 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-attention learning enables real-time nonuniform rotational distortion correction in OCT
Jun 07, 2023Nonuniform rotational distortion (NURD) correction is vital for endoscopic optical coherence tomography (OCT) imaging and its functional extensions, such as angiography and elastography. Current NURD correction methods require time-consuming feature tracking or cross-correlation calculations and thus sacrifice temporal resolution. Here we propose a cross-attention learning method for the NURD correction in OCT. Our method is inspired by the recent success of the self-attention mechanism in natural language processing and computer vision. By leveraging its ability to model long-range dependencies, we can directly obtain the correlation between OCT A-lines at any distance, thus accelerating the NURD correction. We develop an end-to-end stacked cross-attention network and design three types of optimization constraints. We compare our method with two traditional feature-based methods and a CNN-based method, on two publicly-available endoscopic OCT datasets and a private dataset collected on our home-built endoscopic OCT system. Our method achieved a $\sim3\times$ speedup to real time ($26\pm 3$ fps), and superior correction performance.
Annotation-efficient learning for OCT segmentation
May 06, 2023Deep learning has been successfully applied to OCT segmentation. However, for data from different manufacturers and imaging protocols, and for different regions of interest (ROIs), it requires laborious and time-consuming data annotation and training, which is undesirable in many scenarios, such as surgical navigation and multi-center clinical trials. Here we propose an annotation-efficient learning method for OCT segmentation that could significantly reduce annotation costs. Leveraging self-supervised generative learning, we train a Transformer-based model to learn the OCT imagery. Then we connect the trained Transformer-based encoder to a CNN-based decoder, to learn the dense pixel-wise prediction in OCT segmentation. These training phases use open-access data and thus incur no annotation costs, and the pre-trained model can be adapted to different data and ROIs without re-training. Based on the greedy approximation for the k-center problem, we also introduce an algorithm for the selective annotation of the target data. We verified our method on publicly-available and private OCT datasets. Compared to the widely-used U-Net model with 100% training data, our method only requires ~10% of the data for achieving the same segmentation accuracy, and it speeds the training up to ~3.5 times. Furthermore, our proposed method outperforms other potential strategies that could improve annotation efficiency. We think this emphasis on learning efficiency may help improve the intelligence and application penetration of OCT-based technologies. Our code and pre-trained model are publicly available at https://github.com/SJTU-Intelligent-Optics-Lab/Annotation-efficient-learning-for-OCT-segmentation.
Proxy-bridged Image Reconstruction Network for Anomaly Detection in Medical Images
Oct 05, 2021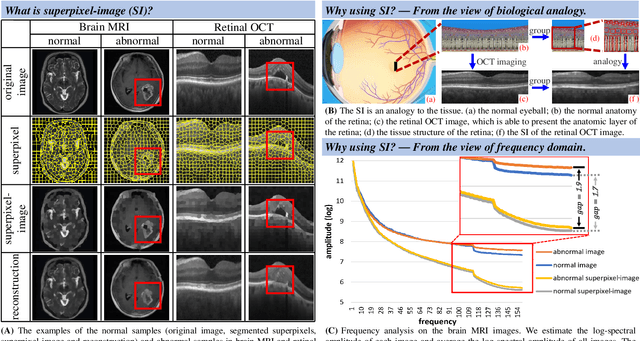
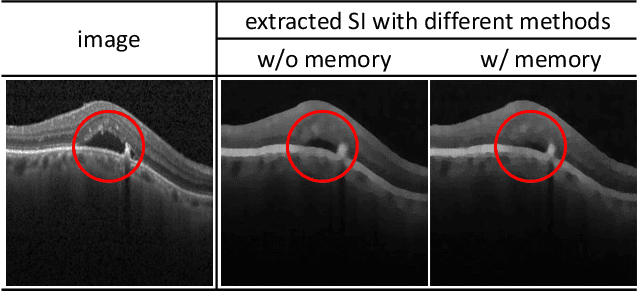
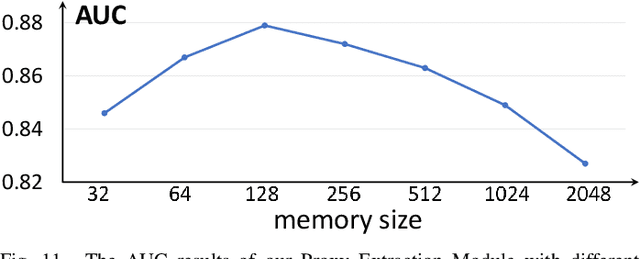
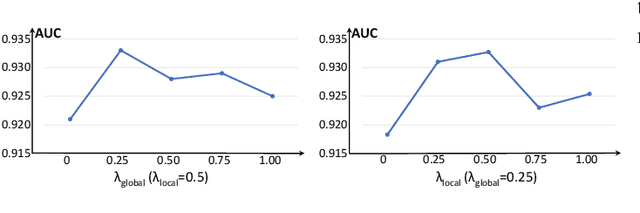
Anomaly detection in medical images refers to the identification of abnormal images with only normal images in the training set. Most existing methods solve this problem with a self-reconstruction framework, which tends to learn an identity mapping and reduces the sensitivity to anomalies. To mitigate this problem, in this paper, we propose a novel Proxy-bridged Image Reconstruction Network (ProxyAno) for anomaly detection in medical images. Specifically, we use an intermediate proxy to bridge the input image and the reconstructed image. We study different proxy types, and we find that the superpixel-image (SI) is the best one. We set all pixels' intensities within each superpixel as their average intensity, and denote this image as SI. The proposed ProxyAno consists of two modules, a Proxy Extraction Module and an Image Reconstruction Module. In the Proxy Extraction Module, a memory is introduced to memorize the feature correspondence for normal image to its corresponding SI, while the memorized correspondence does not apply to the abnormal images, which leads to the information loss for abnormal image and facilitates the anomaly detection. In the Image Reconstruction Module, we map an SI to its reconstructed image. Further, we crop a patch from the image and paste it on the normal SI to mimic the anomalies, and enforce the network to reconstruct the normal image even with the pseudo abnormal SI. In this way, our network enlarges the reconstruction error for anomalies. Extensive experiments on brain MR images, retinal OCT images and retinal fundus images verify the effectiveness of our method for both image-level and pixel-level anomaly detection.
CS2-Net: Deep Learning Segmentation of Curvilinear Structures in Medical Imaging
Oct 19, 2020
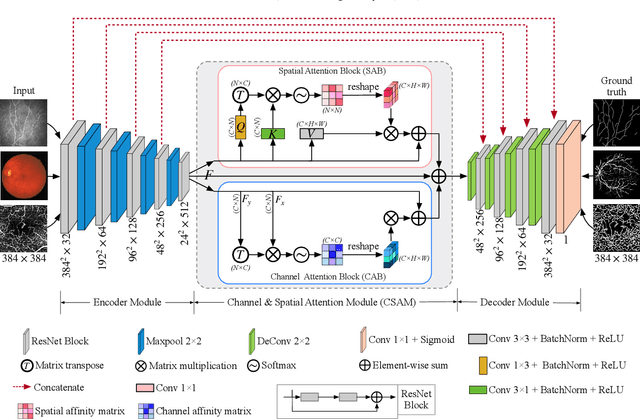
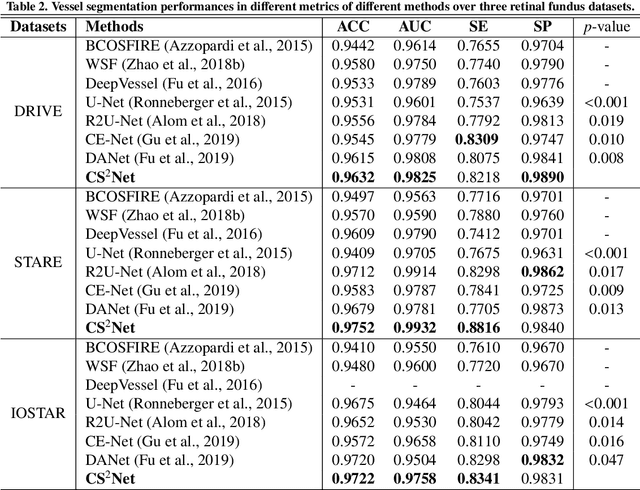
Automated detection of curvilinear structures, e.g., blood vessels or nerve fibres, from medical and biomedical images is a crucial early step in automatic image interpretation associated to the management of many diseases. Precise measurement of the morphological changes of these curvilinear organ structures informs clinicians for understanding the mechanism, diagnosis, and treatment of e.g. cardiovascular, kidney, eye, lung, and neurological conditions. In this work, we propose a generic and unified convolution neural network for the segmentation of curvilinear structures and illustrate in several 2D/3D medical imaging modalities. We introduce a new curvilinear structure segmentation network (CS2-Net), which includes a self-attention mechanism in the encoder and decoder to learn rich hierarchical representations of curvilinear structures. Two types of attention modules - spatial attention and channel attention - are utilized to enhance the inter-class discrimination and intra-class responsiveness, to further integrate local features with their global dependencies and normalization, adaptively. Furthermore, to facilitate the segmentation of curvilinear structures in medical images, we employ a 1x3 and a 3x1 convolutional kernel to capture boundary features. ...
Encoding Structure-Texture Relation with P-Net for Anomaly Detection in Retinal Images
Aug 09, 2020Anomaly detection in retinal image refers to the identification of abnormality caused by various retinal diseases/lesions, by only leveraging normal images in training phase. Normal images from healthy subjects often have regular structures (e.g., the structured blood vessels in the fundus image, or structured anatomy in optical coherence tomography image). On the contrary, the diseases and lesions often destroy these structures. Motivated by this, we propose to leverage the relation between the image texture and structure to design a deep neural network for anomaly detection. Specifically, we first extract the structure of the retinal images, then we combine both the structure features and the last layer features extracted from original health image to reconstruct the original input healthy image. The image feature provides the texture information and guarantees the uniqueness of the image recovered from the structure. In the end, we further utilize the reconstructed image to extract the structure and measure the difference between structure extracted from original and the reconstructed image. On the one hand, minimizing the reconstruction difference behaves like a regularizer to guarantee that the image is corrected reconstructed. On the other hand, such structure difference can also be used as a metric for normality measurement. The whole network is termed as P-Net because it has a ``P'' shape. Extensive experiments on RESC dataset and iSee dataset validate the effectiveness of our approach for anomaly detection in retinal images. Further, our method also generalizes well to novel class discovery in retinal images and anomaly detection in real-world images.
ROSE: A Retinal OCT-Angiography Vessel Segmentation Dataset and New Model
Jul 10, 2020
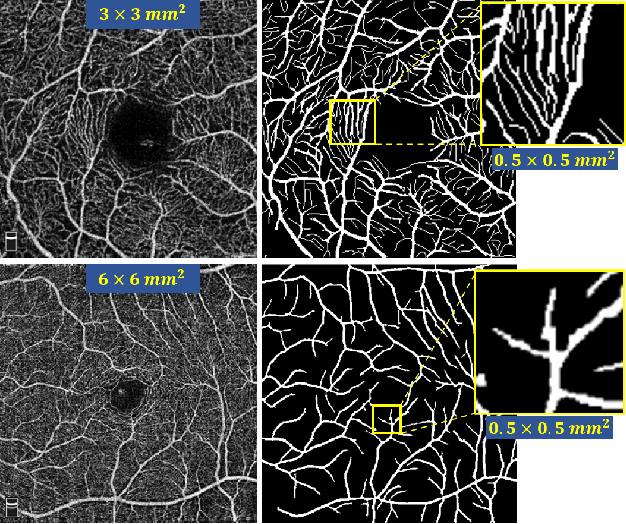
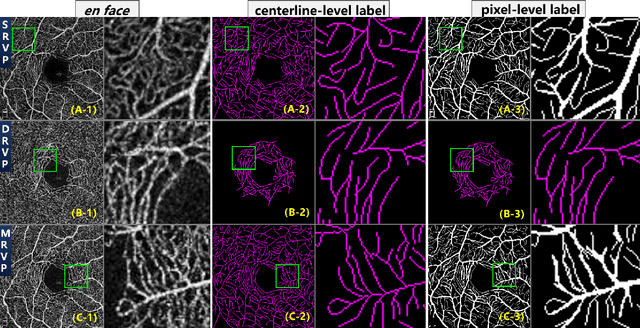
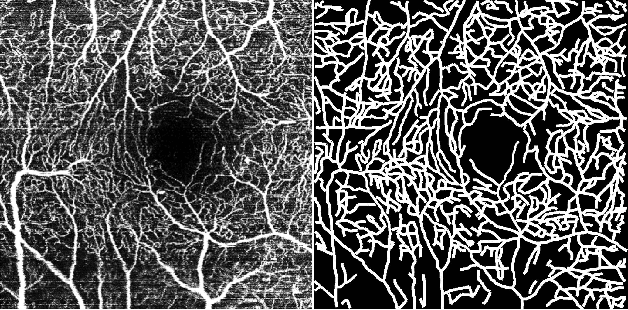
Optical Coherence Tomography Angiography (OCT-A) is a non-invasive imaging technique, and has been increasingly used to image the retinal vasculature at capillary level resolution. However, automated segmentation of retinal vessels in OCT-A has been under-studied due to various challenges such as low capillary visibility and high vessel complexity, despite its significance in understanding many eye-related diseases. In addition, there is no publicly available OCT-A dataset with manually graded vessels for training and validation. To address these issues, for the first time in the field of retinal image analysis we construct a dedicated Retinal OCT-A SEgmentation dataset (ROSE), which consists of 229 OCT-A images with vessel annotations at either centerline-level or pixel level. This dataset has been released for public access to assist researchers in the community in undertaking research in related topics. Secondly, we propose a novel Split-based Coarse-to-Fine vessel segmentation network (SCF-Net), with the ability to detect thick and thin vessels separately. In the SCF-Net, a split-based coarse segmentation (SCS) module is first introduced to produce a preliminary confidence map of vessels, and a split-based refinement (SRN) module is then used to optimize the shape/contour of the retinal microvasculature. Thirdly, we perform a thorough evaluation of the state-of-the-art vessel segmentation models and our SCF-Net on the proposed ROSE dataset. The experimental results demonstrate that our SCF-Net yields better vessel segmentation performance in OCT-A than both traditional methods and other deep learning methods.
Open-Narrow-Synechiae Anterior Chamber Angle Classification in AS-OCT Sequences
Jun 09, 2020
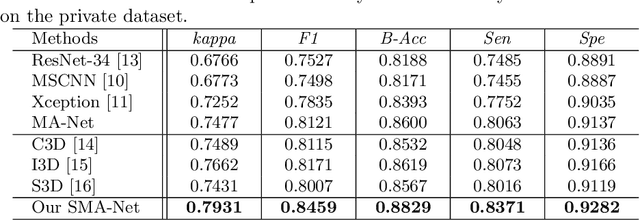
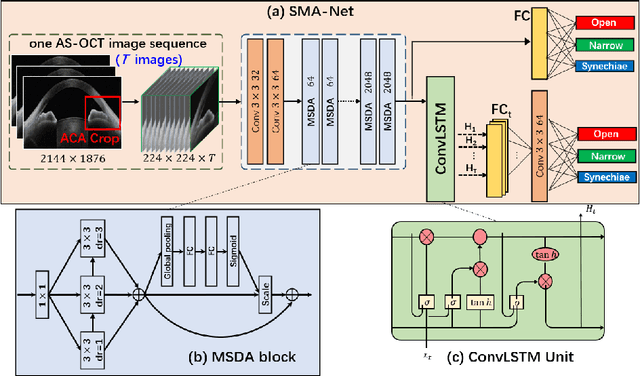
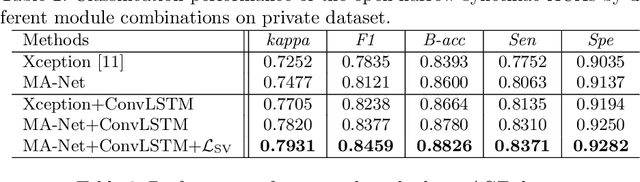
Anterior chamber angle (ACA) classification is a key step in the diagnosis of angle-closure glaucoma in Anterior Segment Optical Coherence Tomography (AS-OCT). Existing automated analysis methods focus on a binary classification system (i.e., open angle or angle-closure) in a 2D AS-OCT slice. However, clinical diagnosis requires a more discriminating ACA three-class system (i.e., open, narrow, or synechiae angles) for the benefit of clinicians who seek better to understand the progression of the spectrum of angle-closure glaucoma types. To address this, we propose a novel sequence multi-scale aggregation deep network (SMA-Net) for open-narrow-synechiae ACA classification based on an AS-OCT sequence. In our method, a Multi-Scale Discriminative Aggregation (MSDA) block is utilized to learn the multi-scale representations at slice level, while a ConvLSTM is introduced to study the temporal dynamics of these representations at sequence level. Finally, a multi-level loss function is used to combine the slice-based and sequence-based losses. The proposed method is evaluated across two AS-OCT datasets. The experimental results show that the proposed method outperforms existing state-of-the-art methods in applicability, effectiveness, and accuracy. We believe this work to be the first attempt to classify ACAs into open, narrow, or synechia types grading using AS-OCT sequences.
Sparse-GAN: Sparsity-constrained Generative Adversarial Network for Anomaly Detection in Retinal OCT Image
Jan 07, 2020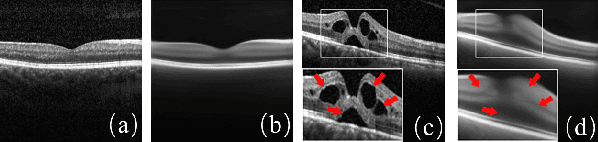
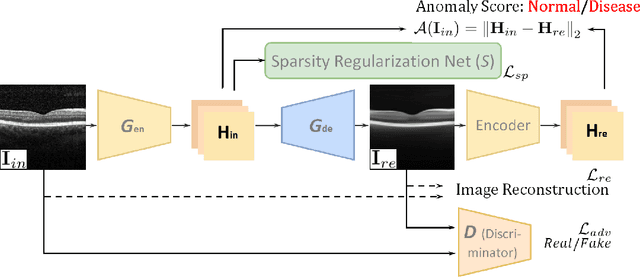
With the development of convolutional neural network, deep learning has shown its success for retinal disease detection from optical coherence tomography (OCT) images. However, deep learning often relies on large scale labelled data for training, which is oftentimes challenging especially for disease with low occurrence. Moreover, a deep learning system trained from data-set with one or a few diseases is unable to detect other unseen diseases, which limits the practical usage of the system in disease screening. To address the limitation, we propose a novel anomaly detection framework termed Sparsity-constrained Generative Adversarial Network (Sparse-GAN) for disease screening where only healthy data are available in the training set. The contributions of Sparse-GAN are two-folds: 1) The proposed Sparse-GAN predicts the anomalies in latent space rather than image-level; 2) Sparse-GAN is constrained by a novel Sparsity Regularization Net. Furthermore, in light of the role of lesions for disease screening, we present to leverage on an anomaly activation map to show the heatmap of lesions. We evaluate our proposed Sparse-GAN on a publicly available dataset, and the results show that the proposed method outperforms the state-of-the-art methods.
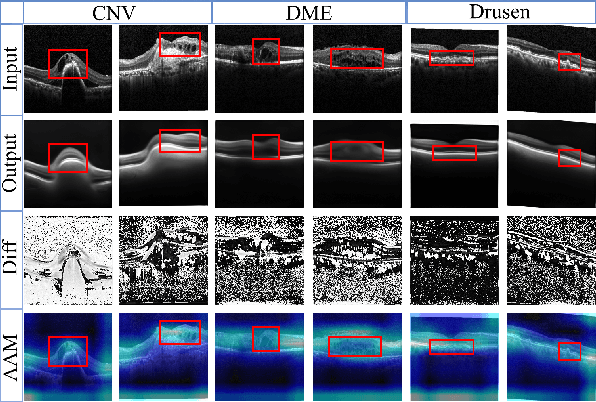
BioNet: Infusing Biomarker Prior into Global-to-Local Network for Choroid Segmentation in Optical Coherence Tomography Images
Dec 11, 2019
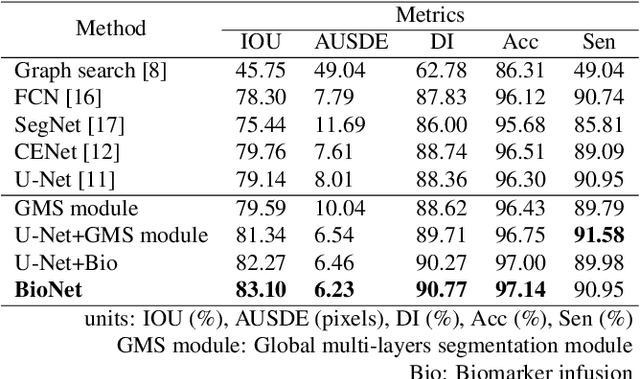
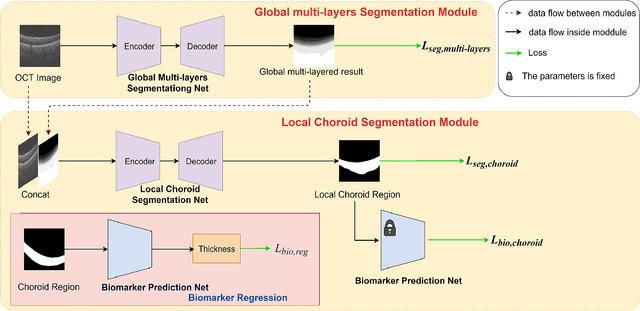

Choroid is the vascular layer of the eye, which is directly related to the incidence and severity of many ocular diseases. Optical Coherence Tomography (OCT) is capable of imaging both the cross-sectional view of retina and choroid, but the segmentation of the choroid region is challenging because of the fuzzy choroid-sclera interface (CSI). In this paper, we propose a biomarker infused global-to-local network (BioNet) for choroid segmentation, which segments the choroid with higher credibility and robustness. Firstly, our method trains a biomarker prediction network to learn the features of the biomarker. Then a global multi-layers segmentation module is applied to segment the OCT image into 12 layers. Finally, the global multi-layered result and the original OCT image are fed into a local choroid segmentation module to segment the choroid region with the biomarker infused as regularizer. We conducted comparison experiments with the state-of-the-art methods on a dataset (named AROD). The experimental results demonstrate the superiority of our method with $90.77\%$ Dice-index and 6.23 pixels Average-unsigned-surface-detection-error, etc.