 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Singing Style Conversion with Boundary-Aware Information Bottleneck
Apr 07, 2026This paper presents the submission of the S4 team to the Singing Voice Conversion Challenge 2025 (SVCC2025)-a novel singing style conversion system that advances fine-grained style conversion and control within in-domain settings. To address the critical challenges of style leakage, dynamic rendering, and high-fidelity generation with limited data, we introduce three key innovations: a boundary-aware Whisper bottleneck that pools phoneme-span representations to suppress residual source style while preserving linguistic content; an explicit frame-level technique matrix, enhanced by targeted F0 processing during inference, for stable and distinct dynamic style rendering; and a perceptually motivated high-frequency band completion strategy that leverages an auxiliary standard 48kHz SVC model to augment the high-frequency spectrum, thereby overcoming data scarcity without overfitting. In the official SVCC2025 subjective evaluation, our system achieves the best naturalness performance among all submissions while maintaining competitive results in speaker similarity and technique control, despite using significantly less extra singing data than other top-performing systems. Audio samples are available online.
Not Just What's There: Enabling CLIP to Comprehend Negated Visual Descriptions Without Fine-tuning
Feb 24, 2026Vision-Language Models (VLMs) like CLIP struggle to understand negation, often embedding affirmatives and negatives similarly (e.g., matching "no dog" with dog images). Existing methods refine negation understanding via fine-tuning CLIP's text encoder, risking overfitting. In this work, we propose CLIPGlasses, a plug-and-play framework that enhances CLIP's ability to comprehend negated visual descriptions. CLIPGlasses adopts a dual-stage design: a Lens module disentangles negated semantics from text embeddings, and a Frame module predicts context-aware repulsion strength, which is integrated into a modified similarity computation to penalize alignment with negated semantics, thereby reducing false positive matches. Experiments show that CLIP equipped with CLIPGlasses achieves competitive in-domain performance and outperforms state-of-the-art methods in cross-domain generalization. Its superiority is especially evident under low-resource conditions, indicating stronger robustness across domains.
MOSS Transcribe Diarize: Accurate Transcription with Speaker Diarization
Jan 08, 2026Speaker-Attributed, Time-Stamped Transcription (SATS) aims to transcribe what is said and to precisely determine the timing of each speaker, which is particularly valuable for meeting transcription. Existing SATS systems rarely adopt an end-to-end formulation and are further constrained by limited context windows, weak long-range speaker memory, and the inability to output timestamps. To address these limitations, we present MOSS Transcribe Diarize, a unified multimodal large language model that jointly performs Speaker-Attributed, Time-Stamped Transcription in an end-to-end paradigm. Trained on extensive real wild data and equipped with a 128k context window for up to 90-minute inputs, MOSS Transcribe Diarize scales well and generalizes robustly. Across comprehensive evaluations, it outperforms state-of-the-art commercial systems on multiple public and in-house benchmarks.
The ML.ENERGY Benchmark: Toward Automated Inference Energy Measurement and Optimization
May 09, 2025As the adoption of Generative AI in real-world services grow explosively, energy has emerged as a critical bottleneck resource. However, energy remains a metric that is often overlooked, under-explored, or poorly understood in the context of building ML systems. We present the ML.ENERGY Benchmark, a benchmark suite and tool for measuring inference energy consumption under realistic service environments, and the corresponding ML.ENERGY Leaderboard, which have served as a valuable resource for those hoping to understand and optimize the energy consumption of their generative AI services. In this paper, we explain four key design principles for benchmarking ML energy we have acquired over time, and then describe how they are implemented in the ML.ENERGY Benchmark. We then highlight results from the latest iteration of the benchmark, including energy measurements of 40 widely used model architectures across 6 different tasks, case studies of how ML design choices impact energy consumption, and how automated optimization recommendations can lead to significant (sometimes more than 40%) energy savings without changing what is being computed by the model. The ML.ENERGY Benchmark is open-source and can be easily extended to various customized models and application scenarios.
Tempo: Application-aware LLM Serving with Mixed SLO Requirements
Apr 24, 2025



The integration of Large Language Models (LLMs) into diverse applications, ranging from interactive chatbots and cloud AIOps to intelligent agents, has introduced a wide spectrum of Service Level Objectives (SLOs) for responsiveness. These workloads include latency-sensitive requests focused on per-token latency in streaming chat, throughput-intensive requests that require rapid full responses to invoke tools, and collective requests with dynamic dependencies arising from self-reflection or agent-based reasoning. This workload diversity, amplified by unpredictable request information such as response lengths and runtime dependencies, makes existing schedulers inadequate even within their design envelopes. In this paper, we define service gain as the useful service delivered by completing requests. We observe that as SLO directly reflects the actual performance needs of requests, completing a request much faster than its SLO (e.g., deadline) yields limited additional service gain. Based on this insight, we introduce Tempo, the first systematic SLO-aware scheduler designed to maximize service gain across diverse LLM workloads. Tempo allocates just enough serving bandwidth to meet each SLO, maximizing residual capacity for others best-effort workloads. Instead of assuming request information or none at all, it adopts a hybrid scheduling strategy: using quantile-based response upper bounds and dependency-graph matching for conservative initial estimates, prioritizing requests by service gain density, and refining decisions online as generation progresses. Our evaluation across diverse workloads, including chat, reasoning, and agentic pipelines, shows that Tempo improves end-to-end service gain by up to 8.3$\times$ and achieves up to 10.3$\times$ SLO goodput compared to state-of-the-art designs
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Jan 29, 2025In this work, we introduce Janus-Pro, an advanced version of the previous work Janus. Specifically, Janus-Pro incorporates (1) an optimized training strategy, (2) expanded training data, and (3) scaling to larger model size. With these improvements, Janus-Pro achieves significant advancements in both multimodal understanding and text-to-image instruction-following capabilities, while also enhancing the stability of text-to-image generation. We hope this work will inspire further exploration in the field. Code and models are publicly available.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Dec 13, 2024



We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For the vision component, we incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution images with different aspect ratios. For the language component, we leverage DeepSeekMoE models with the Multi-head Latent Attention mechanism, which compresses Key-Value cache into latent vectors, to enable efficient inference and high throughput. Trained on an improved vision-language dataset, DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Our model series is composed of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small and DeepSeek-VL2, with 1.0B, 2.8B and 4.5B activated parameters respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance with similar or fewer activated parameters compared to existing open-source dense and MoE-based models. Codes and pre-trained models are publicly accessible at https://github.com/deepseek-ai/DeepSeek-VL2.
Automated 3D Physical Simulation of Open-world Scene with Gaussian Splatting
Nov 19, 2024
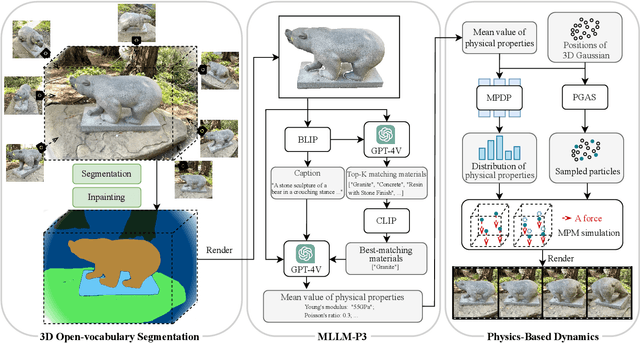
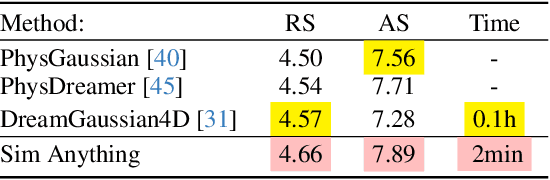
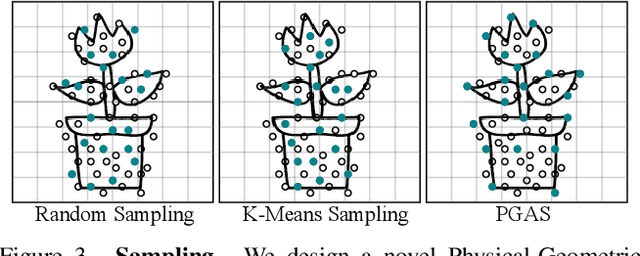
Recent advancements in 3D generation models have opened new possibilities for simulating dynamic 3D object movements and customizing behaviors, yet creating this content remains challenging. Current methods often require manual assignment of precise physical properties for simulations or rely on video generation models to predict them, which is computationally intensive. In this paper, we rethink the usage of multi-modal large language model (MLLM) in physics-based simulation, and present Sim Anything, a physics-based approach that endows static 3D objects with interactive dynamics. We begin with detailed scene reconstruction and object-level 3D open-vocabulary segmentation, progressing to multi-view image in-painting. Inspired by human visual reasoning, we propose MLLM-based Physical Property Perception (MLLM-P3) to predict mean physical properties of objects in a zero-shot manner. Based on the mean values and the object's geometry, the Material Property Distribution Prediction model (MPDP) model then estimates the full distribution, reformulating the problem as probability distribution estimation to reduce computational costs. Finally, we simulate objects in an open-world scene with particles sampled via the Physical-Geometric Adaptive Sampling (PGAS) strategy, efficiently capturing complex deformations and significantly reducing computational costs. Extensive experiments and user studies demonstrate our Sim Anything achieves more realistic motion than state-of-the-art methods within 2 minutes on a single GPU.
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
Nov 12, 2024

We present JanusFlow, a powerful framework that unifies image understanding and generation in a single model. JanusFlow introduces a minimalist architecture that integrates autoregressive language models with rectified flow, a state-of-the-art method in generative modeling. Our key finding demonstrates that rectified flow can be straightforwardly trained within the large language model framework, eliminating the need for complex architectural modifications. To further improve the performance of our unified model, we adopt two key strategies: (i) decoupling the understanding and generation encoders, and (ii) aligning their representations during unified training. Extensive experiments show that JanusFlow achieves comparable or superior performance to specialized models in their respective domains, while significantly outperforming existing unified approaches across standard benchmarks. This work represents a step toward more efficient and versatile vision-language models.