 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse PCA via $l_{2,p}$-Norm Regularization for Unsupervised Feature Selection
Paper and Code
Dec 29, 2020
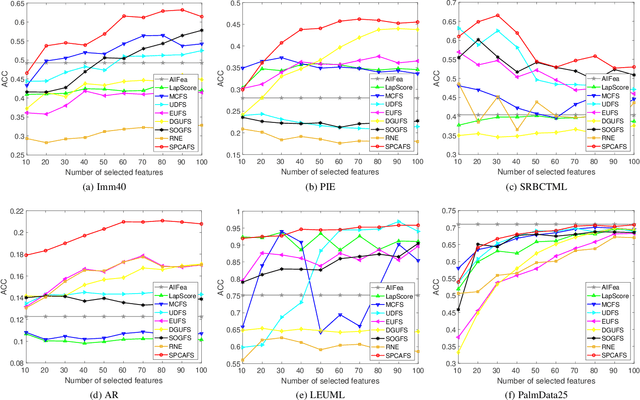


In the field of data mining, how to deal with high-dimensional data is an inevitable problem. Unsupervised feature selection has attracted more and more attention because it does not rely on labels. The performance of spectral-based unsupervised methods depends on the quality of constructed similarity matrix, which is used to depict the intrinsic structure of data. However, real-world data contain a large number of noise samples and features, making the similarity matrix constructed by original data cannot be completely reliable. Worse still, the size of similarity matrix expands rapidly as the number of samples increases, making the computational cost increase significantly. Inspired by principal component analysis, we propose a simple and efficient unsupervised feature selection method, by combining reconstruction error with $l_{2,p}$-norm regularization. The projection matrix, which is used for feature selection, is learned by minimizing the reconstruction error under the sparse constraint. Then, we present an efficient optimization algorithm to solve the proposed unsupervised model, and analyse the convergence and computational complexity of the algorithm theoretically. Finally, extensive experiments on real-world data sets demonstrate the effectiveness of our proposed method.