 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Correction of Syntactic Dependency Annotation Differences
Jan 15, 2022

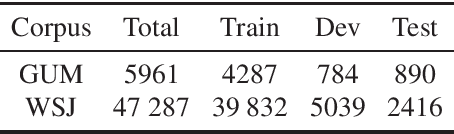

Annotation inconsistencies between data sets can cause problems for low-resource NLP, where noisy or inconsistent data cannot be as easily replaced compared with resource-rich languages. In this paper, we propose a method for automatically detecting annotation mismatches between dependency parsing corpora, as well as three related methods for automatically converting the mismatches. All three methods rely on comparing an unseen example in a new corpus with similar examples in an existing corpus. These three methods include a simple lexical replacement using the most frequent tag of the example in the existing corpus, a GloVe embedding-based replacement that considers a wider pool of examples, and a BERT embedding-based replacement that uses contextualized embeddings to provide examples fine-tuned to our specific data. We then evaluate these conversions by retraining two dependency parsers -- Stanza (Qi et al. 2020) and Parsing as Tagging (PaT) (Vacareanu et al. 2020) -- on the converted and unconverted data. We find that applying our conversions yields significantly better performance in many cases. Some differences observed between the two parsers are observed. Stanza has a more complex architecture with a quadratic algorithm, so it takes longer to train, but it can generalize better with less data. The PaT parser has a simpler architecture with a linear algorithm, speeding up training time but requiring more training data to reach comparable or better performance.
Creating Causal Embeddings for Question Answering with Minimal Supervision
Sep 26, 2016
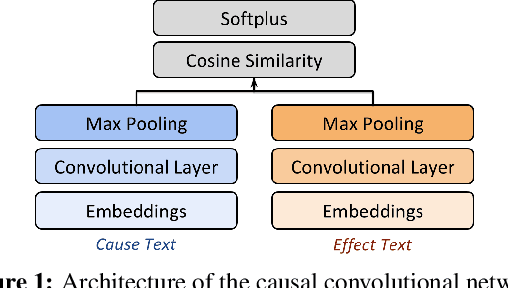
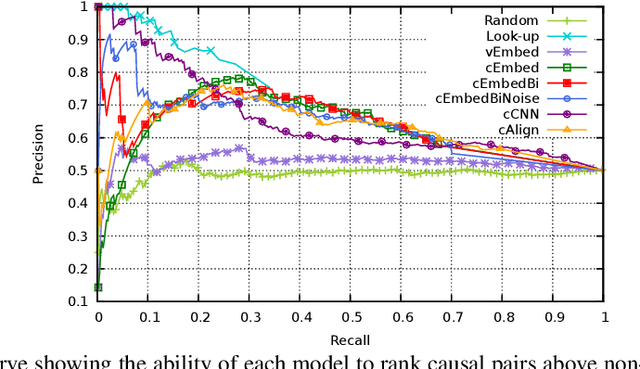
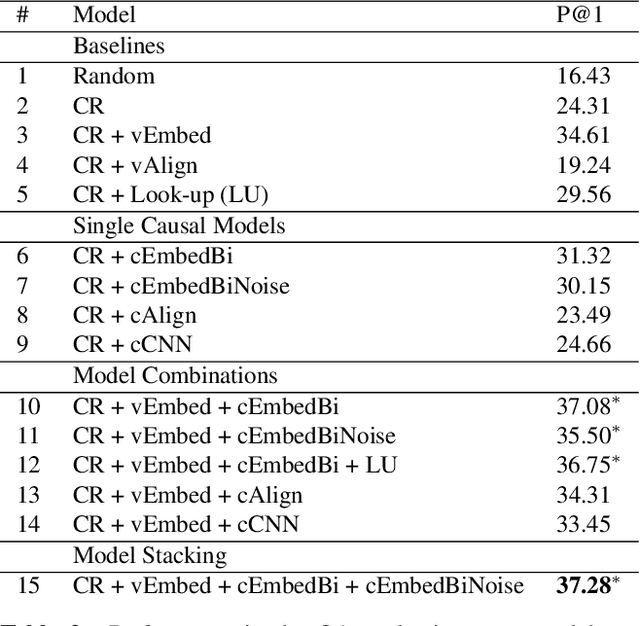
A common model for question answering (QA) is that a good answer is one that is closely related to the question, where relatedness is often determined using general-purpose lexical models such as word embeddings. We argue that a better approach is to look for answers that are related to the question in a relevant way, according to the information need of the question, which may be determined through task-specific embeddings. With causality as a use case, we implement this insight in three steps. First, we generate causal embeddings cost-effectively by bootstrapping cause-effect pairs extracted from free text using a small set of seed patterns. Second, we train dedicated embeddings over this data, by using task-specific contexts, i.e., the context of a cause is its effect. Finally, we extend a state-of-the-art reranking approach for QA to incorporate these causal embeddings. We evaluate the causal embedding models both directly with a casual implication task, and indirectly, in a downstream causal QA task using data from Yahoo! Answers. We show that explicitly modeling causality improves performance in both tasks. In the QA task our best model achieves 37.3% P@1, significantly outperforming a strong baseline by 7.7% (relative).
Parsing syllables: modeling OT computationally
Oct 14, 1997In this paper, I propose to implement syllabification in OT as a parser. I propose several innovations that result in a finite and small candidate set. The candidate set problem is handled with several moves: i) MAX and DEP violations are not hypothesized by the parser, ii) candidates are encoded locally, and iii) EVAL is applied constraint by constraint. The parser I propose is implemented in Prolog. It has a number of desirable consequences. First, it runs and thus provides an existence proof that syllabification can be implemented in OT. There are a number of other desirable consequences as well. First, constraints are implemented as finite-state transducers. Second, the parser makes several interesting claims about the phonological properties of so-called nonrecoverable insertions and deletions. Third, the implementation suggests some particular reformulations of some of the benchmark constraints in the OT arsenal, e.g. *COMPLEX, PARSE, ONSET, and NOCODA.
Syllable parsing in English and French
Jun 02, 1995In this paper I argue that Optimality Theory provides for an explanatory model of syllabic parsing in English and French. The argument is based on psycholinguistic facts that have been mysterious up to now. This argument is further buttressed by the computational implementation developed here. This model is important for several reasons. First, it provides a demonstration of how OT can be used in a performance domain. Second, it suggests a new relationship between phonological theory and psycholinguistics. (Code in Perl is included and a WWW-interface is running at http://mayo.douglass.arizona.edu.)