 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCornserve: A Distributed Serving System for Any-to-Any Multimodal Models
Mar 12, 2026Any-to-Any models are an emerging class of multimodal models that accept combinations of multimodal data (e.g., text, image, video, audio) as input and generate them as output. Serving these models are challenging; different requests with different input and output modalities traverse different paths through the model computation graph, and each component of the model have different scaling characteristics. We present Cornserve, a distributed serving system for generic Any-to-Any models. Cornserve provides a flexible task abstraction for expressing Any-to-Any model computation graphs, enabling component disaggregation and independent scaling. The distributed runtime dispatches compute to the data plane via an efficient record-and-replay execution model that keeps track of data dependencies, and forwards tensor data between components directly from the producer to the consumer. Built on Kubernetes with approximately 23K new lines of Python, Cornserve supports diverse Any-to-Any models and delivers up to 3.81$\times$ higher throughput and 5.79$\times$ lower tail latency. Cornserve is open-source, and the demo video is available on YouTube.
Where Do the Joules Go? Diagnosing Inference Energy Consumption
Jan 29, 2026Energy is now a critical ML computing resource. While measuring energy consumption and observing trends is a valuable first step, accurately understanding and diagnosing why those differences occur is crucial for optimization. To that end, we begin by presenting a large-scale measurement study of inference time and energy across the generative AI landscape with 46 models, 7 tasks, and 1,858 different configurations on NVIDIA H100 and B200 GPUs. Our empirical findings span order-of-magnitude variations: LLM task type can lead to 25$\times$ energy differences, video generation sometimes consumes more than 100$\times$ the energy of images, and GPU utilization differences can result in 3--5$\times$ energy differences. Based on our observations, we present a framework for reasoning about the underlying mechanisms that govern time and energy consumption. The essence is that time and energy are determined by latent metrics like memory and utilization, which are in turn affected by various factors across the algorithm, software, and hardware layers. Our framework also extends directly to throughput per watt, a critical metric for power-constrained datacenters.
Kareus: Joint Reduction of Dynamic and Static Energy in Large Model Training
Jan 25, 2026The computing demand of AI is growing at an unprecedented rate, but energy supply is not keeping pace. As a result, energy has become an expensive, contended resource that requires explicit management and optimization. Although recent works have made significant progress in large model training optimization, they focus only on a single aspect of energy consumption: dynamic or static energy. We find that fine-grained kernel scheduling and frequency scaling jointly and interdependently impact both dynamic and static energy consumption. Based on this finding, we design Kareus, a training system that pushes the time--energy tradeoff frontier by optimizing both aspects. Kareus decomposes the intractable joint optimization problem into local, partition-based subproblems. It then uses a multi-pass multi-objective optimization algorithm to find execution schedules that push the time--energy tradeoff frontier. Compared to the state of the art, Kareus reduces training energy by up to 28.3% at the same training time, or reduces training time by up to 27.5% at the same energy consumption.
Cornserve: Efficiently Serving Any-to-Any Multimodal Models
Dec 18, 2025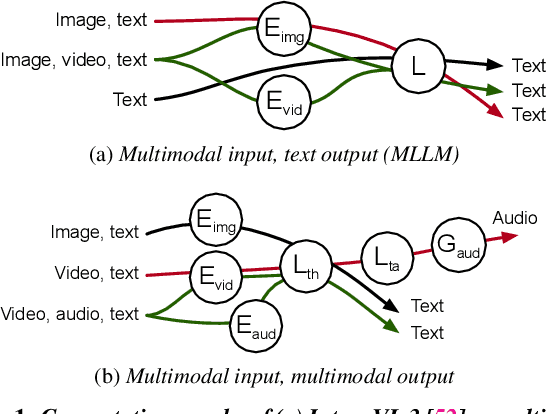
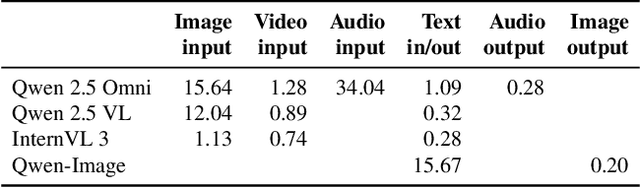
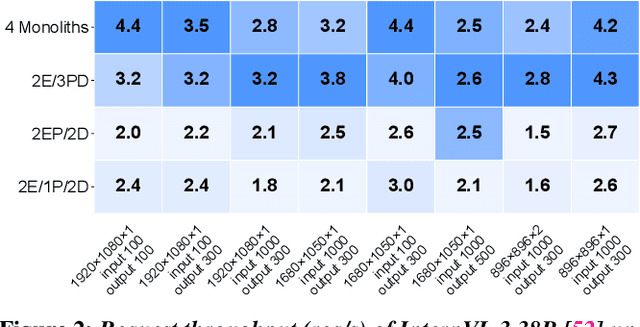
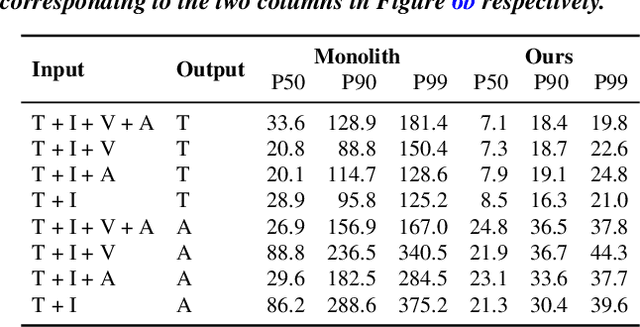
We present Cornserve, an efficient online serving system for an emerging class of multimodal models called Any-to-Any models. Any-to-Any models accept combinations of text and multimodal data (e.g., image, video, audio) as input and also generate combinations of text and multimodal data as output, introducing request type, computation path, and computation scaling heterogeneity in model serving. Cornserve allows model developers to describe the computation graph of generic Any-to-Any models, which consists of heterogeneous components such as multimodal encoders, autoregressive models like Large Language Models (LLMs), and multimodal generators like Diffusion Transformers (DiTs). Given this, Cornserve's planner automatically finds an optimized deployment plan for the model, including whether and how to disaggregate the model into smaller components based on model and workload characteristics. Cornserve's distributed runtime then executes the model per the plan, efficiently handling Any-to-Any model heterogeneity during online serving. Evaluations show that Cornserve can efficiently serve diverse Any-to-Any models and workloads, delivering up to 3.81$\times$ throughput improvement and up to 5.79$\times$ tail latency reduction over existing solutions.
The ML.ENERGY Benchmark: Toward Automated Inference Energy Measurement and Optimization
May 09, 2025As the adoption of Generative AI in real-world services grow explosively, energy has emerged as a critical bottleneck resource. However, energy remains a metric that is often overlooked, under-explored, or poorly understood in the context of building ML systems. We present the ML.ENERGY Benchmark, a benchmark suite and tool for measuring inference energy consumption under realistic service environments, and the corresponding ML.ENERGY Leaderboard, which have served as a valuable resource for those hoping to understand and optimize the energy consumption of their generative AI services. In this paper, we explain four key design principles for benchmarking ML energy we have acquired over time, and then describe how they are implemented in the ML.ENERGY Benchmark. We then highlight results from the latest iteration of the benchmark, including energy measurements of 40 widely used model architectures across 6 different tasks, case studies of how ML design choices impact energy consumption, and how automated optimization recommendations can lead to significant (sometimes more than 40%) energy savings without changing what is being computed by the model. The ML.ENERGY Benchmark is open-source and can be easily extended to various customized models and application scenarios.
Evaluation Framework for AI Systems in "the Wild"
Apr 23, 2025Generative AI (GenAI) models have become vital across industries, yet current evaluation methods have not adapted to their widespread use. Traditional evaluations often rely on benchmarks and fixed datasets, frequently failing to reflect real-world performance, which creates a gap between lab-tested outcomes and practical applications. This white paper proposes a comprehensive framework for how we should evaluate real-world GenAI systems, emphasizing diverse, evolving inputs and holistic, dynamic, and ongoing assessment approaches. The paper offers guidance for practitioners on how to design evaluation methods that accurately reflect real-time capabilities, and provides policymakers with recommendations for crafting GenAI policies focused on societal impacts, rather than fixed performance numbers or parameter sizes. We advocate for holistic frameworks that integrate performance, fairness, and ethics and the use of continuous, outcome-oriented methods that combine human and automated assessments while also being transparent to foster trust among stakeholders. Implementing these strategies ensures GenAI models are not only technically proficient but also ethically responsible and impactful.
Andes: Defining and Enhancing Quality-of-Experience in LLM-Based Text Streaming Services
Apr 25, 2024



The advent of large language models (LLMs) has transformed text-based services, enabling capabilities ranging from real-time translation to AI-driven chatbots. However, existing serving systems primarily focus on optimizing server-side aggregate metrics like token generation throughput, ignoring individual user experience with streamed text. As a result, under high and/or bursty load, a significant number of users can receive unfavorable service quality or poor Quality-of-Experience (QoE). In this paper, we first formally define QoE of text streaming services, where text is delivered incrementally and interactively to users, by considering the end-to-end token delivery process throughout the entire interaction with the user. Thereafter, we propose Andes, a QoE-aware serving system that enhances user experience for LLM-enabled text streaming services. At its core, Andes strategically allocates contended GPU resources among multiple requests over time to optimize their QoE. Our evaluations demonstrate that, compared to the state-of-the-art LLM serving systems like vLLM, Andes improves the average QoE by up to 3.2$\times$ under high request rate, or alternatively, it attains up to 1.6$\times$ higher request rate while preserving high QoE.
Toward Cross-Layer Energy Optimizations in Machine Learning Systems
Apr 10, 2024The enormous energy consumption of machine learning (ML) and generative AI workloads shows no sign of waning, taking a toll on operating costs, power delivery, and environmental sustainability. Despite a long line of research on energy-efficient hardware, we found that software plays a critical role in ML energy optimization through two recent works: Zeus and Perseus. This is especially true for large language models (LLMs) because their model sizes and, therefore, energy demands are growing faster than hardware efficiency improvements. Therefore, we advocate for a cross-layer approach for energy optimizations in ML systems, where hardware provides architectural support that pushes energy-efficient software further, while software leverages and abstracts the hardware to develop techniques that bring hardware-agnostic energy-efficiency gains.
Perseus: Removing Energy Bloat from Large Model Training
Dec 12, 2023Training large AI models on numerous GPUs consumes a massive amount of energy. We observe that not all energy consumed during training directly contributes to end-to-end training throughput, and a significant portion can be removed without slowing down training, which we call energy bloat. In this work, we identify two independent sources of energy bloat in large model training, intrinsic and extrinsic, and propose Perseus, a unified optimization framework that mitigates both. Perseus obtains the "iteration time-energy" Pareto frontier of any large model training job using an efficient iterative graph cut-based algorithm and schedules energy consumption of its forward and backward computations across time to remove intrinsic and extrinsic energy bloat. Evaluation on large models like GPT-3 and Bloom shows that Perseus reduces energy consumption of large model training by up to 30%, enabling savings otherwise unobtainable before.
Chasing Low-Carbon Electricity for Practical and Sustainable DNN Training
Mar 04, 2023

Deep learning has experienced significant growth in recent years, resulting in increased energy consumption and carbon emission from the use of GPUs for training deep neural networks (DNNs). Answering the call for sustainability, conventional solutions have attempted to move training jobs to locations or time frames with lower carbon intensity. However, moving jobs to other locations may not always be feasible due to large dataset sizes or data regulations. Moreover, postponing training can negatively impact application service quality because the DNNs backing the service are not updated in a timely fashion. In this work, we present a practical solution that reduces the carbon footprint of DNN training without migrating or postponing jobs. Specifically, our solution observes real-time carbon intensity shifts during training and controls the energy consumption of GPUs, thereby reducing carbon footprint while maintaining training performance. Furthermore, in order to proactively adapt to shifting carbon intensity, we propose a lightweight machine learning algorithm that predicts the carbon intensity of the upcoming time frame. Our solution, Chase, reduces the total carbon footprint of training ResNet-50 on ImageNet by 13.6% while only increasing training time by 2.5%.