 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable Extraction for Model Recovery in Scientific Literature
Nov 21, 2024
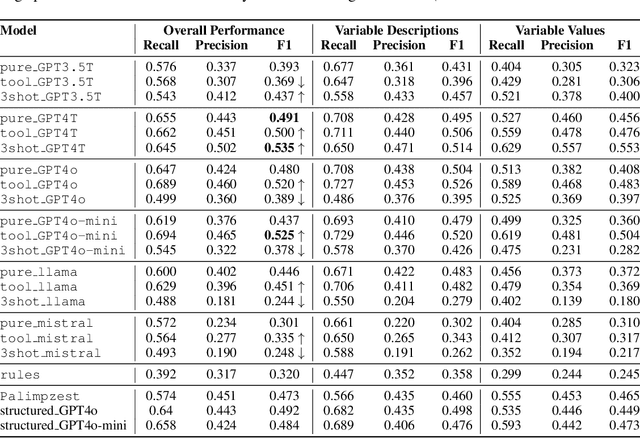


The global output of academic publications exceeds 5 million articles per year, making it difficult for humans to keep up with even a tiny fraction of scientific output. We need methods to navigate and interpret the artifacts -- texts, graphs, charts, code, models, and datasets -- that make up the literature. This paper evaluates various methods for extracting mathematical model variables from epidemiological studies, such as ``infection rate ($\alpha$),'' ``recovery rate ($\gamma$),'' and ``mortality rate ($\mu$).'' Variable extraction appears to be a basic task, but plays a pivotal role in recovering models from scientific literature. Once extracted, we can use these variables for automatic mathematical modeling, simulation, and replication of published results. We introduce a benchmark dataset comprising manually-annotated variable descriptions and variable values extracted from scientific papers. Based on this dataset, we present several baseline methods for variable extraction based on Large Language Models (LLMs) and rule-based information extraction systems. Our analysis shows that LLM-based solutions perform the best. Despite the incremental benefits of combining rule-based extraction outputs with LLMs, the leap in performance attributed to the transfer-learning and instruction-tuning capabilities of LLMs themselves is far more significant. This investigation demonstrates the potential of LLMs to enhance automatic comprehension of scientific artifacts and for automatic model recovery and simulation.