 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyAgent-JDGenie: Technical Report on the GAIA
Oct 01, 2025Large Language Models are increasingly deployed as autonomous agents for complex real-world tasks, yet existing systems often focus on isolated improvements without a unifying design for robustness and adaptability. We propose a generalist agent architecture that integrates three core components: a collective multi-agent framework combining planning and execution agents with critic model voting, a hierarchical memory system spanning working, semantic, and procedural layers, and a refined tool suite for search, code execution, and multimodal parsing. Evaluated on a comprehensive benchmark, our framework consistently outperforms open-source baselines and approaches the performance of proprietary systems. These results demonstrate the importance of system-level integration and highlight a path toward scalable, resilient, and adaptive AI assistants capable of operating across diverse domains and tasks.
P/D-Device: Disaggregated Large Language Model between Cloud and Devices
Aug 12, 2025Serving disaggregated large language models has been widely adopted in industrial practice for enhanced performance. However, too many tokens generated in decoding phase, i.e., occupying the resources for a long time, essentially hamper the cloud from achieving a higher throughput. Meanwhile, due to limited on-device resources, the time to first token (TTFT), i.e., the latency of prefill phase, increases dramatically with the growth on prompt length. In order to concur with such a bottleneck on resources, i.e., long occupation in cloud and limited on-device computing capacity, we propose to separate large language model between cloud and devices. That is, the cloud helps a portion of the content for each device, only in its prefill phase. Specifically, after receiving the first token from the cloud, decoupling with its own prefill, the device responds to the user immediately for a lower TTFT. Then, the following tokens from cloud are presented via a speed controller for smoothed TPOT (the time per output token), until the device catches up with the progress. On-device prefill is then amortized using received tokens while the resource usage in cloud is controlled. Moreover, during cloud prefill, the prompt can be refined, using those intermediate data already generated, to further speed up on-device inference. We implement such a scheme P/D-Device, and confirm its superiority over other alternatives. We further propose an algorithm to decide the best settings. Real-trace experiments show that TTFT decreases at least 60%, maximum TPOT is about tens of milliseconds, and cloud throughput increases by up to 15x.
Enhancing Subject-Independent Accuracy in fNIRS-based Brain-Computer Interfaces with Optimized Channel Selection
Feb 26, 2025Achieving high subject-independent accuracy in functional near-infrared spectroscopy (fNIRS)-based brain-computer interfaces (BCIs) remains a challenge, particularly when minimizing the number of channels. This study proposes a novel feature extraction scheme and a Pearson correlation-based channel selection algorithm to enhance classification accuracy while reducing hardware complexity. Using an open-access fNIRS dataset, our method improved average accuracy by 28.09% compared to existing approaches, achieving a peak subject-independent accuracy of 95.98% with only two channels. These results demonstrate the potential of our optimized feature extraction and channel selection methods for developing efficient, subject-independent fNIRS-based BCI systems.
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Jan 29, 2025In this work, we introduce Janus-Pro, an advanced version of the previous work Janus. Specifically, Janus-Pro incorporates (1) an optimized training strategy, (2) expanded training data, and (3) scaling to larger model size. With these improvements, Janus-Pro achieves significant advancements in both multimodal understanding and text-to-image instruction-following capabilities, while also enhancing the stability of text-to-image generation. We hope this work will inspire further exploration in the field. Code and models are publicly available.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Dec 13, 2024



We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For the vision component, we incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution images with different aspect ratios. For the language component, we leverage DeepSeekMoE models with the Multi-head Latent Attention mechanism, which compresses Key-Value cache into latent vectors, to enable efficient inference and high throughput. Trained on an improved vision-language dataset, DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Our model series is composed of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small and DeepSeek-VL2, with 1.0B, 2.8B and 4.5B activated parameters respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance with similar or fewer activated parameters compared to existing open-source dense and MoE-based models. Codes and pre-trained models are publicly accessible at https://github.com/deepseek-ai/DeepSeek-VL2.
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
Nov 12, 2024
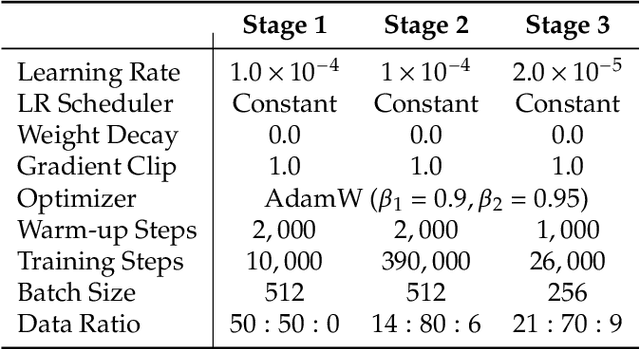

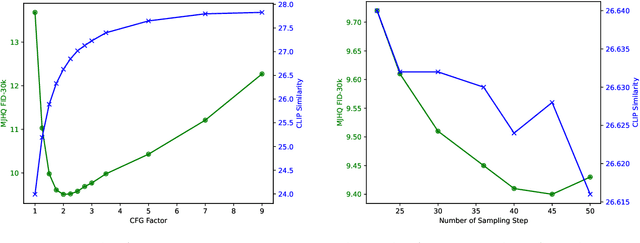
We present JanusFlow, a powerful framework that unifies image understanding and generation in a single model. JanusFlow introduces a minimalist architecture that integrates autoregressive language models with rectified flow, a state-of-the-art method in generative modeling. Our key finding demonstrates that rectified flow can be straightforwardly trained within the large language model framework, eliminating the need for complex architectural modifications. To further improve the performance of our unified model, we adopt two key strategies: (i) decoupling the understanding and generation encoders, and (ii) aligning their representations during unified training. Extensive experiments show that JanusFlow achieves comparable or superior performance to specialized models in their respective domains, while significantly outperforming existing unified approaches across standard benchmarks. This work represents a step toward more efficient and versatile vision-language models.
CAD-MLLM: Unifying Multimodality-Conditioned CAD Generation With MLLM
Nov 07, 2024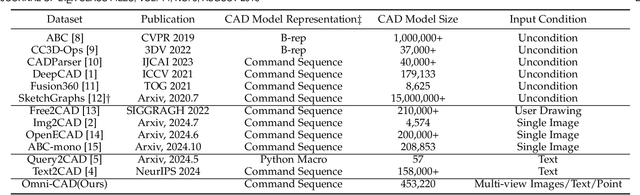
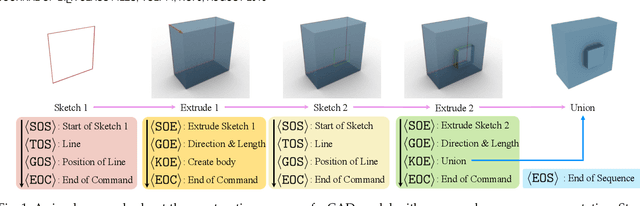
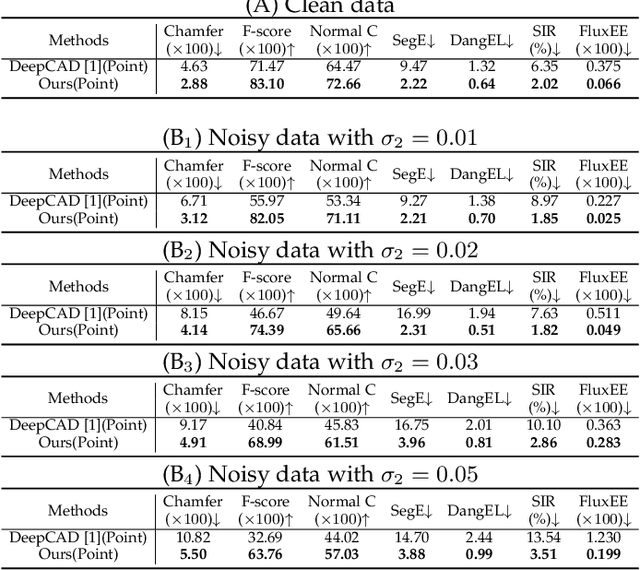
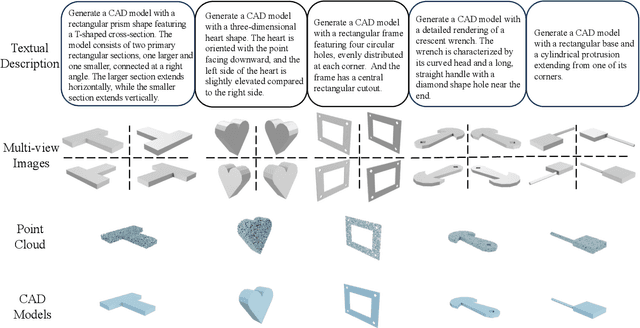
This paper aims to design a unified Computer-Aided Design (CAD) generation system that can easily generate CAD models based on the user's inputs in the form of textual description, images, point clouds, or even a combination of them. Towards this goal, we introduce the CAD-MLLM, the first system capable of generating parametric CAD models conditioned on the multimodal input. Specifically, within the CAD-MLLM framework, we leverage the command sequences of CAD models and then employ advanced large language models (LLMs) to align the feature space across these diverse multi-modalities data and CAD models' vectorized representations. To facilitate the model training, we design a comprehensive data construction and annotation pipeline that equips each CAD model with corresponding multimodal data. Our resulting dataset, named Omni-CAD, is the first multimodal CAD dataset that contains textual description, multi-view images, points, and command sequence for each CAD model. It contains approximately 450K instances and their CAD construction sequences. To thoroughly evaluate the quality of our generated CAD models, we go beyond current evaluation metrics that focus on reconstruction quality by introducing additional metrics that assess topology quality and surface enclosure extent. Extensive experimental results demonstrate that CAD-MLLM significantly outperforms existing conditional generative methods and remains highly robust to noises and missing points. The project page and more visualizations can be found at: https://cad-mllm.github.io/
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
Oct 17, 2024



In this paper, we introduce Janus, an autoregressive framework that unifies multimodal understanding and generation. Prior research often relies on a single visual encoder for both tasks, such as Chameleon. However, due to the differing levels of information granularity required by multimodal understanding and generation, this approach can lead to suboptimal performance, particularly in multimodal understanding. To address this issue, we decouple visual encoding into separate pathways, while still leveraging a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder's roles in understanding and generation, but also enhances the framework's flexibility. For instance, both the multimodal understanding and generation components can independently select their most suitable encoding methods. Experiments show that Janus surpasses previous unified model and matches or exceeds the performance of task-specific models. The simplicity, high flexibility, and effectiveness of Janus make it a strong candidate for next-generation unified multimodal models.
MagicID: Flexible ID Fidelity Generation System
Aug 20, 2024
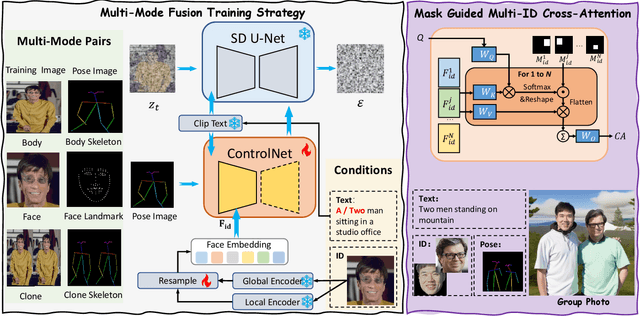


Portrait Fidelity Generation is a prominent research area in generative models, with a primary focus on enhancing both controllability and fidelity. Current methods face challenges in generating high-fidelity portrait results when faces occupy a small portion of the image with a low resolution, especially in multi-person group photo settings. To tackle these issues, we propose a systematic solution called MagicID, based on a self-constructed million-level multi-modal dataset named IDZoom. MagicID consists of Multi-Mode Fusion training strategy (MMF) and DDIM Inversion based ID Restoration inference framework (DIIR). During training, MMF iteratively uses the skeleton and landmark modalities from IDZoom as conditional guidance. By introducing the Clone Face Tuning in training stage and Mask Guided Multi-ID Cross Attention (MGMICA) in inference stage, explicit constraints on face positional features are achieved for multi-ID group photo generation. The DIIR aims to address the issue of artifacts. The DDIM Inversion is used in conjunction with face landmarks, global and local face features to achieve face restoration while keeping the background unchanged. Additionally, DIIR is plug-and-play and can be applied to any diffusion-based portrait generation method. To validate the effectiveness of MagicID, we conducted extensive comparative and ablation experiments. The experimental results demonstrate that MagicID has significant advantages in both subjective and objective metrics, and achieves controllable generation in multi-person scenarios.