differences and the limited overlap between LiDAR point clouds and images in the image matching task, we introduce a multi-scale feature extraction network to effectively extract features from both camera images and the projection maps of LiDAR point cloud. Additionally, we propose a patch-to-pixel matching network to provide more effective supervision and achieve higher accuracy. We validate the performance of our model through experiments on the KITTI and nuScenes datasets. Our network achieves real-time performance and extremely high registration accuracy. On the KITTI dataset, our model achieves a registration accuracy rate of over 99\%.
Feature Compression for Cloud-Edge Multimodal 3D Object Detection
Sep 06, 2024



Machine vision systems, which can efficiently manage extensive visual perception tasks, are becoming increasingly popular in industrial production and daily life. Due to the challenge of simultaneously obtaining accurate depth and texture information with a single sensor, multimodal data captured by cameras and LiDAR is commonly used to enhance performance. Additionally, cloud-edge cooperation has emerged as a novel computing approach to improve user experience and ensure data security in machine vision systems. This paper proposes a pioneering solution to address the feature compression problem in multimodal 3D object detection. Given a sparse tensor-based object detection network at the edge device, we introduce two modes to accommodate different application requirements: Transmission-Friendly Feature Compression (T-FFC) and Accuracy-Friendly Feature Compression (A-FFC). In T-FFC mode, only the output of the last layer of the network's backbone is transmitted from the edge device. The received feature is processed at the cloud device through a channel expansion module and two spatial upsampling modules to generate multi-scale features. In A-FFC mode, we expand upon the T-FFC mode by transmitting two additional types of features. These added features enable the cloud device to generate more accurate multi-scale features. Experimental results on the KITTI dataset using the VirConv-L detection network showed that T-FFC was able to compress the features by a factor of 6061 with less than a 3% reduction in detection performance. On the other hand, A-FFC compressed the features by a factor of about 901 with almost no degradation in detection performance. We also designed optional residual extraction and 3D object reconstruction modules to facilitate the reconstruction of detected objects. The reconstructed objects effectively reflected details of the original objects.
MeshSegmenter: Zero-Shot Mesh Semantic Segmentation via Texture Synthesis
Jul 18, 2024



We present MeshSegmenter, a simple yet effective framework designed for zero-shot 3D semantic segmentation. This model successfully extends the powerful capabilities of 2D segmentation models to 3D meshes, delivering accurate 3D segmentation across diverse meshes and segment descriptions. Specifically, our model leverages the Segment Anything Model (SAM) model to segment the target regions from images rendered from the 3D shape. In light of the importance of the texture for segmentation, we also leverage the pretrained stable diffusion model to generate images with textures from 3D shape, and leverage SAM to segment the target regions from images with textures. Textures supplement the shape for segmentation and facilitate accurate 3D segmentation even in geometrically non-prominent areas, such as segmenting a car door within a car mesh. To achieve the 3D segments, we render 2D images from different views and conduct segmentation for both textured and untextured images. Lastly, we develop a multi-view revoting scheme that integrates 2D segmentation results and confidence scores from various views onto the 3D mesh, ensuring the 3D consistency of segmentation results and eliminating inaccuracies from specific perspectives. Through these innovations, MeshSegmenter offers stable and reliable 3D segmentation results both quantitatively and qualitatively, highlighting its potential as a transformative tool in the field of 3D zero-shot segmentation. The code is available at \url{https://github.com/zimingzhong/MeshSegmenter}.
MLLM-Tool: A Multimodal Large Language Model For Tool Agent Learning
Jan 24, 2024



Recently, the astonishing performance of large language models (LLMs) in natural language comprehension and generation tasks triggered lots of exploration of using them as central controllers to build agent systems. Multiple studies focus on bridging the LLMs to external tools to extend the application scenarios. However, the current LLMs' perceiving tool-use ability is limited to a single text query, which may result in ambiguity in understanding the users' real intentions. LLMs are expected to eliminate that by perceiving the visual- or auditory-grounded instructions' information. Therefore, in this paper, we propose MLLM-Tool, a system incorporating open-source LLMs and multi-modal encoders so that the learnt LLMs can be conscious of multi-modal input instruction and then select the function-matched tool correctly. To facilitate the evaluation of the model's capability, we collect a dataset featured by consisting of multi-modal input tools from HuggingFace. Another important feature of our dataset is that our dataset also contains multiple potential choices for the same instruction due to the existence of identical functions and synonymous functions, which provides more potential solutions for the same query. The experiments reveal that our MLLM-Tool is capable of recommending appropriate tools for multi-modal instructions. Codes and data are available at https://github.com/MLLM-Tool/MLLM-Tool.
TSP-Transformer: Task-Specific Prompts Boosted Transformer for Holistic Scene Understanding
Nov 06, 2023Holistic scene understanding includes semantic segmentation, surface normal estimation, object boundary detection, depth estimation, etc. The key aspect of this problem is to learn representation effectively, as each subtask builds upon not only correlated but also distinct attributes. Inspired by visual-prompt tuning, we propose a Task-Specific Prompts Transformer, dubbed TSP-Transformer, for holistic scene understanding. It features a vanilla transformer in the early stage and tasks-specific prompts transformer encoder in the lateral stage, where tasks-specific prompts are augmented. By doing so, the transformer layer learns the generic information from the shared parts and is endowed with task-specific capacity. First, the tasks-specific prompts serve as induced priors for each task effectively. Moreover, the task-specific prompts can be seen as switches to favor task-specific representation learning for different tasks. Extensive experiments on NYUD-v2 and PASCAL-Context show that our method achieves state-of-the-art performance, validating the effectiveness of our method for holistic scene understanding. We also provide our code in the following link https://github.com/tb2-sy/TSP-Transformer.
P$^2$SDF for Neural Indoor Scene Reconstruction
Mar 01, 2023Given only a set of images, neural implicit surface representation has shown its capability in 3D surface reconstruction. However, as the nature of per-scene optimization is based on the volumetric rendering of color, previous neural implicit surface reconstruction methods usually fail in low-textured regions, including the floors, walls, etc., which commonly exist for indoor scenes. Being aware of the fact that these low-textured regions usually correspond to planes, without introducing additional ground-truth supervisory signals or making additional assumptions about the room layout, we propose to leverage a novel Pseudo Plane-regularized Signed Distance Field (P$^2$SDF) for indoor scene reconstruction. Specifically, we consider adjacent pixels with similar colors to be on the same pseudo planes. The plane parameters are then estimated on the fly during training by an efficient and effective two-step scheme. Then the signed distances of the points on the planes are regularized by the estimated plane parameters in the training phase. As the unsupervised plane segments are usually noisy and inaccurate, we propose to assign different weights to the sampled points on the plane in plane estimation as well as the regularization loss. The weights come by fusing the plane segments from different views. As the sampled rays in the planar regions are redundant, leading to inefficient training, we further propose a keypoint-guided rays sampling strategy that attends to the informative textured regions with large color variations, and the implicit network gets a better reconstruction, compared with the original uniform ray sampling strategy. Experiments show that our P$^2$SDF achieves competitive reconstruction performance in Manhattan scenes. Further, as we do not introduce any additional room layout assumption, our P$^2$SDF generalizes well to the reconstruction of non-Manhattan scenes.
TransRAC: Encoding Multi-scale Temporal Correlation with Transformers for Repetitive Action Counting
Apr 03, 2022


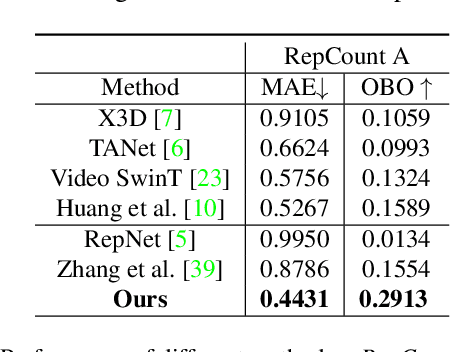
Counting repetitive actions are widely seen in human activities such as physical exercise. Existing methods focus on performing repetitive action counting in short videos, which is tough for dealing with longer videos in more realistic scenarios. In the data-driven era, the degradation of such generalization capability is mainly attributed to the lack of long video datasets. To complement this margin, we introduce a new large-scale repetitive action counting dataset covering a wide variety of video lengths, along with more realistic situations where action interruption or action inconsistencies occur in the video. Besides, we also provide a fine-grained annotation of the action cycles instead of just counting annotation along with a numerical value. Such a dataset contains 1,451 videos with about 20,000 annotations, which is more challenging. For repetitive action counting towards more realistic scenarios, we further propose encoding multi-scale temporal correlation with transformers that can take into account both performance and efficiency. Furthermore, with the help of fine-grained annotation of action cycles, we propose a density map regression-based method to predict the action period, which yields better performance with sufficient interpretability. Our proposed method outperforms state-of-the-art methods on all datasets and also achieves better performance on the unseen dataset without fine-tuning. The dataset and code are available.
Proxy-bridged Image Reconstruction Network for Anomaly Detection in Medical Images
Oct 05, 2021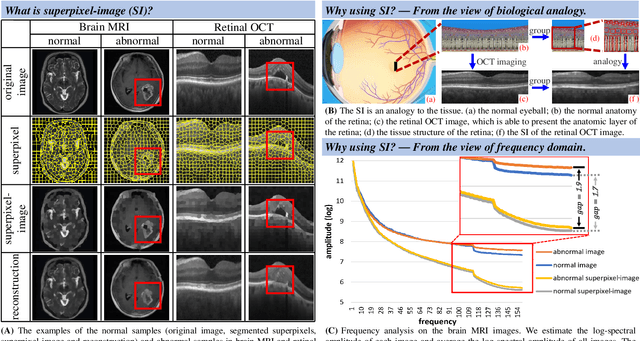
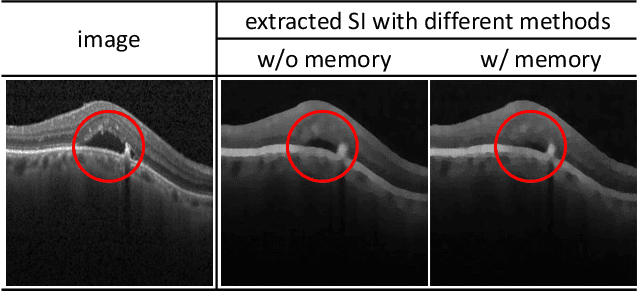
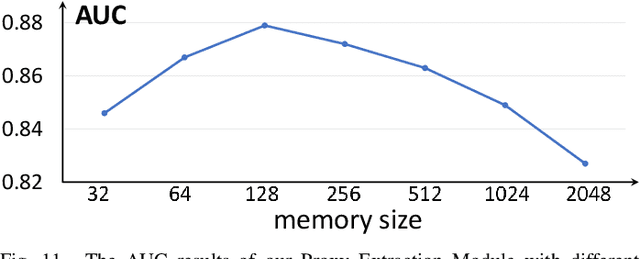
Anomaly detection in medical images refers to the identification of abnormal images with only normal images in the training set. Most existing methods solve this problem with a self-reconstruction framework, which tends to learn an identity mapping and reduces the sensitivity to anomalies. To mitigate this problem, in this paper, we propose a novel Proxy-bridged Image Reconstruction Network (ProxyAno) for anomaly detection in medical images. Specifically, we use an intermediate proxy to bridge the input image and the reconstructed image. We study different proxy types, and we find that the superpixel-image (SI) is the best one. We set all pixels' intensities within each superpixel as their average intensity, and denote this image as SI. The proposed ProxyAno consists of two modules, a Proxy Extraction Module and an Image Reconstruction Module. In the Proxy Extraction Module, a memory is introduced to memorize the feature correspondence for normal image to its corresponding SI, while the memorized correspondence does not apply to the abnormal images, which leads to the information loss for abnormal image and facilitates the anomaly detection. In the Image Reconstruction Module, we map an SI to its reconstructed image. Further, we crop a patch from the image and paste it on the normal SI to mimic the anomalies, and enforce the network to reconstruct the normal image even with the pseudo abnormal SI. In this way, our network enlarges the reconstruction error for anomalies. Extensive experiments on brain MR images, retinal OCT images and retinal fundus images verify the effectiveness of our method for both image-level and pixel-level anomaly detection.
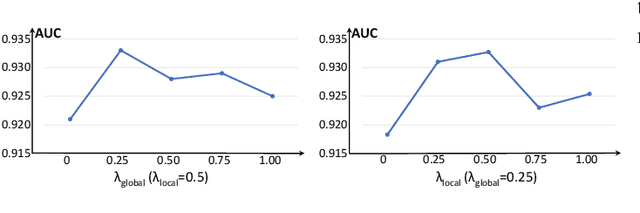
Sparse PCA via $l_{2,p}$-Norm Regularization for Unsupervised Feature Selection
Dec 29, 2020
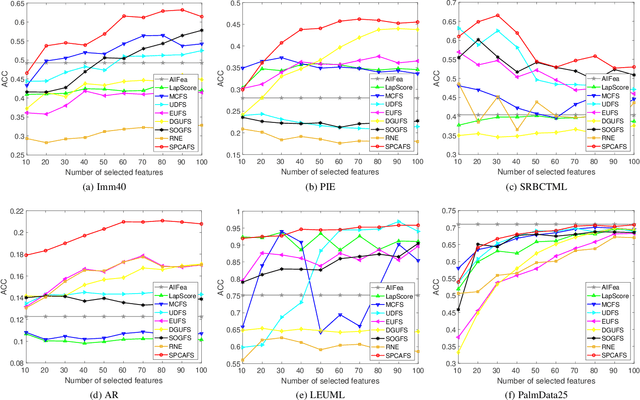


In the field of data mining, how to deal with high-dimensional data is an inevitable problem. Unsupervised feature selection has attracted more and more attention because it does not rely on labels. The performance of spectral-based unsupervised methods depends on the quality of constructed similarity matrix, which is used to depict the intrinsic structure of data. However, real-world data contain a large number of noise samples and features, making the similarity matrix constructed by original data cannot be completely reliable. Worse still, the size of similarity matrix expands rapidly as the number of samples increases, making the computational cost increase significantly. Inspired by principal component analysis, we propose a simple and efficient unsupervised feature selection method, by combining reconstruction error with $l_{2,p}$-norm regularization. The projection matrix, which is used for feature selection, is learned by minimizing the reconstruction error under the sparse constraint. Then, we present an efficient optimization algorithm to solve the proposed unsupervised model, and analyse the convergence and computational complexity of the algorithm theoretically. Finally, extensive experiments on real-world data sets demonstrate the effectiveness of our proposed method.