 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Correction of Syntactic Dependency Annotation Differences
Paper and Code
Jan 15, 2022

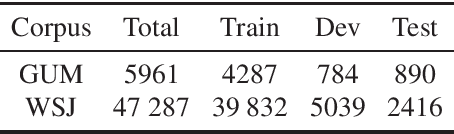

Annotation inconsistencies between data sets can cause problems for low-resource NLP, where noisy or inconsistent data cannot be as easily replaced compared with resource-rich languages. In this paper, we propose a method for automatically detecting annotation mismatches between dependency parsing corpora, as well as three related methods for automatically converting the mismatches. All three methods rely on comparing an unseen example in a new corpus with similar examples in an existing corpus. These three methods include a simple lexical replacement using the most frequent tag of the example in the existing corpus, a GloVe embedding-based replacement that considers a wider pool of examples, and a BERT embedding-based replacement that uses contextualized embeddings to provide examples fine-tuned to our specific data. We then evaluate these conversions by retraining two dependency parsers -- Stanza (Qi et al. 2020) and Parsing as Tagging (PaT) (Vacareanu et al. 2020) -- on the converted and unconverted data. We find that applying our conversions yields significantly better performance in many cases. Some differences observed between the two parsers are observed. Stanza has a more complex architecture with a quadratic algorithm, so it takes longer to train, but it can generalize better with less data. The PaT parser has a simpler architecture with a linear algorithm, speeding up training time but requiring more training data to reach comparable or better performance.