 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTetriServe: Efficient DiT Serving for Heterogeneous Image Generation
Oct 02, 2025Diffusion Transformer (DiT) models excel at generating highquality images through iterative denoising steps, but serving them under strict Service Level Objectives (SLOs) is challenging due to their high computational cost, particularly at large resolutions. Existing serving systems use fixed degree sequence parallelism, which is inefficient for heterogeneous workloads with mixed resolutions and deadlines, leading to poor GPU utilization and low SLO attainment. In this paper, we propose step-level sequence parallelism to dynamically adjust the parallel degree of individual requests according to their deadlines. We present TetriServe, a DiT serving system that implements this strategy for highly efficient image generation. Specifically, TetriServe introduces a novel round-based scheduling mechanism that improves SLO attainment: (1) discretizing time into fixed rounds to make deadline-aware scheduling tractable, (2) adapting parallelism at the step level and minimize GPU hour consumption, and (3) jointly packing requests to minimize late completions. Extensive evaluation on state-of-the-art DiT models shows that TetriServe achieves up to 32% higher SLO attainment compared to existing solutions without degrading image quality.
Evaluation Framework for AI Systems in "the Wild"
Apr 23, 2025Generative AI (GenAI) models have become vital across industries, yet current evaluation methods have not adapted to their widespread use. Traditional evaluations often rely on benchmarks and fixed datasets, frequently failing to reflect real-world performance, which creates a gap between lab-tested outcomes and practical applications. This white paper proposes a comprehensive framework for how we should evaluate real-world GenAI systems, emphasizing diverse, evolving inputs and holistic, dynamic, and ongoing assessment approaches. The paper offers guidance for practitioners on how to design evaluation methods that accurately reflect real-time capabilities, and provides policymakers with recommendations for crafting GenAI policies focused on societal impacts, rather than fixed performance numbers or parameter sizes. We advocate for holistic frameworks that integrate performance, fairness, and ethics and the use of continuous, outcome-oriented methods that combine human and automated assessments while also being transparent to foster trust among stakeholders. Implementing these strategies ensures GenAI models are not only technically proficient but also ethically responsible and impactful.
FedFetch: Faster Federated Learning with Adaptive Downstream Prefetching
Apr 21, 2025Federated learning (FL) is a machine learning paradigm that facilitates massively distributed model training with end-user data on edge devices directed by a central server. However, the large number of heterogeneous clients in FL deployments leads to a communication bottleneck between the server and the clients. This bottleneck is made worse by straggling clients, any one of which will further slow down training. To tackle these challenges, researchers have proposed techniques like client sampling and update compression. These techniques work well in isolation but combine poorly in the downstream, server-to-client direction. This is because unselected clients have outdated local model states and need to synchronize these states with the server first. We introduce FedFetch, a strategy to mitigate the download time overhead caused by combining client sampling and compression techniques. FedFetch achieves this with an efficient prefetch schedule for clients to prefetch model states multiple rounds before a stated training round. We empirically show that adding FedFetch to communication efficient FL techniques reduces end-to-end training time by 1.26$\times$ and download time by 4.49$\times$ across compression techniques with heterogeneous client settings. Our implementation is available at https://github.com/DistributedML/FedFetch
NL4Opt Competition: Formulating Optimization Problems Based on Their Natural Language Descriptions
Mar 27, 2023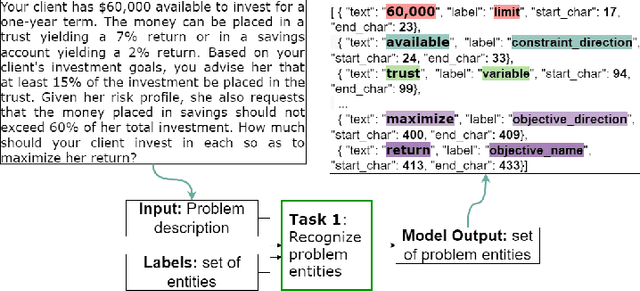

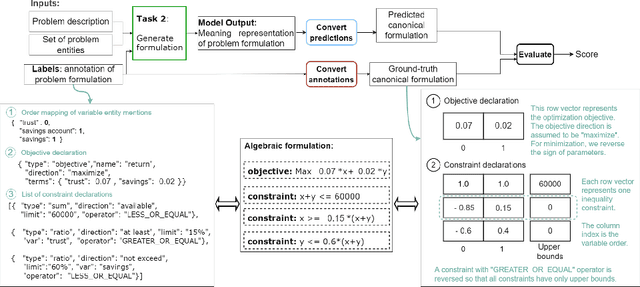
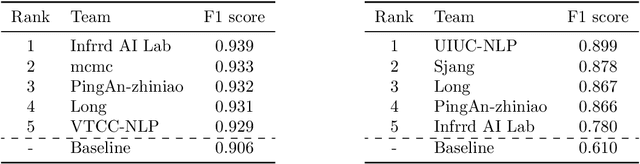
The Natural Language for Optimization (NL4Opt) Competition was created to investigate methods of extracting the meaning and formulation of an optimization problem based on its text description. Specifically, the goal of the competition is to increase the accessibility and usability of optimization solvers by allowing non-experts to interface with them using natural language. We separate this challenging goal into two sub-tasks: (1) recognize and label the semantic entities that correspond to the components of the optimization problem; (2) generate a meaning representation (i.e., a logical form) of the problem from its detected problem entities. The first task aims to reduce ambiguity by detecting and tagging the entities of the optimization problems. The second task creates an intermediate representation of the linear programming (LP) problem that is converted into a format that can be used by commercial solvers. In this report, we present the LP word problem dataset and shared tasks for the NeurIPS 2022 competition. Furthermore, we investigate and compare the performance of the ChatGPT large language model against the winning solutions. Through this competition, we hope to bring interest towards the development of novel machine learning applications and datasets for optimization modeling.
GlueFL: Reconciling Client Sampling and Model Masking for Bandwidth Efficient Federated Learning
Dec 03, 2022
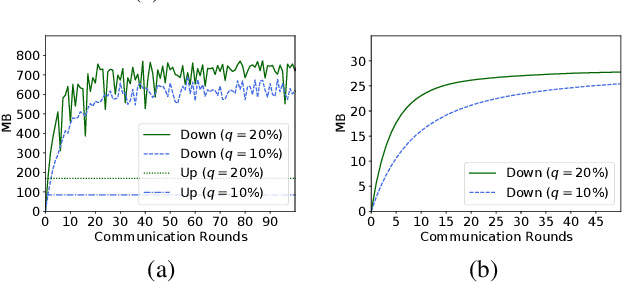
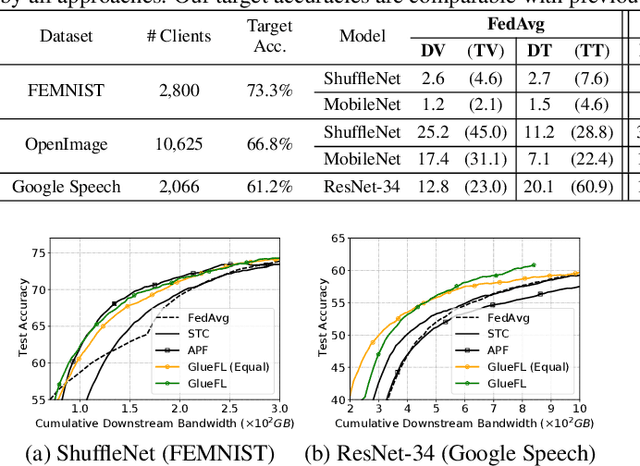
Federated learning (FL) is an effective technique to directly involve edge devices in machine learning training while preserving client privacy. However, the substantial communication overhead of FL makes training challenging when edge devices have limited network bandwidth. Existing work to optimize FL bandwidth overlooks downstream transmission and does not account for FL client sampling. In this paper we propose GlueFL, a framework that incorporates new client sampling and model compression algorithms to mitigate low download bandwidths of FL clients. GlueFL prioritizes recently used clients and bounds the number of changed positions in compression masks in each round. Across three popular FL datasets and three state-of-the-art strategies, GlueFL reduces downstream client bandwidth by 27% on average and reduces training time by 29% on average.
Augmenting Operations Research with Auto-Formulation of Optimization Models from Problem Descriptions
Oct 11, 2022



We describe an augmented intelligence system for simplifying and enhancing the modeling experience for operations research. Using this system, the user receives a suggested formulation of an optimization problem based on its description. To facilitate this process, we build an intuitive user interface system that enables the users to validate and edit the suggestions. We investigate controlled generation techniques to obtain an automatic suggestion of formulation. Then, we evaluate their effectiveness with a newly created dataset of linear programming problems drawn from various application domains.
Accelerating Federated Learning via Sampling Anchor Clients with Large Batches
Jun 13, 2022



Using large batches in recent federated learning studies has improved convergence rates, but it requires additional computation overhead compared to using small batches. To overcome this limitation, we propose a unified framework FedAMD, which disjoints the participants into anchor and miner groups based on time-varying probabilities. Each client in the anchor group computes the gradient using a large batch, which is regarded as its bullseye. Clients in the miner group perform multiple local updates using serial mini-batches, and each local update is also indirectly regulated by the global target derived from the average of clients' bullseyes. As a result, the miner group follows a near-optimal update towards the global minimizer, adapted to update the global model. Measured by $\epsilon$-approximation, FedAMD achieves a convergence rate of $O(1/\epsilon)$ under non-convex objectives by sampling an anchor with a constant probability. The theoretical result considerably surpasses the state-of-the-art algorithm BVR-L-SGD at $O(1/\epsilon^{3/2})$, while FedAMD reduces at least $O(1/\epsilon)$ communication overhead. Empirical studies on real-world datasets validate the effectiveness of FedAMD and demonstrate the superiority of our proposed algorithm.
Sign Bit is Enough: A Learning Synchronization Framework for Multi-hop All-reduce with Ultimate Compression
Apr 14, 2022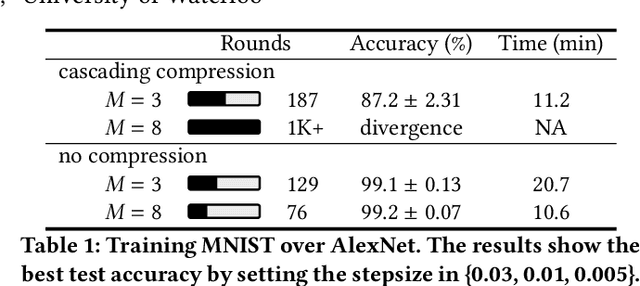
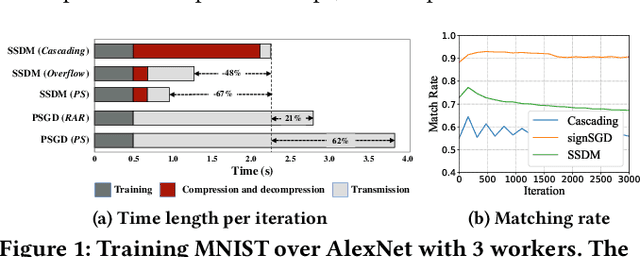
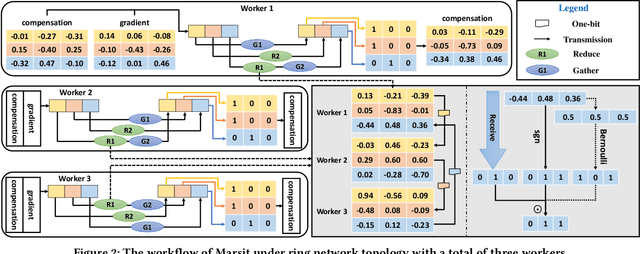

Traditional one-bit compressed stochastic gradient descent can not be directly employed in multi-hop all-reduce, a widely adopted distributed training paradigm in network-intensive high-performance computing systems such as public clouds. According to our theoretical findings, due to the cascading compression, the training process has considerable deterioration on the convergence performance. To overcome this limitation, we implement a sign-bit compression-based learning synchronization framework, Marsit. It prevents cascading compression via an elaborate bit-wise operation for unbiased sign aggregation and its specific global compensation mechanism for mitigating compression deviation. The proposed framework retains the same theoretical convergence rate as non-compression mechanisms. Experimental results demonstrate that Marsit reduces up to 35% training time while preserving the same accuracy as training without compression.