 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnecting Thompson Sampling and UCB: Towards More Efficient Trade-offs Between Privacy and Regret
May 05, 2025



We address differentially private stochastic bandit problems from the angles of exploring the deep connections among Thompson Sampling with Gaussian priors, Gaussian mechanisms, and Gaussian differential privacy (GDP). We propose DP-TS-UCB, a novel parametrized private bandit algorithm that enables to trade off privacy and regret. DP-TS-UCB satisfies $ \tilde{O} \left(T^{0.25(1-\alpha)}\right)$-GDP and enjoys an $O \left(K\ln^{\alpha+1}(T)/\Delta \right)$ regret bound, where $\alpha \in [0,1]$ controls the trade-off between privacy and regret. Theoretically, our DP-TS-UCB relies on anti-concentration bounds of Gaussian distributions and links exploration mechanisms in Thompson Sampling-based algorithms and Upper Confidence Bound-based algorithms, which may be of independent interest.
FedFetch: Faster Federated Learning with Adaptive Downstream Prefetching
Apr 21, 2025Federated learning (FL) is a machine learning paradigm that facilitates massively distributed model training with end-user data on edge devices directed by a central server. However, the large number of heterogeneous clients in FL deployments leads to a communication bottleneck between the server and the clients. This bottleneck is made worse by straggling clients, any one of which will further slow down training. To tackle these challenges, researchers have proposed techniques like client sampling and update compression. These techniques work well in isolation but combine poorly in the downstream, server-to-client direction. This is because unselected clients have outdated local model states and need to synchronize these states with the server first. We introduce FedFetch, a strategy to mitigate the download time overhead caused by combining client sampling and compression techniques. FedFetch achieves this with an efficient prefetch schedule for clients to prefetch model states multiple rounds before a stated training round. We empirically show that adding FedFetch to communication efficient FL techniques reduces end-to-end training time by 1.26$\times$ and download time by 4.49$\times$ across compression techniques with heterogeneous client settings. Our implementation is available at https://github.com/DistributedML/FedFetch
Training and Evaluating Causal Forecasting Models for Time-Series
Oct 31, 2024



Deep learning time-series models are often used to make forecasts that inform downstream decisions. Since these decisions can differ from those in the training set, there is an implicit requirement that time-series models will generalize outside of their training distribution. Despite this core requirement, time-series models are typically trained and evaluated on in-distribution predictive tasks. We extend the orthogonal statistical learning framework to train causal time-series models that generalize better when forecasting the effect of actions outside of their training distribution. To evaluate these models, we leverage Regression Discontinuity Designs popular in economics to construct a test set of causal treatment effects.
Adaptive Randomized Smoothing: Certifying Multi-Step Defences against Adversarial Examples
Jun 14, 2024



We propose Adaptive Randomized Smoothing (ARS) to certify the predictions of our test-time adaptive models against adversarial examples. ARS extends the analysis of randomized smoothing using f-Differential Privacy to certify the adaptive composition of multiple steps. For the first time, our theory covers the sound adaptive composition of general and high-dimensional functions of noisy input. We instantiate ARS on deep image classification to certify predictions against adversarial examples of bounded $L_{\infty}$ norm. In the $L_{\infty}$ threat model, our flexibility enables adaptation through high-dimensional input-dependent masking. We design adaptivity benchmarks, based on CIFAR-10 and CelebA, and show that ARS improves accuracy by $2$ to $5\%$ points. On ImageNet, ARS improves accuracy by $1$ to $3\%$ points over standard RS without adaptivity.
Efficient and Adaptive Posterior Sampling Algorithms for Bandits
May 02, 2024


We study Thompson Sampling-based algorithms for stochastic bandits with bounded rewards. As the existing problem-dependent regret bound for Thompson Sampling with Gaussian priors [Agrawal and Goyal, 2017] is vacuous when $T \le 288 e^{64}$, we derive a more practical bound that tightens the coefficient of the leading term %from $288 e^{64}$ to $1270$. Additionally, motivated by large-scale real-world applications that require scalability, adaptive computational resource allocation, and a balance in utility and computation, we propose two parameterized Thompson Sampling-based algorithms: Thompson Sampling with Model Aggregation (TS-MA-$\alpha$) and Thompson Sampling with Timestamp Duelling (TS-TD-$\alpha$), where $\alpha \in [0,1]$ controls the trade-off between utility and computation. Both algorithms achieve $O \left(K\ln^{\alpha+1}(T)/\Delta \right)$ regret bound, where $K$ is the number of arms, $T$ is the finite learning horizon, and $\Delta$ denotes the single round performance loss when pulling a sub-optimal arm.
PANORAMIA: Privacy Auditing of Machine Learning Models without Retraining
Feb 12, 2024



We introduce a privacy auditing scheme for ML models that relies on membership inference attacks using generated data as "non-members". This scheme, which we call PANORAMIA, quantifies the privacy leakage for large-scale ML models without control of the training process or model re-training and only requires access to a subset of the training data. To demonstrate its applicability, we evaluate our auditing scheme across multiple ML domains, ranging from image and tabular data classification to large-scale language models.
DP-AdamBC: Your DP-Adam Is Actually DP-SGD
Dec 21, 2023The Adam optimizer is a popular choice in contemporary deep learning, due to its strong empirical performance. However we observe that in privacy sensitive scenarios, the traditional use of Differential Privacy (DP) with the Adam optimizer leads to sub-optimal performance on several tasks. We find that this performance degradation is due to a DP bias in Adam's second moment estimator, introduced by the addition of independent noise in the gradient computation to enforce DP guarantees. This DP bias leads to a different scaling for low variance parameter updates, that is inconsistent with the behavior of non-private Adam. We propose DP-AdamBC, an optimization algorithm which removes the bias in the second moment estimation and retrieves the expected behaviour of Adam. Empirically, DP-AdamBC significantly improves the optimization performance of DP-Adam by up to 3.5% in final accuracy in image, text, and graph node classification tasks.
DP-Adam: Correcting DP Bias in Adam's Second Moment Estimation
Apr 21, 2023



We observe that the traditional use of DP with the Adam optimizer introduces a bias in the second moment estimation, due to the addition of independent noise in the gradient computation. This bias leads to a different scaling for low variance parameter updates, that is inconsistent with the behavior of non-private Adam, and Adam's sign descent interpretation. Empirically, correcting the bias introduced by DP noise significantly improves the optimization performance of DP-Adam.
Packing Privacy Budget Efficiently
Dec 26, 2022



Machine learning (ML) models can leak information about users, and differential privacy (DP) provides a rigorous way to bound that leakage under a given budget. This DP budget can be regarded as a new type of compute resource in workloads of multiple ML models training on user data. Once it is used, the DP budget is forever consumed. Therefore, it is crucial to allocate it most efficiently to train as many models as possible. This paper presents the scheduler for privacy that optimizes for efficiency. We formulate privacy scheduling as a new type of multidimensional knapsack problem, called privacy knapsack, which maximizes DP budget efficiency. We show that privacy knapsack is NP-hard, hence practical algorithms are necessarily approximate. We develop an approximation algorithm for privacy knapsack, DPK, and evaluate it on microbenchmarks and on a new, synthetic private-ML workload we developed from the Alibaba ML cluster trace. We show that DPK: (1) often approaches the efficiency-optimal schedule, (2) consistently schedules more tasks compared to a state-of-the-art privacy scheduling algorithm that focused on fairness (1.3-1.7x in Alibaba, 1.0-2.6x in microbenchmarks), but (3) sacrifices some level of fairness for efficiency. Therefore, using DPK, DP ML operators should be able to train more models on the same amount of user data while offering the same privacy guarantee to their users.
GlueFL: Reconciling Client Sampling and Model Masking for Bandwidth Efficient Federated Learning
Dec 03, 2022
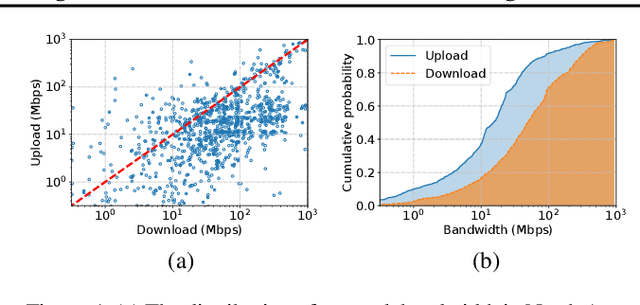
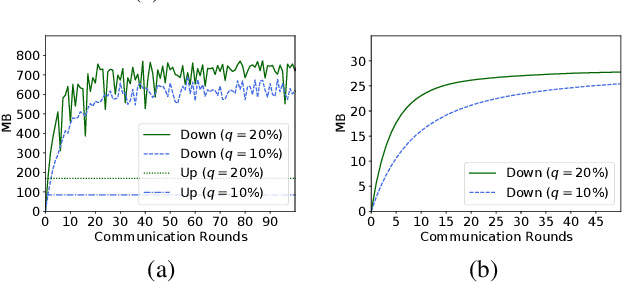
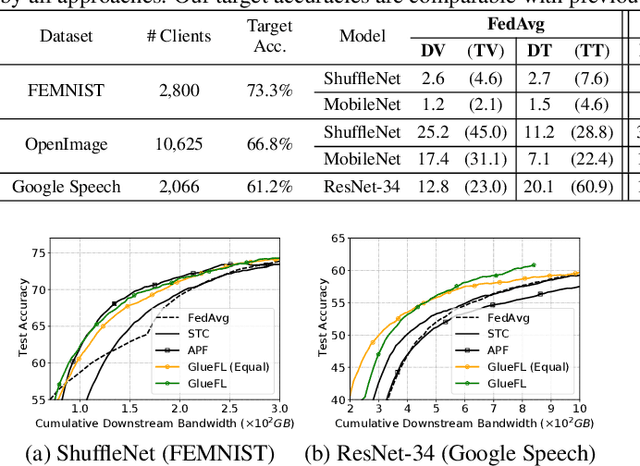
Federated learning (FL) is an effective technique to directly involve edge devices in machine learning training while preserving client privacy. However, the substantial communication overhead of FL makes training challenging when edge devices have limited network bandwidth. Existing work to optimize FL bandwidth overlooks downstream transmission and does not account for FL client sampling. In this paper we propose GlueFL, a framework that incorporates new client sampling and model compression algorithms to mitigate low download bandwidths of FL clients. GlueFL prioritizes recently used clients and bounds the number of changed positions in compression masks in each round. Across three popular FL datasets and three state-of-the-art strategies, GlueFL reduces downstream client bandwidth by 27% on average and reduces training time by 29% on average.