 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Examples to Rules: Neural Guided Rule Synthesis for Information Extraction
Jan 16, 2022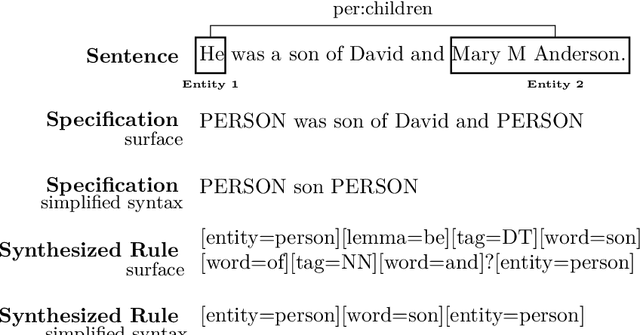
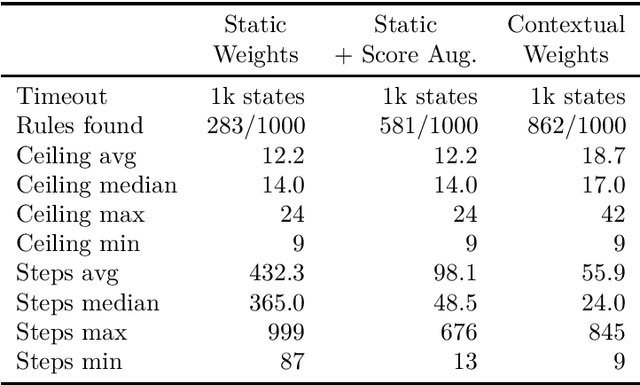


While deep learning approaches to information extraction have had many successes, they can be difficult to augment or maintain as needs shift. Rule-based methods, on the other hand, can be more easily modified. However, crafting rules requires expertise in linguistics and the domain of interest, making it infeasible for most users. Here we attempt to combine the advantages of these two directions while mitigating their drawbacks. We adapt recent advances from the adjacent field of program synthesis to information extraction, synthesizing rules from provided examples. We use a transformer-based architecture to guide an enumerative search, and show that this reduces the number of steps that need to be explored before a rule is found. Further, we show that without training the synthesis algorithm on the specific domain, our synthesized rules achieve state-of-the-art performance on the 1-shot scenario of a task that focuses on few-shot learning for relation classification, and competitive performance in the 5-shot scenario.
AutoMATES: Automated Model Assembly from Text, Equations, and Software
Jan 21, 2020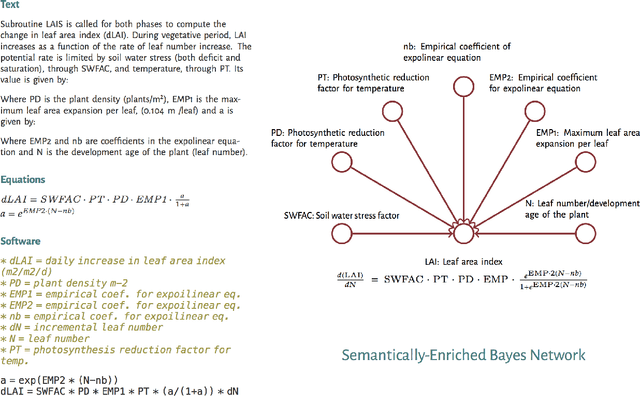
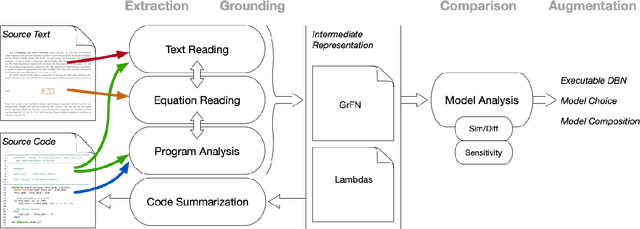

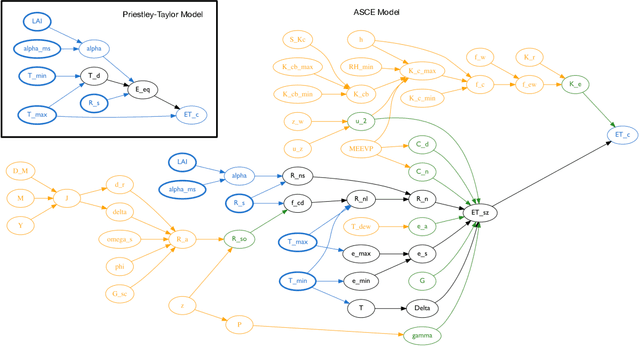
Models of complicated systems can be represented in different ways - in scientific papers, they are represented using natural language text as well as equations. But to be of real use, they must also be implemented as software, thus making code a third form of representing models. We introduce the AutoMATES project, which aims to build semantically-rich unified representations of models from scientific code and publications to facilitate the integration of computational models from different domains and allow for modeling large, complicated systems that span multiple domains and levels of abstraction.
On the Importance of Delexicalization for Fact Verification
Sep 21, 2019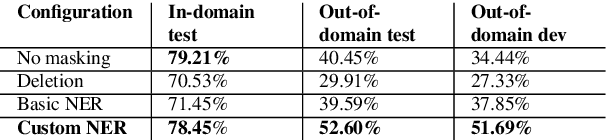
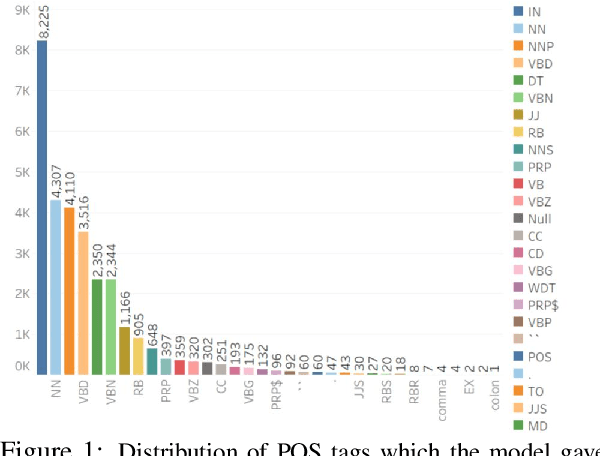
In this work we aim to understand and estimate the importance that a neural network assigns to various aspects of the data while learning and making predictions. Here we focus on the recognizing textual entailment (RTE) task and its application to fact verification. In this context, the contributions of this work are as follows. We investigate the attention weights a state of the art RTE method assigns to input tokens in the RTE component of fact verification systems, and confirm that most of the weight is assigned to POS tags of nouns (e.g., NN, NNP etc.) or their phrases. To verify that these lexicalized models transfer poorly, we implement a domain transfer experiment where a RTE component is trained on the FEVER data, and tested on the Fake News Challenge (FNC) dataset. As expected, even though this method achieves high accuracy when evaluated in the same domain, the performance in the target domain is poor, marginally above chance.To mitigate this dependence on lexicalized information, we experiment with several strategies for masking out names by replacing them with their semantic category, coupled with a unique identifier to mark that the same or new entities are referenced between claim and evidence. The results show that, while the performance on the FEVER dataset remains at par with that of the model trained on lexicalized data, it improves significantly when tested in the FNC dataset. Thus our experiments demonstrate that our strategy is successful in mitigating the dependency on lexical information.
Sanity Check: A Strong Alignment and Information Retrieval Baseline for Question Answering
Jul 05, 2018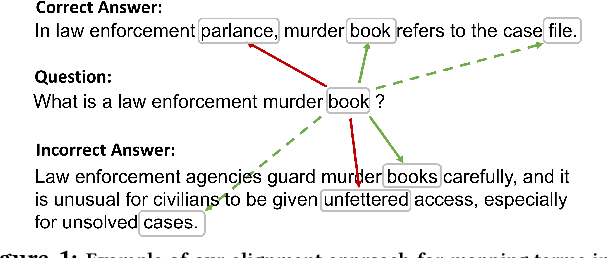

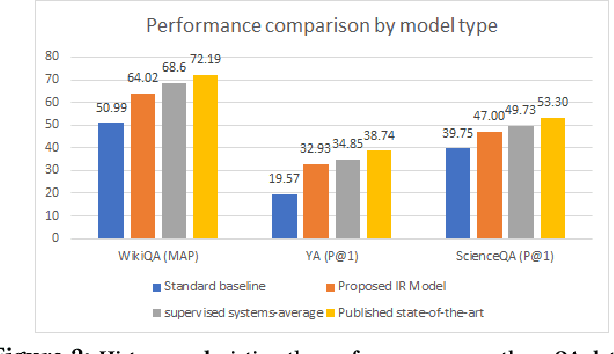

While increasingly complex approaches to question answering (QA) have been proposed, the true gain of these systems, particularly with respect to their expensive training requirements, can be inflated when they are not compared to adequate baselines. Here we propose an unsupervised, simple, and fast alignment and information retrieval baseline that incorporates two novel contributions: a \textit{one-to-many alignment} between query and document terms and \textit{negative alignment} as a proxy for discriminative information. Our approach not only outperforms all conventional baselines as well as many supervised recurrent neural networks, but also approaches the state of the art for supervised systems on three QA datasets. With only three hyperparameters, we achieve 47\% P@1 on an 8th grade Science QA dataset, 32.9\% P@1 on a Yahoo! answers QA dataset and 64\% MAP on WikiQA. We also achieve 26.56\% and 58.36\% on ARC challenge and easy dataset respectively. In addition to including the additional ARC results in this version of the paper, for the ARC easy set only we also experimented with one additional parameter -- number of justifications retrieved.
Creating Causal Embeddings for Question Answering with Minimal Supervision
Sep 26, 2016
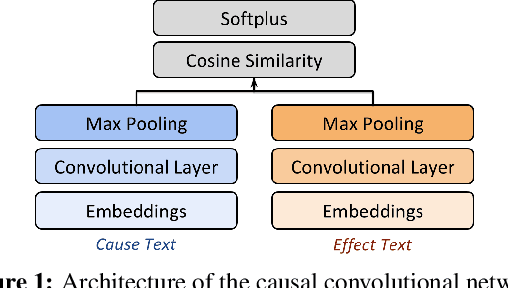
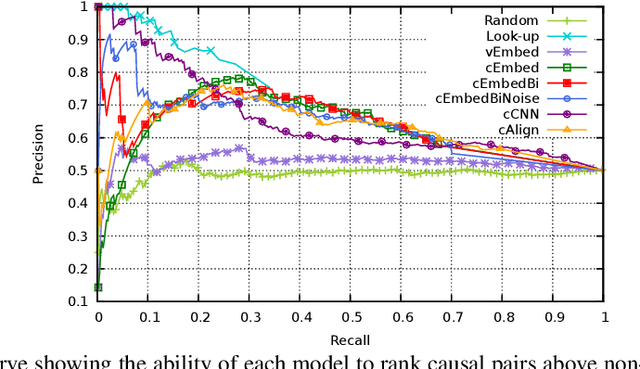
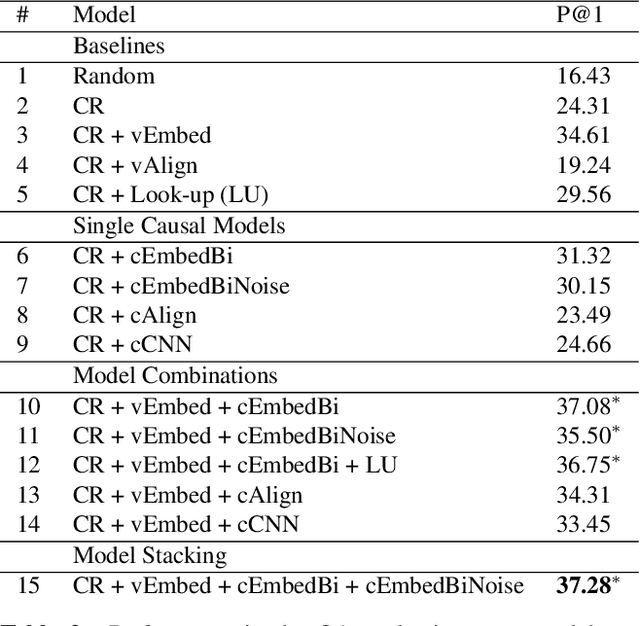
A common model for question answering (QA) is that a good answer is one that is closely related to the question, where relatedness is often determined using general-purpose lexical models such as word embeddings. We argue that a better approach is to look for answers that are related to the question in a relevant way, according to the information need of the question, which may be determined through task-specific embeddings. With causality as a use case, we implement this insight in three steps. First, we generate causal embeddings cost-effectively by bootstrapping cause-effect pairs extracted from free text using a small set of seed patterns. Second, we train dedicated embeddings over this data, by using task-specific contexts, i.e., the context of a cause is its effect. Finally, we extend a state-of-the-art reranking approach for QA to incorporate these causal embeddings. We evaluate the causal embedding models both directly with a casual implication task, and indirectly, in a downstream causal QA task using data from Yahoo! Answers. We show that explicitly modeling causality improves performance in both tasks. In the QA task our best model achieves 37.3% P@1, significantly outperforming a strong baseline by 7.7% (relative).