 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFake Runs, Real Fixes -- Analyzing xPU Performance Through Simulation
Mar 18, 2025



As models become larger, ML accelerators are a scarce resource whose performance must be continually optimized to improve efficiency. Existing performance analysis tools are coarse grained, and fail to capture model performance at the machine-code level. In addition, these tools often do not provide specific recommendations for optimizations. We present xPU-Shark, a fine-grained methodology for analyzing ML models at the machine-code level that provides actionable optimization suggestions. Our core insight is to use a hardware-level simulator, an artifact of the hardware design process that we can re-purpose for performance analysis. xPU-Shark captures traces from production deployments running on accelerators and replays them in a modified microarchitecture simulator to gain low-level insights into the model's performance. We implement xPU-Shark for our in-house accelerator and used it to analyze the performance of several of our production LLMs, revealing several previously-unknown microarchitecture inefficiencies. Leveraging these insights, we optimize a common communication collective by up to 15% and reduce token generation latency by up to 4.1%.
Monitoring and Adapting ML Models on Mobile Devices
May 17, 2023



ML models are increasingly being pushed to mobile devices, for low-latency inference and offline operation. However, once the models are deployed, it is hard for ML operators to track their accuracy, which can degrade unpredictably (e.g., due to data drift). We design the first end-to-end system for continuously monitoring and adapting models on mobile devices without requiring feedback from users. Our key observation is that often model degradation is due to a specific root cause, which may affect a large group of devices. Therefore, once the system detects a consistent degradation across a large number of devices, it employs a root cause analysis to determine the origin of the problem and applies a cause-specific adaptation. We evaluate the system on two computer vision datasets, and show it consistently boosts accuracy compared to existing approaches. On a dataset containing photos collected from driving cars, our system improves the accuracy on average by 15%.
Packing Privacy Budget Efficiently
Dec 26, 2022



Machine learning (ML) models can leak information about users, and differential privacy (DP) provides a rigorous way to bound that leakage under a given budget. This DP budget can be regarded as a new type of compute resource in workloads of multiple ML models training on user data. Once it is used, the DP budget is forever consumed. Therefore, it is crucial to allocate it most efficiently to train as many models as possible. This paper presents the scheduler for privacy that optimizes for efficiency. We formulate privacy scheduling as a new type of multidimensional knapsack problem, called privacy knapsack, which maximizes DP budget efficiency. We show that privacy knapsack is NP-hard, hence practical algorithms are necessarily approximate. We develop an approximation algorithm for privacy knapsack, DPK, and evaluate it on microbenchmarks and on a new, synthetic private-ML workload we developed from the Alibaba ML cluster trace. We show that DPK: (1) often approaches the efficiency-optimal schedule, (2) consistently schedules more tasks compared to a state-of-the-art privacy scheduling algorithm that focused on fairness (1.3-1.7x in Alibaba, 1.0-2.6x in microbenchmarks), but (3) sacrifices some level of fairness for efficiency. Therefore, using DPK, DP ML operators should be able to train more models on the same amount of user data while offering the same privacy guarantee to their users.
A Tale of Two Models: Constructing Evasive Attacks on Edge Models
Apr 22, 2022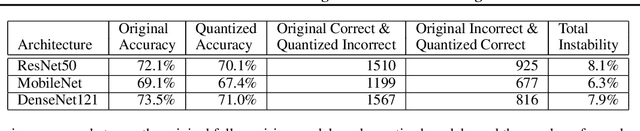
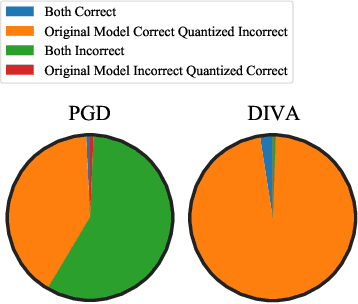
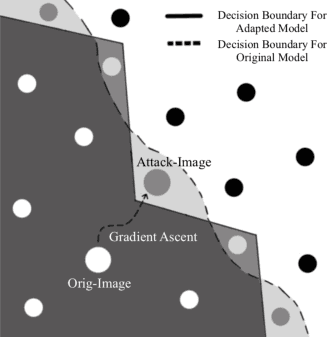
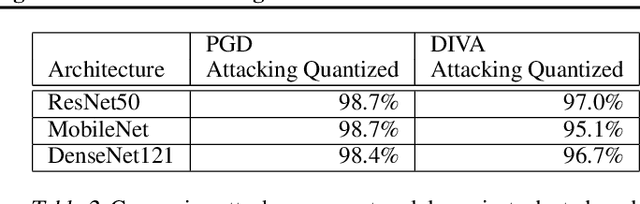
Full-precision deep learning models are typically too large or costly to deploy on edge devices. To accommodate to the limited hardware resources, models are adapted to the edge using various edge-adaptation techniques, such as quantization and pruning. While such techniques may have a negligible impact on top-line accuracy, the adapted models exhibit subtle differences in output compared to the original model from which they are derived. In this paper, we introduce a new evasive attack, DIVA, that exploits these differences in edge adaptation, by adding adversarial noise to input data that maximizes the output difference between the original and adapted model. Such an attack is particularly dangerous, because the malicious input will trick the adapted model running on the edge, but will be virtually undetectable by the original model, which typically serves as the authoritative model version, used for validation, debugging and retraining. We compare DIVA to a state-of-the-art attack, PGD, and show that DIVA is only 1.7-3.6% worse on attacking the adapted model but 1.9-4.2 times more likely not to be detected by the the original model under a whitebox and semi-blackbox setting, compared to PGD.
Treehouse: A Case For Carbon-Aware Datacenter Software
Jan 06, 2022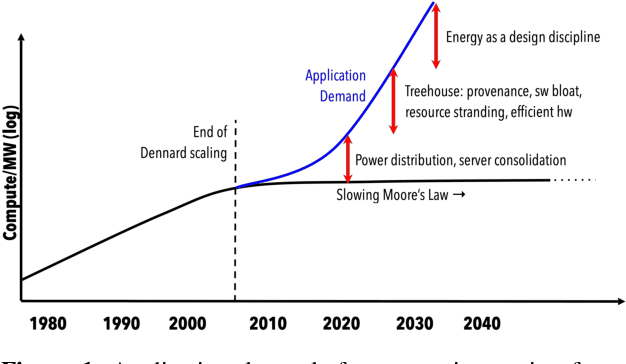
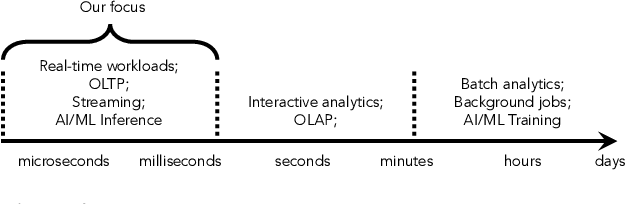
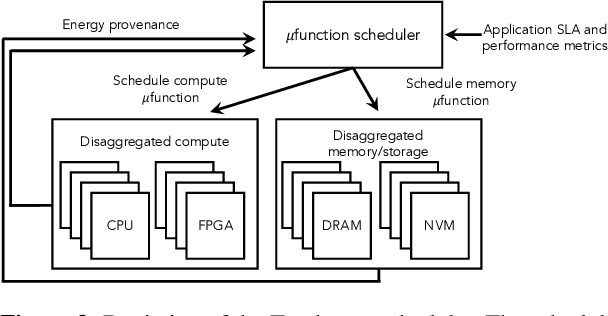
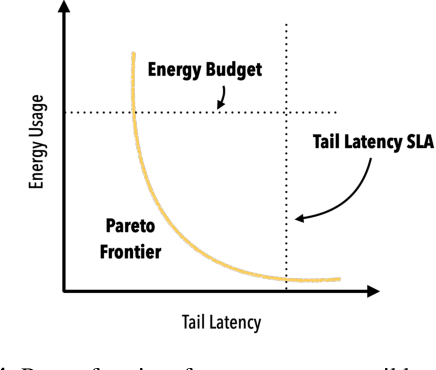
The end of Dennard scaling and the slowing of Moore's Law has put the energy use of datacenters on an unsustainable path. Datacenters are already a significant fraction of worldwide electricity use, with application demand scaling at a rapid rate. We argue that substantial reductions in the carbon intensity of datacenter computing are possible with a software-centric approach: by making energy and carbon visible to application developers on a fine-grained basis, by modifying system APIs to make it possible to make informed trade offs between performance and carbon emissions, and by raising the level of application programming to allow for flexible use of more energy efficient means of compute and storage. We also lay out a research agenda for systems software to reduce the carbon footprint of datacenter computing.
Privacy Budget Scheduling
Jun 29, 2021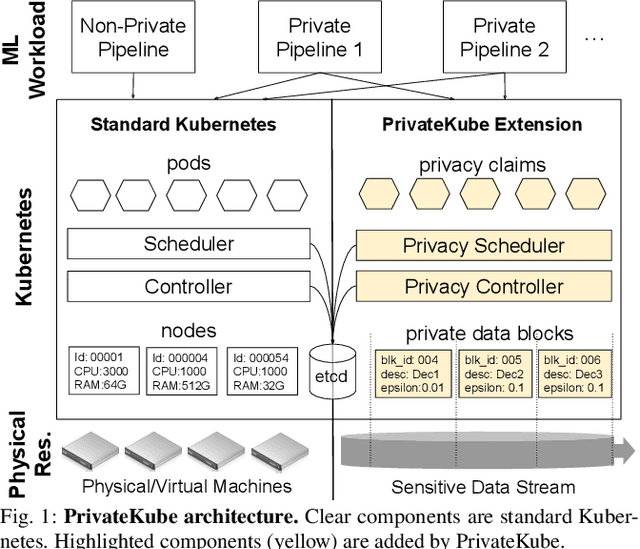
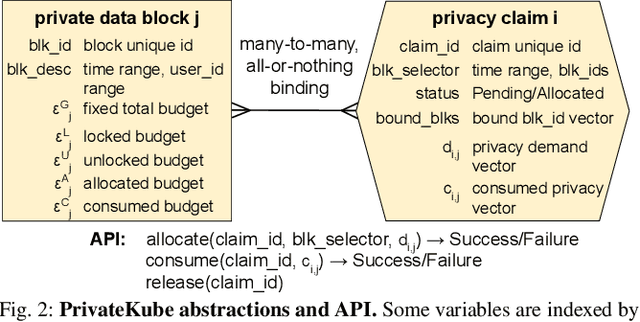
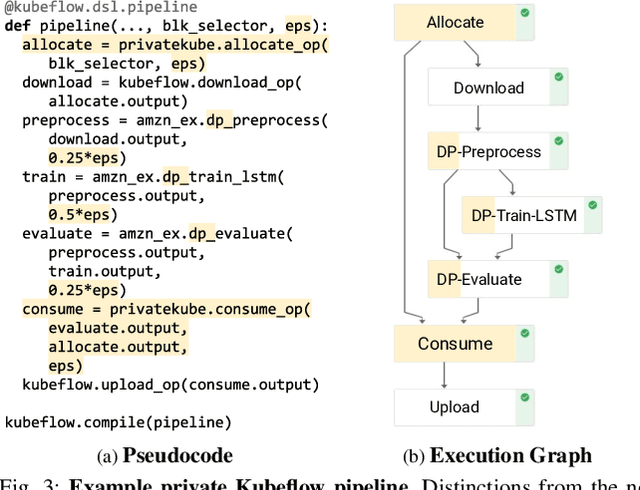
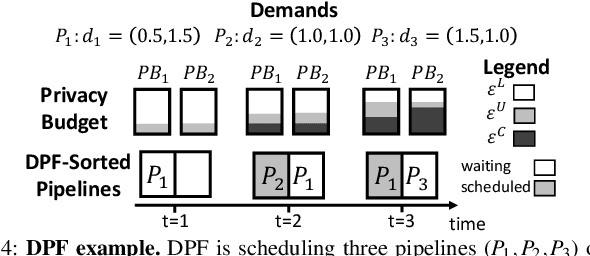
Machine learning (ML) models trained on personal data have been shown to leak information about users. Differential privacy (DP) enables model training with a guaranteed bound on this leakage. Each new model trained with DP increases the bound on data leakage and can be seen as consuming part of a global privacy budget that should not be exceeded. This budget is a scarce resource that must be carefully managed to maximize the number of successfully trained models. We describe PrivateKube, an extension to the popular Kubernetes datacenter orchestrator that adds privacy as a new type of resource to be managed alongside other traditional compute resources, such as CPU, GPU, and memory. The abstractions we design for the privacy resource mirror those defined by Kubernetes for traditional resources, but there are also major differences. For example, traditional compute resources are replenishable while privacy is not: a CPU can be regained after a model finishes execution while privacy budget cannot. This distinction forces a re-design of the scheduler. We present DPF (Dominant Private Block Fairness) -- a variant of the popular Dominant Resource Fairness (DRF) algorithm -- that is geared toward the non-replenishable privacy resource but enjoys similar theoretical properties as DRF. We evaluate PrivateKube and DPF on microbenchmarks and an ML workload on Amazon Reviews data. Compared to existing baselines, DPF allows training more models under the same global privacy guarantee. This is especially true for DPF over R\'enyi DP, a highly composable form of DP.
Characterizing and Taming Model Instability Across Edge Devices
Oct 18, 2020

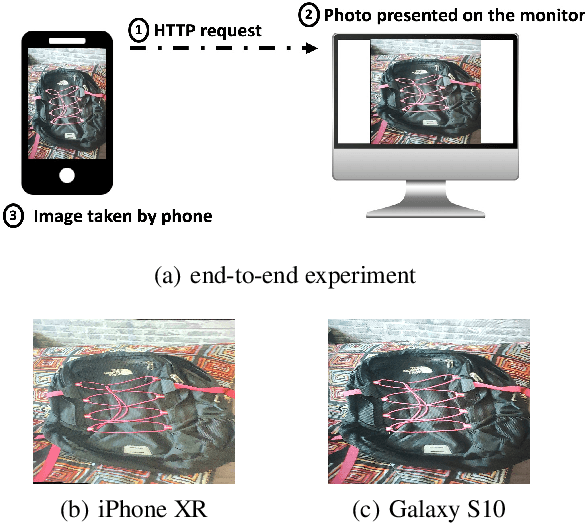
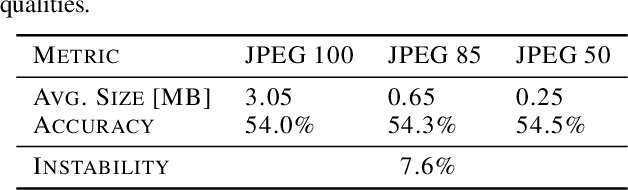
The same machine learning model running on different edge devices may produce highly-divergent outputs on a nearly-identical input. Possible reasons for the divergence include differences in the device sensors, the device's signal processing hardware and software, and its operating system and processors. This paper presents the first methodical characterization of the variations in model prediction across real-world mobile devices. We demonstrate that accuracy is not a useful metric to characterize prediction divergence, and introduce a new metric, instability, which captures this variation. We characterize different sources for instability, and show that differences in compression formats and image signal processing account for significant instability in object classification models. Notably, in our experiments, 14-17% of images produced divergent classifications across one or more phone models. We evaluate three different techniques for reducing instability. In particular, we adapt prior work on making models robust to noise in order to fine-tune models to be robust to variations across edge devices. We demonstrate our fine-tuning techniques reduce instability by 75%.
Training Robust Tree Ensembles for Security
Dec 03, 2019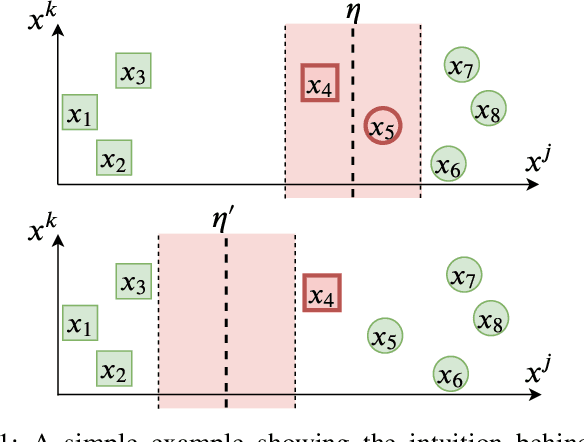
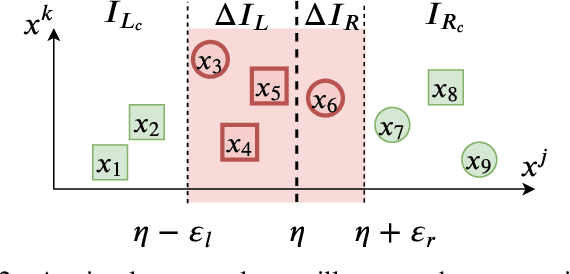
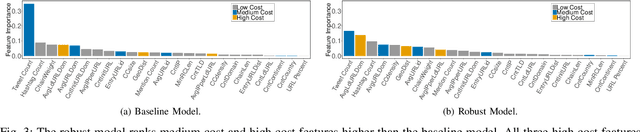
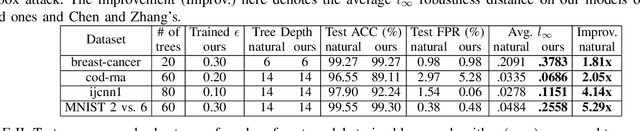
Tree ensemble models including random forests and gradient boosted decision trees, are widely used as security classifiers to detect malware, phishing, scam, social engineering, etc. However, the robustness of tree ensembles has not been thoroughly studied. Existing approaches mainly focus on adding more robust features and conducting feature ablation study, which do not provide robustness guarantee against strong adversaries. In this paper, we propose a new algorithm to train robust tree ensembles. Robust training maximizes the defender's gain as if the adversary is trying to minimize that. We design a general algorithm based on greedy heuristic to find better solutions to the minimization problem than previous work. We implement the algorithm for gradient boosted decision trees in xgboost and random forests in scikit-learn. Our evaluation over benchmark datasets show that, we can train more robust models than the start-of-the-art robust training algorithm in gradient boosted decision trees, with a 1.26X increase in the $L_\infty$ evasion distance required for the strongest whitebox attacker. In addition, our algorithm is general across different gain metrics and types of tree ensembles. We achieve 3.32X increase in $L_\infty$ robustness distance compared to the baseline random forest training method. Furthermore, to make the robustness increase meaningful in security applications, we propose attack-cost-driven constraints for the robust training process. Our training algorithm maximizes attacker's evasion cost by integrating domain knowledge about feature manipulation costs. We use twitter spam detection as a case study to analyze attacker's cost increase to evade our robust model. Our technique can train robust model to rank robust features as most important ones, and our robust model requires about 8.4X increase in attacker's economic cost to be evaded compared to the baseline.
Bandana: Using Non-volatile Memory for Storing Deep Learning Models
Nov 15, 2018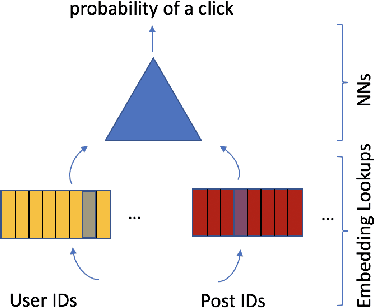
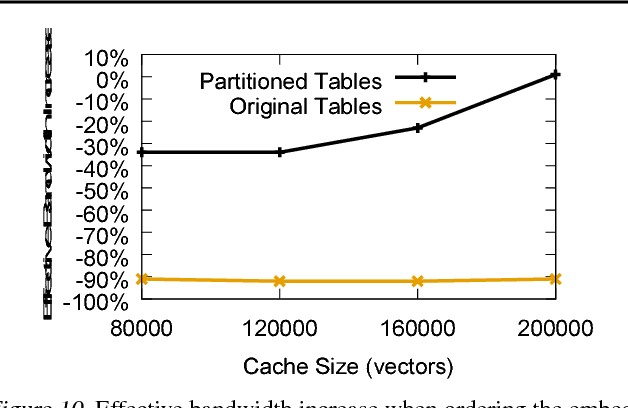
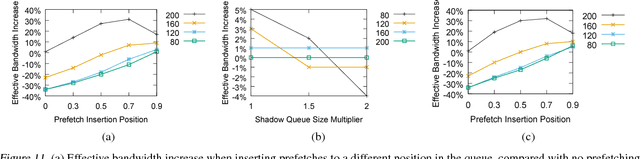
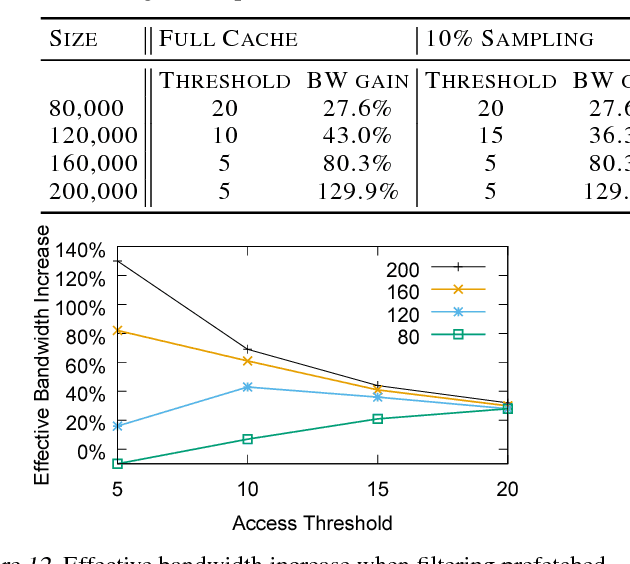
Typical large-scale recommender systems use deep learning models that are stored on a large amount of DRAM. These models often rely on embeddings, which consume most of the required memory. We present Bandana, a storage system that reduces the DRAM footprint of embeddings, by using Non-volatile Memory (NVM) as the primary storage medium, with a small amount of DRAM as cache. The main challenge in storing embeddings on NVM is its limited read bandwidth compared to DRAM. Bandana uses two primary techniques to address this limitation: first, it stores embedding vectors that are likely to be read together in the same physical location, using hypergraph partitioning, and second, it decides the number of embedding vectors to cache in DRAM by simulating dozens of small caches. These techniques allow Bandana to increase the effective read bandwidth of NVM by 2-3x and thereby significantly reduce the total cost of ownership.