 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable Extraction for Model Recovery in Scientific Literature
Nov 21, 2024
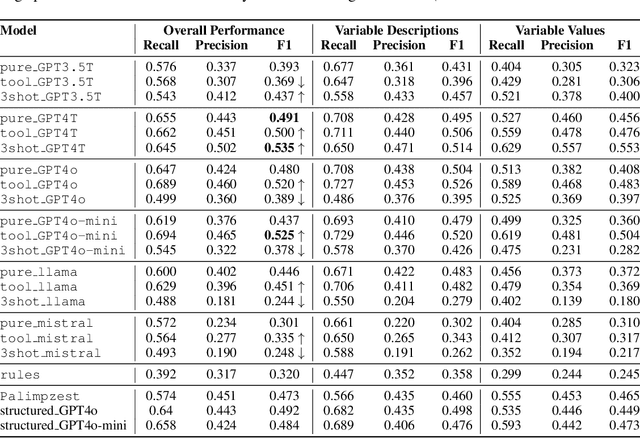


The global output of academic publications exceeds 5 million articles per year, making it difficult for humans to keep up with even a tiny fraction of scientific output. We need methods to navigate and interpret the artifacts -- texts, graphs, charts, code, models, and datasets -- that make up the literature. This paper evaluates various methods for extracting mathematical model variables from epidemiological studies, such as ``infection rate ($\alpha$),'' ``recovery rate ($\gamma$),'' and ``mortality rate ($\mu$).'' Variable extraction appears to be a basic task, but plays a pivotal role in recovering models from scientific literature. Once extracted, we can use these variables for automatic mathematical modeling, simulation, and replication of published results. We introduce a benchmark dataset comprising manually-annotated variable descriptions and variable values extracted from scientific papers. Based on this dataset, we present several baseline methods for variable extraction based on Large Language Models (LLMs) and rule-based information extraction systems. Our analysis shows that LLM-based solutions perform the best. Despite the incremental benefits of combining rule-based extraction outputs with LLMs, the leap in performance attributed to the transfer-learning and instruction-tuning capabilities of LLMs themselves is far more significant. This investigation demonstrates the potential of LLMs to enhance automatic comprehension of scientific artifacts and for automatic model recovery and simulation.
When and Where Did it Happen? An Encoder-Decoder Model to Identify Scenario Context
Oct 10, 2024



We introduce a neural architecture finetuned for the task of scenario context generation: The relevant location and time of an event or entity mentioned in text. Contextualizing information extraction helps to scope the validity of automated finings when aggregating them as knowledge graphs. Our approach uses a high-quality curated dataset of time and location annotations in a corpus of epidemiology papers to train an encoder-decoder architecture. We also explored the use of data augmentation techniques during training. Our findings suggest that a relatively small fine-tuned encoder-decoder model performs better than out-of-the-box LLMs and semantic role labeling parsers to accurate predict the relevant scenario information of a particular entity or event.
Exploring Semantic Clustering in Deep Reinforcement Learning for Video Games
Sep 25, 2024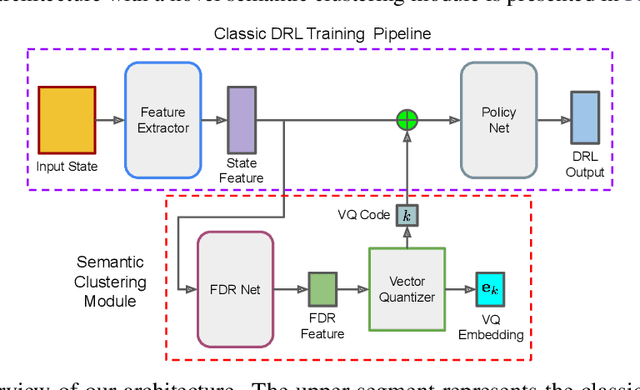
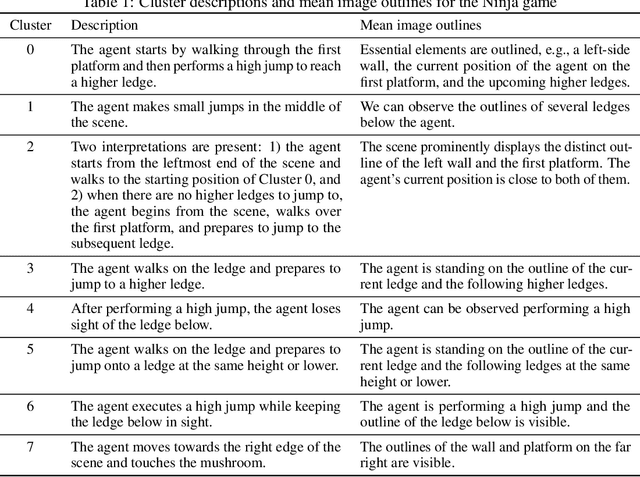
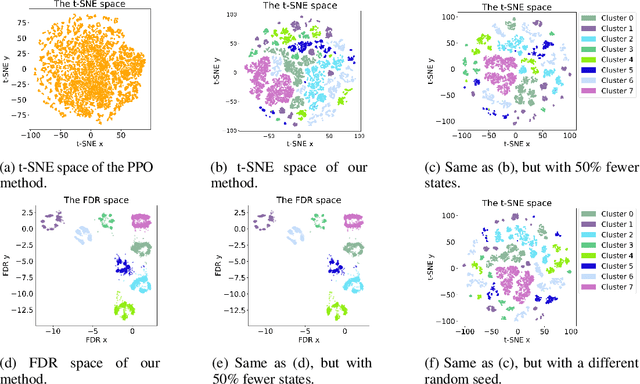

In this paper, we investigate the semantic clustering properties of deep reinforcement learning (DRL) for video games, enriching our understanding of the internal dynamics of DRL and advancing its interpretability. In this context, semantic clustering refers to the inherent capacity of neural networks to internally group video inputs based on semantic similarity. To achieve this, we propose a novel DRL architecture that integrates a semantic clustering module featuring both feature dimensionality reduction and online clustering. This module seamlessly integrates into the DRL training pipeline, addressing instability issues observed in previous t-SNE-based analysis methods and eliminating the necessity for extensive manual annotation of semantic analysis. Through experiments, we validate the effectiveness of the proposed module and the semantic clustering properties in DRL for video games. Additionally, based on these properties, we introduce new analytical methods to help understand the hierarchical structure of policies and the semantic distribution within the feature space.
Probabilistic Modeling of Human Teams to Infer False Beliefs
Oct 19, 2023



We develop a probabilistic graphical model (PGM) for artificially intelligent (AI) agents to infer human beliefs during a simulated urban search and rescue (USAR) scenario executed in a Minecraft environment with a team of three players. The PGM approach makes observable states and actions explicit, as well as beliefs and intentions grounded by evidence about what players see and do over time. This approach also supports inferring the effect of interventions, which are vital if AI agents are to assist human teams. The experiment incorporates manipulations of players' knowledge, and the virtual Minecraft-based testbed provides access to several streams of information, including the objects in the players' field of view. The participants are equipped with a set of marker blocks that can be placed near room entrances to signal the presence or absence of victims in the rooms to their teammates. In each team, one of the members is given a different legend for the markers than the other two, which may mislead them about the state of the rooms; that is, they will hold a false belief. We extend previous works in this field by introducing ToMCAT, an AI agent that can reason about individual and shared mental states. We find that the players' behaviors are affected by what they see in their in-game field of view, their beliefs about the meaning of the markers, and their beliefs about which meaning the team decided to adopt. In addition, we show that ToMCAT's beliefs are consistent with the players' actions and that it can infer false beliefs with accuracy significantly better than chance and comparable to inferences made by human observers.
Multi-Timescale Modeling of Human Behavior
Nov 16, 2022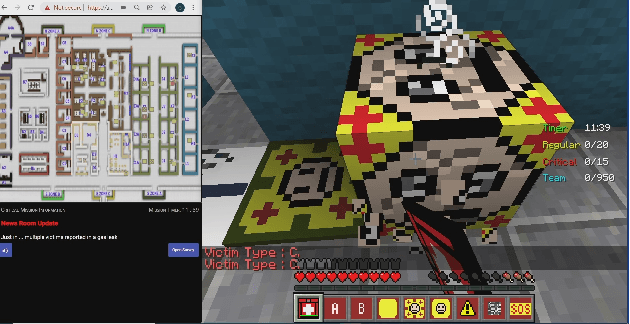

In recent years, the role of artificially intelligent (AI) agents has evolved from being basic tools to socially intelligent agents working alongside humans towards common goals. In such scenarios, the ability to predict future behavior by observing past actions of their human teammates is highly desirable in an AI agent. Goal-oriented human behavior is complex, hierarchical, and unfolds across multiple timescales. Despite this observation, relatively little attention has been paid towards using multi-timescale features to model such behavior. In this paper, we propose an LSTM network architecture that processes behavioral information at multiple timescales to predict future behavior. We demonstrate that our approach for modeling behavior in multiple timescales substantially improves prediction of future behavior compared to methods that do not model behavior at multiple timescales. We evaluate our architecture on data collected in an urban search and rescue scenario simulated in a virtual Minecraft-based testbed, and compare its performance to that of a number of valid baselines as well as other methods that do not process inputs at multiple timescales.
Using Features at Multiple Temporal and Spatial Resolutions to Predict Human Behavior in Real Time
Nov 12, 2022



When performing complex tasks, humans naturally reason at multiple temporal and spatial resolutions simultaneously. We contend that for an artificially intelligent agent to effectively model human teammates, i.e., demonstrate computational theory of mind (ToM), it should do the same. In this paper, we present an approach for integrating high and low-resolution spatial and temporal information to predict human behavior in real time and evaluate it on data collected from human subjects performing simulated urban search and rescue (USAR) missions in a Minecraft-based environment. Our model composes neural networks for high and low-resolution feature extraction with a neural network for behavior prediction, with all three networks trained simultaneously. The high-resolution extractor encodes dynamically changing goals robustly by taking as input the Manhattan distance difference between the humans' Minecraft avatars and candidate goals in the environment for the latest few actions, computed from a high-resolution gridworld representation. In contrast, the low-resolution extractor encodes participants' historical behavior using a historical state matrix computed from a low-resolution graph representation. Through supervised learning, our model acquires a robust prior for human behavior prediction, and can effectively deal with long-term observations. Our experimental results demonstrate that our method significantly improves prediction accuracy compared to approaches that only use high-resolution information.
Deep Reinforcement Learning with Vector Quantized Encoding
Nov 12, 2022


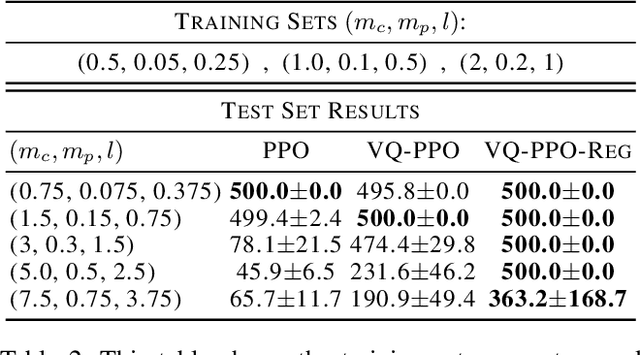
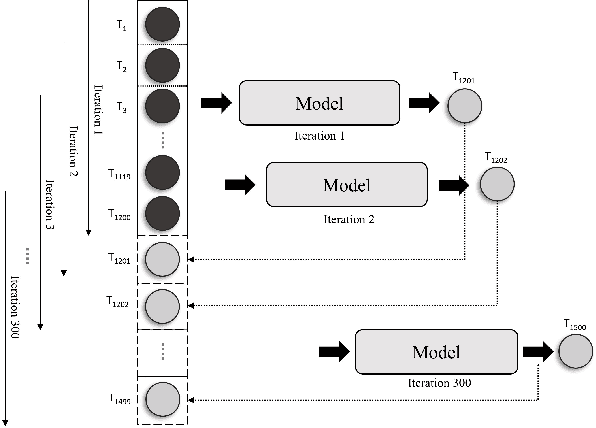
Human decision-making often involves combining similar states into categories and reasoning at the level of the categories rather than the actual states. Guided by this intuition, we propose a novel method for clustering state features in deep reinforcement learning (RL) methods to improve their interpretability. Specifically, we propose a plug-and-play framework termed \emph{vector quantized reinforcement learning} (VQ-RL) that extends classic RL pipelines with an auxiliary classification task based on vector quantized (VQ) encoding and aligns with policy training. The VQ encoding method categorizes features with similar semantics into clusters and results in tighter clusters with better separation compared to classic deep RL methods, thus enabling neural models to learn similarities and differences between states better. Furthermore, we introduce two regularization methods to help increase the separation between clusters and avoid the risks associated with VQ training. In simulations, we demonstrate that VQ-RL improves interpretability and investigate its impact on robustness and generalization of deep RL.
Modular Procedural Generation for Voxel Maps
Apr 18, 2021

Task environments developed in Minecraft are becoming increasingly popular for artificial intelligence (AI) research. However, most of these are currently constructed manually, thus failing to take advantage of procedural content generation (PCG), a capability unique to virtual task environments. In this paper, we present mcg, an open-source library to facilitate implementing PCG algorithms for voxel-based environments such as Minecraft. The library is designed with human-machine teaming research in mind, and thus takes a 'top-down' approach to generation, simultaneously generating low and high level machine-readable representations that are suitable for empirical research. These can be consumed by downstream AI applications that consider human spatial cognition. The benefits of this approach include rapid, scalable, and efficient development of virtual environments, the ability to control the statistics of the environment at a semantic level, and the ability to generate novel environments in response to player actions in real time.
AutoMATES: Automated Model Assembly from Text, Equations, and Software
Jan 21, 2020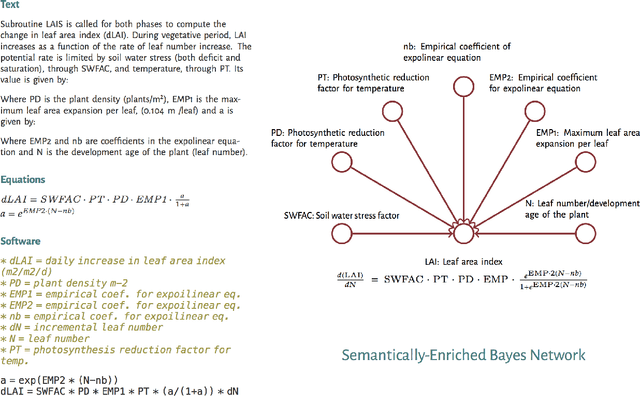
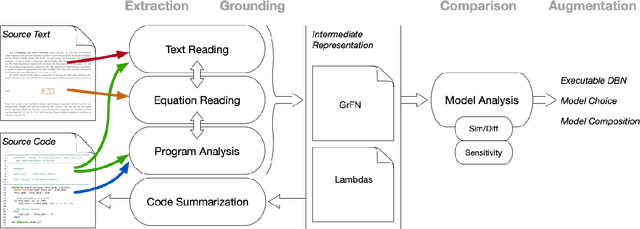

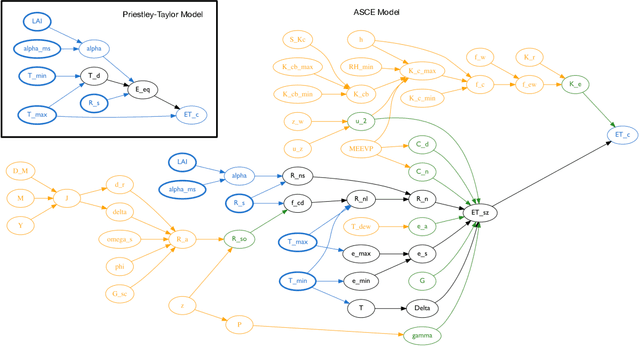
Models of complicated systems can be represented in different ways - in scientific papers, they are represented using natural language text as well as equations. But to be of real use, they must also be implemented as software, thus making code a third form of representing models. We introduce the AutoMATES project, which aims to build semantically-rich unified representations of models from scientific code and publications to facilitate the integration of computational models from different domains and allow for modeling large, complicated systems that span multiple domains and levels of abstraction.