 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkspace-Bench 1.0: Benchmarking AI Agents on Workspace Tasks with Large-Scale File Dependencies
May 05, 2026Workspace learning requires AI agents to identify, reason over, exploit, and update explicit and implicit dependencies among heterogeneous files in a worker's workspace, enabling them to complete both routine and advanced tasks effectively. Despite its importance, existing relevant benchmarks largely evaluate agents on pre-specified or synthesized files with limited real-world dependencies, leaving workspace-level evaluation underexplored. To this end, we introduce Workspace-Bench, a benchmark for evaluating AI agents on Workspace Learning invOlving Large-Scale File Dependencies. We construct realistic workspaces with 5 worker profiles, 74 file types, 20,476 files (up to 20GB) and curate 388 tasks, each with its own file dependency graph, evaluated across 7,399 total rubrics that require cross-file retrieval, contextual reasoning, and adaptive decision-making. We further provide Workspace-Bench-Lite, a 100-task subset that preserves the benchmark distribution while reducing evaluation costs by about 70%. We evaluate 4 popular agent harnesses and 7 foundation models. Experimental results show that current agents remain far from reliable workspace learning, where the best reaches only 68.7%, substantially below the human result of 80.7%, and the average performance across agents is only 47.4%.
SA-CycleGAN-2.5D: Self-Attention CycleGAN with Tri-Planar Context for Multi-Site MRI Harmonization
Mar 17, 2026Multi-site neuroimaging analysis is fundamentally confounded by scanner-induced covariate shifts, where the marginal distribution of voxel intensities $P(\mathbf{x})$ varies non-linearly across acquisition protocols while the conditional anatomy $P(\mathbf{y}|\mathbf{x})$ remains constant. This is particularly detrimental to radiomic reproducibility, where acquisition variance often exceeds biological pathology variance. Existing statistical harmonization methods (e.g., ComBat) operate in feature space, precluding spatial downstream tasks, while standard deep learning approaches are theoretically bounded by local effective receptive fields (ERF), failing to model the global intensity correlations characteristic of field-strength bias. We propose SA-CycleGAN-2.5D, a domain adaptation framework motivated by the $HΔH$-divergence bound of Ben-David et al., integrating three architectural innovations: (1) A 2.5D tri-planar manifold injection preserving through-plane gradients $\nabla_z$ at $O(HW)$ complexity; (2) A U-ResNet generator with dense voxel-to-voxel self-attention, surpassing the $O(\sqrt{L})$ receptive field limit of CNNs to model global scanner field biases; and (3) A spectrally-normalized discriminator constraining the Lipschitz constant ($K_D \le 1$) for stable adversarial optimization. Evaluated on 654 glioma patients across two institutional domains (BraTS and UPenn-GBM), our method reduces Maximum Mean Discrepancy (MMD) by 99.1% ($1.729 \to 0.015$) and degrades domain classifier accuracy to near-chance (59.7%). Ablation confirms that global attention is statistically essential (Cohen's $d = 1.32$, $p < 0.001$) for the harder heterogeneous-to-homogeneous translation direction. By bridging 2D efficiency and 3D consistency, our framework yields voxel-level harmonized images that preserve tumor pathophysiology, enabling reproducible multi-center radiomic analysis.
Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs
Jan 22, 2026Data preparation aims to denoise raw datasets, uncover cross-dataset relationships, and extract valuable insights from them, which is essential for a wide range of data-centric applications. Driven by (i) rising demands for application-ready data (e.g., for analytics, visualization, decision-making), (ii) increasingly powerful LLM techniques, and (iii) the emergence of infrastructures that facilitate flexible agent construction (e.g., using Databricks Unity Catalog), LLM-enhanced methods are rapidly becoming a transformative and potentially dominant paradigm for data preparation. By investigating hundreds of recent literature works, this paper presents a systematic review of this evolving landscape, focusing on the use of LLM techniques to prepare data for diverse downstream tasks. First, we characterize the fundamental paradigm shift, from rule-based, model-specific pipelines to prompt-driven, context-aware, and agentic preparation workflows. Next, we introduce a task-centric taxonomy that organizes the field into three major tasks: data cleaning (e.g., standardization, error processing, imputation), data integration (e.g., entity matching, schema matching), and data enrichment (e.g., data annotation, profiling). For each task, we survey representative techniques, and highlight their respective strengths (e.g., improved generalization, semantic understanding) and limitations (e.g., the prohibitive cost of scaling LLMs, persistent hallucinations even in advanced agents, the mismatch between advanced methods and weak evaluation). Moreover, we analyze commonly used datasets and evaluation metrics (the empirical part). Finally, we discuss open research challenges and outline a forward-looking roadmap that emphasizes scalable LLM-data systems, principled designs for reliable agentic workflows, and robust evaluation protocols.
Abacus: A Cost-Based Optimizer for Semantic Operator Systems
May 20, 2025LLMs enable an exciting new class of data processing applications over large collections of unstructured documents. Several new programming frameworks have enabled developers to build these applications by composing them out of semantic operators: a declarative set of AI-powered data transformations with natural language specifications. These include LLM-powered maps, filters, joins, etc. used for document processing tasks such as information extraction, summarization, and more. While systems of semantic operators have achieved strong performance on benchmarks, they can be difficult to optimize. An optimizer for this setting must determine how to physically implement each semantic operator in a way that optimizes the system globally. Existing optimizers are limited in the number of optimizations they can apply, and most (if not all) cannot optimize system quality, cost, or latency subject to constraint(s) on the other dimensions. In this paper we present Abacus, an extensible, cost-based optimizer which searches for the best implementation of a semantic operator system given a (possibly constrained) optimization objective. Abacus estimates operator performance by leveraging a minimal set of validation examples and, if available, prior beliefs about operator performance. We evaluate Abacus on document processing workloads in the biomedical and legal domains (BioDEX; CUAD) and multi-modal question answering (MMQA). We demonstrate that systems optimized by Abacus achieve 18.7%-39.2% better quality and up to 23.6x lower cost and 4.2x lower latency than the next best system.
PalimpChat: Declarative and Interactive AI analytics
Feb 05, 2025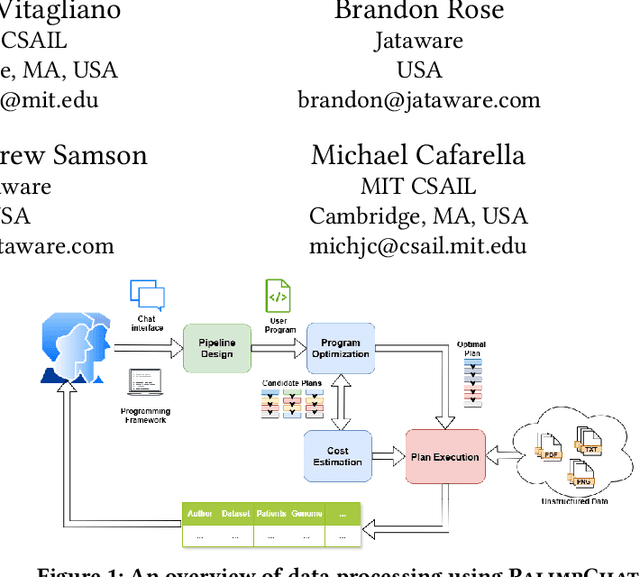

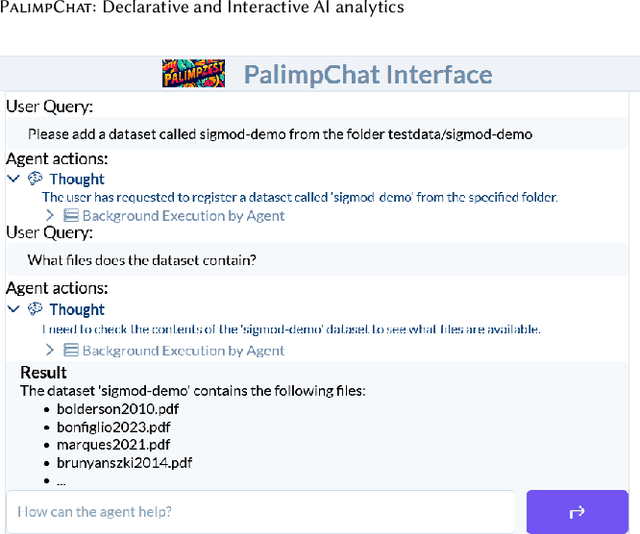
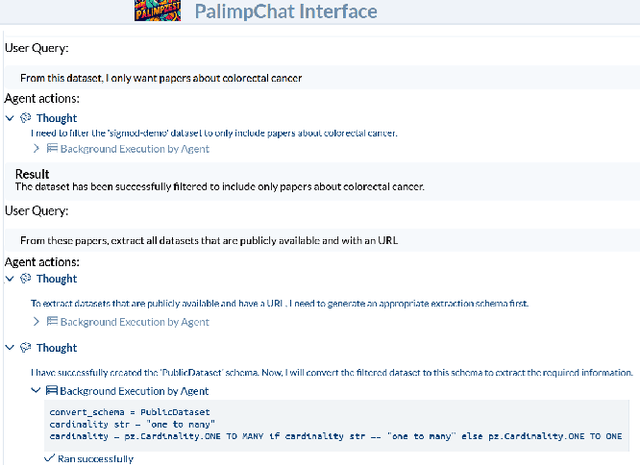
Thanks to the advances in generative architectures and large language models, data scientists can now code pipelines of machine-learning operations to process large collections of unstructured data. Recent progress has seen the rise of declarative AI frameworks (e.g., Palimpzest, Lotus, and DocETL) to build optimized and increasingly complex pipelines, but these systems often remain accessible only to expert programmers. In this demonstration, we present PalimpChat, a chat-based interface to Palimpzest that bridges this gap by letting users create and run sophisticated AI pipelines through natural language alone. By integrating Archytas, a ReAct-based reasoning agent, and Palimpzest's suite of relational and LLM-based operators, PalimpChat provides a practical illustration of how a chat interface can make declarative AI frameworks truly accessible to non-experts. Our demo system is publicly available online. At SIGMOD'25, participants can explore three real-world scenarios--scientific discovery, legal discovery, and real estate search--or apply PalimpChat to their own datasets. In this paper, we focus on how PalimpChat, supported by the Palimpzest optimizer, simplifies complex AI workflows such as extracting and analyzing biomedical data.
Improving DBMS Scheduling Decisions with Fine-grained Performance Prediction on Concurrent Queries -- Extended
Jan 27, 2025Query scheduling is a critical task that directly impacts query performance in database management systems (DBMS). Deeply integrated schedulers, which require changes to DBMS internals, are usually customized for a specific engine and can take months to implement. In contrast, non-intrusive schedulers make coarse-grained decisions, such as controlling query admission and re-ordering query execution, without requiring modifications to DBMS internals. They require much less engineering effort and can be applied across a wide range of DBMS engines, offering immediate benefits to end users. However, most existing non-intrusive scheduling systems rely on simplified cost models and heuristics that cannot accurately model query interactions under concurrency and different system states, possibly leading to suboptimal scheduling decisions. This work introduces IconqSched, a new, principled non-intrusive scheduler that optimizes the execution order and timing of queries to enhance total end-to-end runtime as experienced by the user query queuing time plus system runtime. Unlike previous approaches, IconqSched features a novel fine-grained predictor, Iconq, which treats the DBMS as a black box and accurately estimates the system runtime of concurrently executed queries under different system states. Using these predictions, IconqSched is able to capture system runtime variations across different query mixes and system loads. It then employs a greedy scheduling algorithm to effectively determine which queries to submit and when to submit them. We compare IconqSched to other schedulers in terms of end-to-end runtime using real workload traces. On Postgres, IconqSched reduces end-to-end runtime by 16.2%-28.2% on average and 33.6%-38.9% in the tail. Similarly, on Redshift, it reduces end-to-end runtime by 10.3%-14.1% on average and 14.9%-22.2% in the tail.
Variable Extraction for Model Recovery in Scientific Literature
Nov 21, 2024
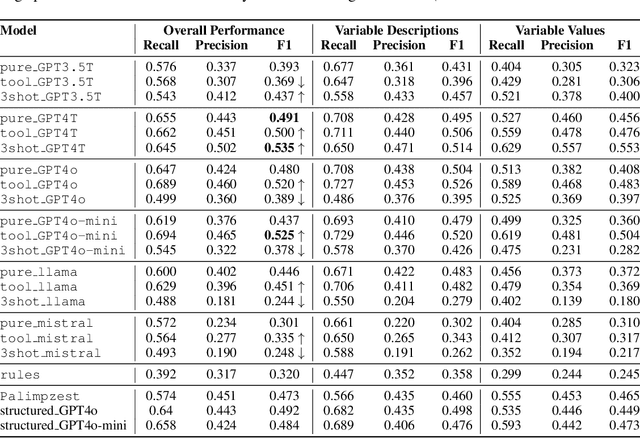


The global output of academic publications exceeds 5 million articles per year, making it difficult for humans to keep up with even a tiny fraction of scientific output. We need methods to navigate and interpret the artifacts -- texts, graphs, charts, code, models, and datasets -- that make up the literature. This paper evaluates various methods for extracting mathematical model variables from epidemiological studies, such as ``infection rate ($\alpha$),'' ``recovery rate ($\gamma$),'' and ``mortality rate ($\mu$).'' Variable extraction appears to be a basic task, but plays a pivotal role in recovering models from scientific literature. Once extracted, we can use these variables for automatic mathematical modeling, simulation, and replication of published results. We introduce a benchmark dataset comprising manually-annotated variable descriptions and variable values extracted from scientific papers. Based on this dataset, we present several baseline methods for variable extraction based on Large Language Models (LLMs) and rule-based information extraction systems. Our analysis shows that LLM-based solutions perform the best. Despite the incremental benefits of combining rule-based extraction outputs with LLMs, the leap in performance attributed to the transfer-learning and instruction-tuning capabilities of LLMs themselves is far more significant. This investigation demonstrates the potential of LLMs to enhance automatic comprehension of scientific artifacts and for automatic model recovery and simulation.
Don't Stop Me Now: Embedding Based Scheduling for LLMs
Oct 01, 2024



Efficient scheduling is crucial for interactive Large Language Model (LLM) applications, where low request completion time directly impacts user engagement. Size-based scheduling algorithms like Shortest Remaining Process Time (SRPT) aim to reduce average request completion time by leveraging known or estimated request sizes and allowing preemption by incoming jobs with shorter service times. However, two main challenges arise when applying size-based scheduling to LLM systems. First, accurately predicting output lengths from prompts is challenging and often resource-intensive, making it impractical for many systems. As a result, the state-of-the-art LLM systems default to first-come, first-served scheduling, which can lead to head-of-line blocking and reduced system efficiency. Second, preemption introduces extra memory overhead to LLM systems as they must maintain intermediate states for unfinished (preempted) requests. In this paper, we propose TRAIL, a method to obtain output predictions from the target LLM itself. After generating each output token, we recycle the embedding of its internal structure as input for a lightweight classifier that predicts the remaining length for each running request. Using these predictions, we propose a prediction-based SRPT variant with limited preemption designed to account for memory overhead in LLM systems. This variant allows preemption early in request execution when memory consumption is low but restricts preemption as requests approach completion to optimize resource utilization. On the theoretical side, we derive a closed-form formula for this SRPT variant in an M/G/1 queue model, which demonstrates its potential value. In our system, we implement this preemption policy alongside our embedding-based prediction method.
MDCR: A Dataset for Multi-Document Conditional Reasoning
Jun 17, 2024The same real-life questions posed to different individuals may lead to different answers based on their unique situations. For instance, whether a student is eligible for a scholarship depends on eligibility conditions, such as major or degree required. ConditionalQA was proposed to evaluate models' capability of reading a document and answering eligibility questions, considering unmentioned conditions. However, it is limited to questions on single documents, neglecting harder cases that may require cross-document reasoning and optimization, for example, "What is the maximum number of scholarships attainable?" Such questions over multiple documents are not only more challenging due to more context having to understand, but also because the model has to (1) explore all possible combinations of unmentioned conditions and (2) understand the relationship between conditions across documents, to reason about the optimal outcome. To evaluate models' capability of answering such questions, we propose a new dataset MDCR, which can reflect real-world challenges and serve as a new test bed for complex conditional reasoning that requires optimization. We evaluate this dataset using the most recent LLMs and demonstrate their limitations in solving this task. We believe this dataset will facilitate future research in answering optimization questions with unknown conditions.
A Declarative System for Optimizing AI Workloads
May 23, 2024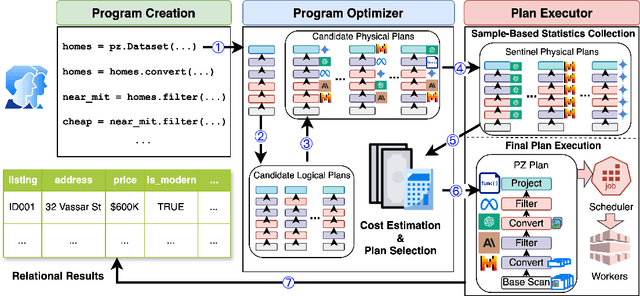
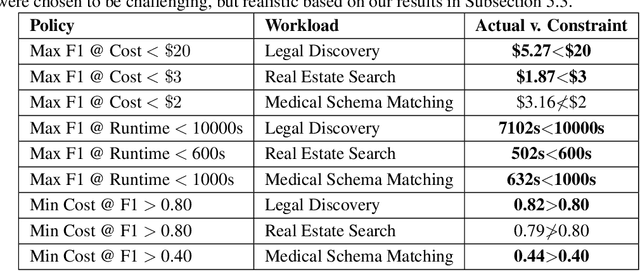
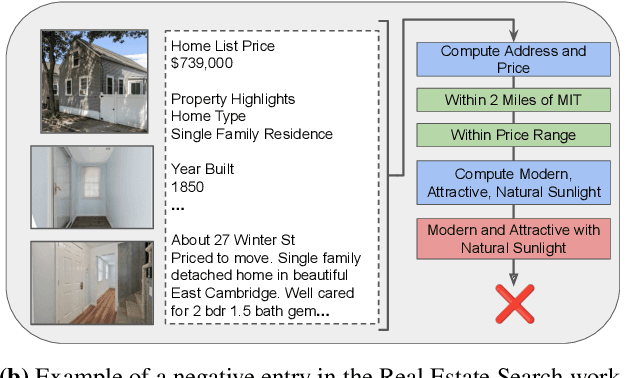
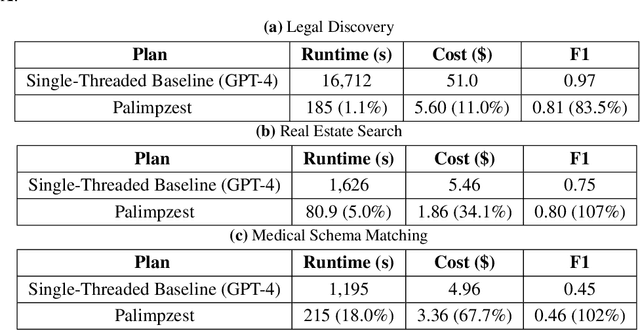
Modern AI models provide the key to a long-standing dream: processing analytical queries about almost any kind of data. Until recently, it was difficult and expensive to extract facts from company documents, data from scientific papers, or insights from image and video corpora. Today's models can accomplish these tasks with high accuracy. However, a programmer who wants to answer a substantive AI-powered query must orchestrate large numbers of models, prompts, and data operations. For even a single query, the programmer has to make a vast number of decisions such as the choice of model, the right inference method, the most cost-effective inference hardware, the ideal prompt design, and so on. The optimal set of decisions can change as the query changes and as the rapidly-evolving technical landscape shifts. In this paper we present Palimpzest, a system that enables anyone to process AI-powered analytical queries simply by defining them in a declarative language. The system uses its cost optimization framework -- which explores the search space of AI models, prompting techniques, and related foundation model optimizations -- to implement the query with the best trade-offs between runtime, financial cost, and output data quality. We describe the workload of AI-powered analytics tasks, the optimization methods that Palimpzest uses, and the prototype system itself. We evaluate Palimpzest on tasks in Legal Discovery, Real Estate Search, and Medical Schema Matching. We show that even our simple prototype offers a range of appealing plans, including one that is 3.3x faster, 2.9x cheaper, and offers better data quality than the baseline method. With parallelism enabled, Palimpzest can produce plans with up to a 90.3x speedup at 9.1x lower cost relative to a single-threaded GPT-4 baseline, while obtaining an F1-score within 83.5% of the baseline. These require no additional work by the user.