 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Stop Me Now: Embedding Based Scheduling for LLMs
Oct 01, 2024



Efficient scheduling is crucial for interactive Large Language Model (LLM) applications, where low request completion time directly impacts user engagement. Size-based scheduling algorithms like Shortest Remaining Process Time (SRPT) aim to reduce average request completion time by leveraging known or estimated request sizes and allowing preemption by incoming jobs with shorter service times. However, two main challenges arise when applying size-based scheduling to LLM systems. First, accurately predicting output lengths from prompts is challenging and often resource-intensive, making it impractical for many systems. As a result, the state-of-the-art LLM systems default to first-come, first-served scheduling, which can lead to head-of-line blocking and reduced system efficiency. Second, preemption introduces extra memory overhead to LLM systems as they must maintain intermediate states for unfinished (preempted) requests. In this paper, we propose TRAIL, a method to obtain output predictions from the target LLM itself. After generating each output token, we recycle the embedding of its internal structure as input for a lightweight classifier that predicts the remaining length for each running request. Using these predictions, we propose a prediction-based SRPT variant with limited preemption designed to account for memory overhead in LLM systems. This variant allows preemption early in request execution when memory consumption is low but restricts preemption as requests approach completion to optimize resource utilization. On the theoretical side, we derive a closed-form formula for this SRPT variant in an M/G/1 queue model, which demonstrates its potential value. In our system, we implement this preemption policy alongside our embedding-based prediction method.
Training Robust Tree Ensembles for Security
Dec 03, 2019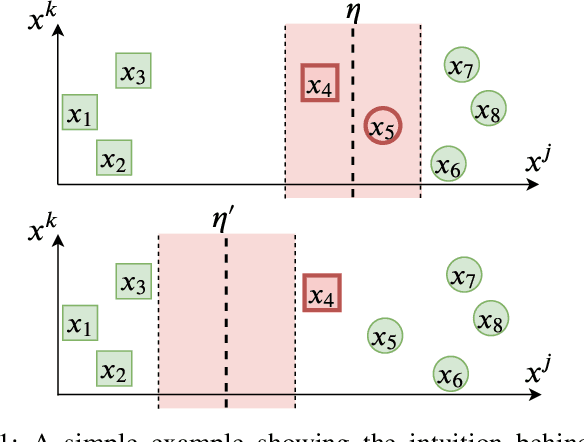
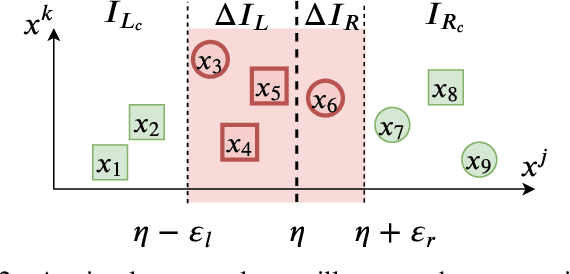
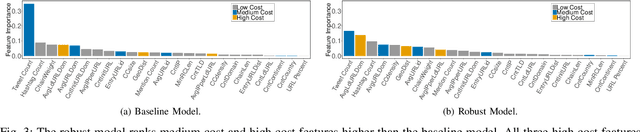
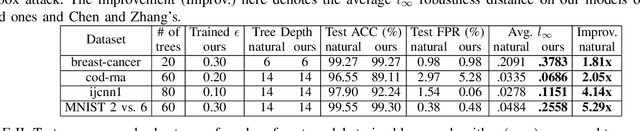
Tree ensemble models including random forests and gradient boosted decision trees, are widely used as security classifiers to detect malware, phishing, scam, social engineering, etc. However, the robustness of tree ensembles has not been thoroughly studied. Existing approaches mainly focus on adding more robust features and conducting feature ablation study, which do not provide robustness guarantee against strong adversaries. In this paper, we propose a new algorithm to train robust tree ensembles. Robust training maximizes the defender's gain as if the adversary is trying to minimize that. We design a general algorithm based on greedy heuristic to find better solutions to the minimization problem than previous work. We implement the algorithm for gradient boosted decision trees in xgboost and random forests in scikit-learn. Our evaluation over benchmark datasets show that, we can train more robust models than the start-of-the-art robust training algorithm in gradient boosted decision trees, with a 1.26X increase in the $L_\infty$ evasion distance required for the strongest whitebox attacker. In addition, our algorithm is general across different gain metrics and types of tree ensembles. We achieve 3.32X increase in $L_\infty$ robustness distance compared to the baseline random forest training method. Furthermore, to make the robustness increase meaningful in security applications, we propose attack-cost-driven constraints for the robust training process. Our training algorithm maximizes attacker's evasion cost by integrating domain knowledge about feature manipulation costs. We use twitter spam detection as a case study to analyze attacker's cost increase to evade our robust model. Our technique can train robust model to rank robust features as most important ones, and our robust model requires about 8.4X increase in attacker's economic cost to be evaded compared to the baseline.