 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen and Where Did it Happen? An Encoder-Decoder Model to Identify Scenario Context
Oct 10, 2024



We introduce a neural architecture finetuned for the task of scenario context generation: The relevant location and time of an event or entity mentioned in text. Contextualizing information extraction helps to scope the validity of automated finings when aggregating them as knowledge graphs. Our approach uses a high-quality curated dataset of time and location annotations in a corpus of epidemiology papers to train an encoder-decoder architecture. We also explored the use of data augmentation techniques during training. Our findings suggest that a relatively small fine-tuned encoder-decoder model performs better than out-of-the-box LLMs and semantic role labeling parsers to accurate predict the relevant scenario information of a particular entity or event.
3DTextureTransformer: Geometry Aware Texture Generation for Arbitrary Mesh Topology
Mar 07, 2024



Learning to generate textures for a novel 3D mesh given a collection of 3D meshes and real-world 2D images is an important problem with applications in various domains such as 3D simulation, augmented and virtual reality, gaming, architecture, and design. Existing solutions either do not produce high-quality textures or deform the original high-resolution input mesh topology into a regular grid to make this generation easier but also lose the original mesh topology. In this paper, we present a novel framework called the 3DTextureTransformer that enables us to generate high-quality textures without deforming the original, high-resolution input mesh. Our solution, a hybrid of geometric deep learning and StyleGAN-like architecture, is flexible enough to work on arbitrary mesh topologies and also easily extensible to texture generation for point cloud representations. Our solution employs a message-passing framework in 3D in conjunction with a StyleGAN-like architecture for 3D texture generation. The architecture achieves state-of-the-art performance among a class of solutions that can learn from a collection of 3D geometry and real-world 2D images while working with any arbitrary mesh topology.
Neural Machine Translation for Code Generation
May 22, 2023

Neural machine translation (NMT) methods developed for natural language processing have been shown to be highly successful in automating translation from one natural language to another. Recently, these NMT methods have been adapted to the generation of program code. In NMT for code generation, the task is to generate output source code that satisfies constraints expressed in the input. In the literature, a variety of different input scenarios have been explored, including generating code based on natural language description, lower-level representations such as binary or assembly (neural decompilation), partial representations of source code (code completion and repair), and source code in another language (code translation). In this paper we survey the NMT for code generation literature, cataloging the variety of methods that have been explored according to input and output representations, model architectures, optimization techniques used, data sets, and evaluation methods. We discuss the limitations of existing methods and future research directions
Validity Assessment of Legal Will Statements as Natural Language Inference
Oct 30, 2022



This work introduces a natural language inference (NLI) dataset that focuses on the validity of statements in legal wills. This dataset is unique because: (a) each entailment decision requires three inputs: the statement from the will, the law, and the conditions that hold at the time of the testator's death; and (b) the included texts are longer than the ones in current NLI datasets. We trained eight neural NLI models in this dataset. All the models achieve more than 80% macro F1 and accuracy, which indicates that neural approaches can handle this task reasonably well. However, group accuracy, a stricter evaluation measure that is calculated with a group of positive and negative examples generated from the same statement as a unit, is in mid 80s at best, which suggests that the models' understanding of the task remains superficial. Further ablative analyses and explanation experiments indicate that all three text segments are used for prediction, but some decisions rely on semantically irrelevant tokens. This indicates that overfitting on these longer texts likely happens, and that additional research is required for this task to be solved.
Texture Generation Using Graph Generative Adversarial Network And Differentiable Rendering
Jun 17, 2022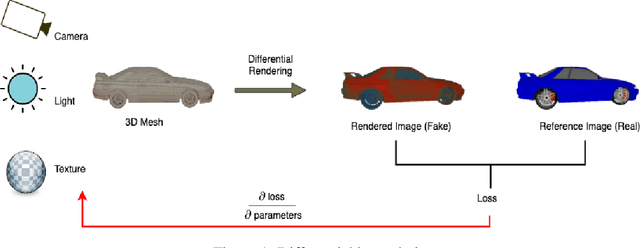
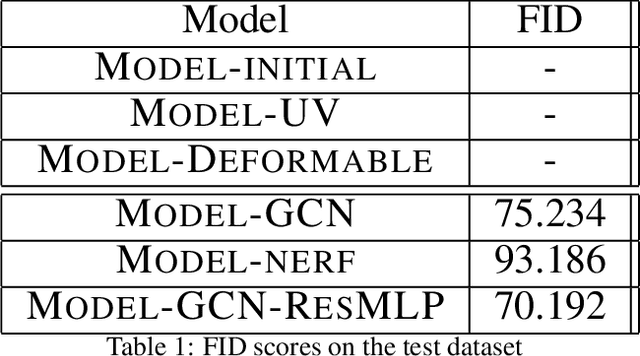
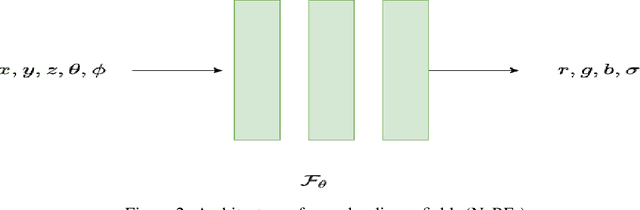
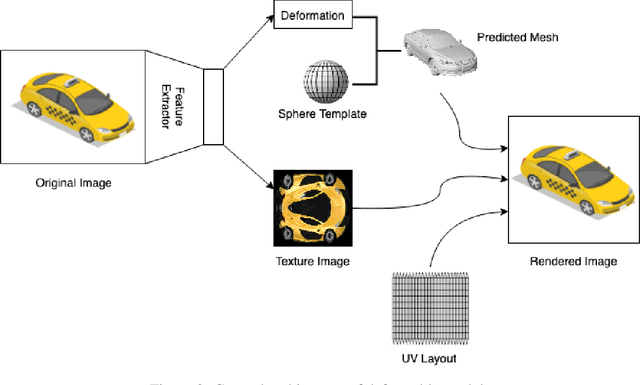
Novel texture synthesis for existing 3D mesh models is an important step towards photo realistic asset generation for existing simulators. But existing methods inherently work in the 2D image space which is the projection of the 3D space from a given camera perspective. These methods take camera angle, 3D model information, lighting information and generate photorealistic 2D image. To generate a photorealistic image from another perspective or lighting, we need to make a computationally expensive forward pass each time we change the parameters. Also, it is hard to generate such images for a simulator that can satisfy the temporal constraints the sequences of images should be similar but only need to change the viewpoint of lighting as desired. The solution can not be directly integrated with existing tools like Blender and Unreal Engine. Manual solution is expensive and time consuming. We thus present a new system called a graph generative adversarial network (GGAN) that can generate textures which can be directly integrated into a given 3D mesh models with tools like Blender and Unreal Engine and can be simulated from any perspective and lighting condition easily.
Learning Open Domain Multi-hop Search Using Reinforcement Learning
May 30, 2022
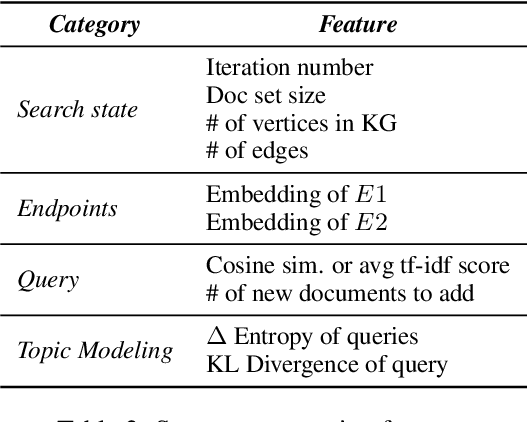
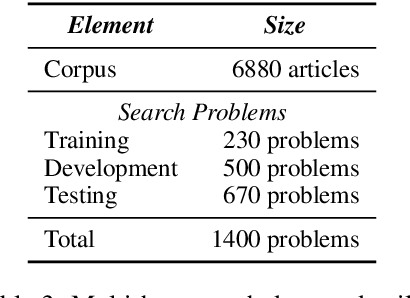
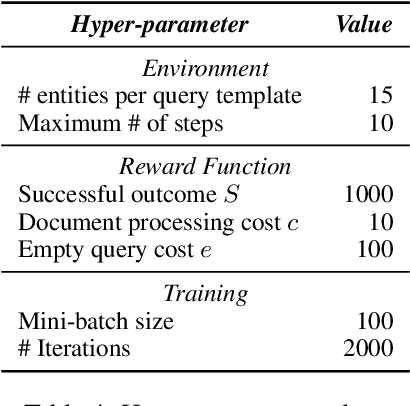
We propose a method to teach an automated agent to learn how to search for multi-hop paths of relations between entities in an open domain. The method learns a policy for directing existing information retrieval and machine reading resources to focus on relevant regions of a corpus. The approach formulates the learning problem as a Markov decision process with a state representation that encodes the dynamics of the search process and a reward structure that minimizes the number of documents that must be processed while still finding multi-hop paths. We implement the method in an actor-critic reinforcement learning algorithm and evaluate it on a dataset of search problems derived from a subset of English Wikipedia. The algorithm finds a family of policies that succeeds in extracting the desired information while processing fewer documents compared to several baseline heuristic algorithms.
Neural Architectures for Biological Inter-Sentence Relation Extraction
Dec 17, 2021

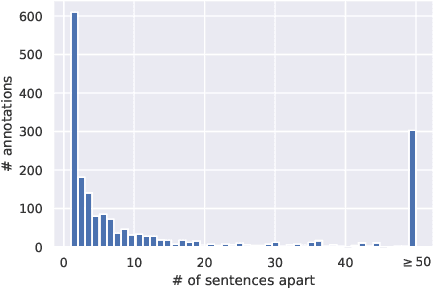

We introduce a family of deep-learning architectures for inter-sentence relation extraction, i.e., relations where the participants are not necessarily in the same sentence. We apply these architectures to an important use case in the biomedical domain: assigning biological context to biochemical events. In this work, biological context is defined as the type of biological system within which the biochemical event is observed. The neural architectures encode and aggregate multiple occurrences of the same candidate context mentions to determine whether it is the correct context for a particular event mention. We propose two broad types of architectures: the first type aggregates multiple instances that correspond to the same candidate context with respect to event mention before emitting a classification; the second type independently classifies each instance and uses the results to vote for the final class, akin to an ensemble approach. Our experiments show that the proposed neural classifiers are competitive and some achieve better performance than previous state of the art traditional machine learning methods without the need for feature engineering. Our analysis shows that the neural methods particularly improve precision compared to traditional machine learning classifiers and also demonstrates how the difficulty of inter-sentence relation extraction increases as the distance between the event and context mentions increase.
Federated Reconnaissance: Efficient, Distributed, Class-Incremental Learning
Sep 01, 2021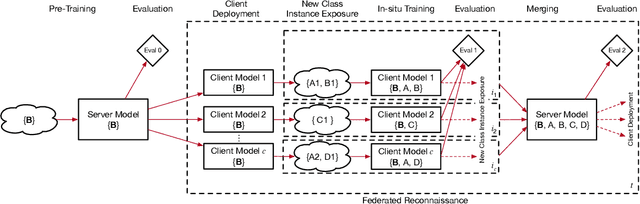
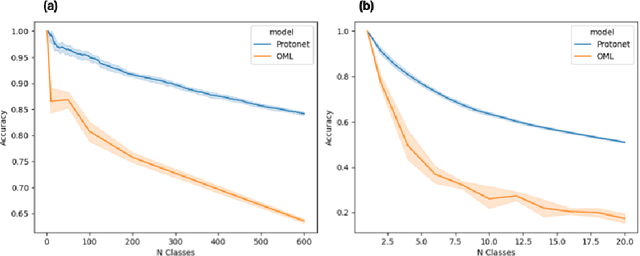
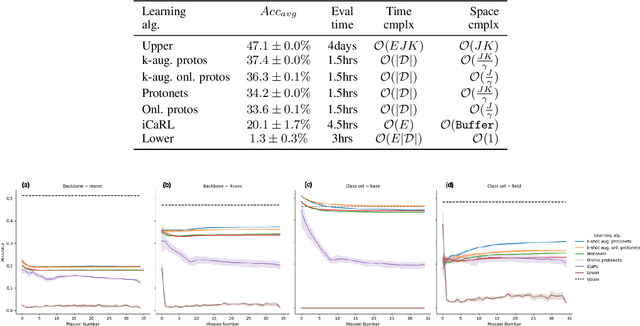
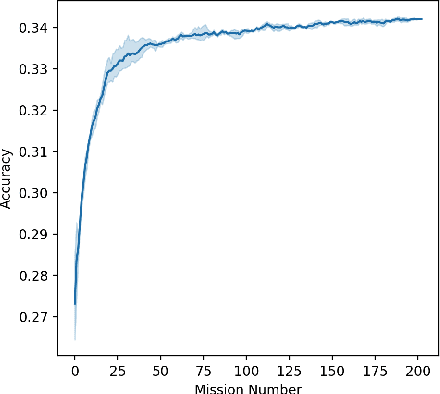
We describe federated reconnaissance, a class of learning problems in which distributed clients learn new concepts independently and communicate that knowledge efficiently. In particular, we propose an evaluation framework and methodological baseline for a system in which each client is expected to learn a growing set of classes and communicate knowledge of those classes efficiently with other clients, such that, after knowledge merging, the clients should be able to accurately discriminate between classes in the superset of classes observed by the set of clients. We compare a range of learning algorithms for this problem and find that prototypical networks are a strong approach in that they are robust to catastrophic forgetting while incorporating new information efficiently. Furthermore, we show that the online averaging of prototype vectors is effective for client model merging and requires only a small amount of communication overhead, memory, and update time per class with no gradient-based learning or hyperparameter tuning. Additionally, to put our results in context, we find that a simple, prototypical network with four convolutional layers significantly outperforms complex, state of the art continual learning algorithms, increasing the accuracy by over 22% after learning 600 Omniglot classes and over 33% after learning 20 mini-ImageNet classes incrementally. These results have important implications for federated reconnaissance and continual learning more generally by demonstrating that communicating feature vectors is an efficient, robust, and effective means for distributed, continual learning.
AutoMATES: Automated Model Assembly from Text, Equations, and Software
Jan 21, 2020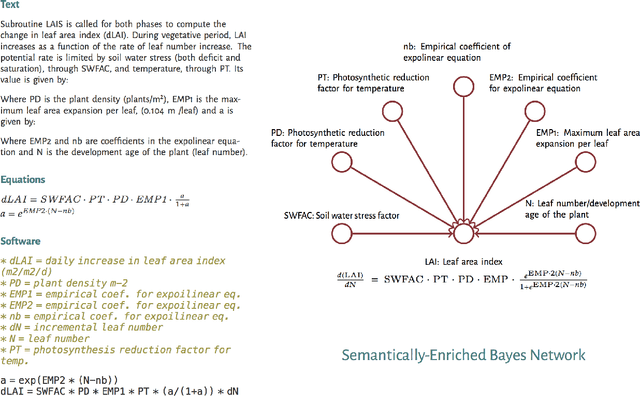
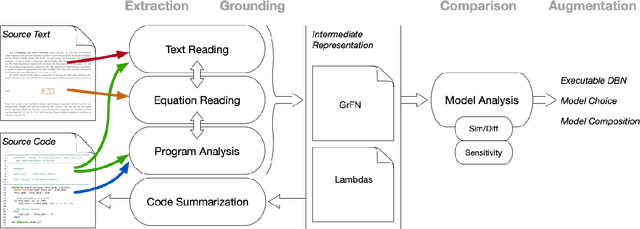

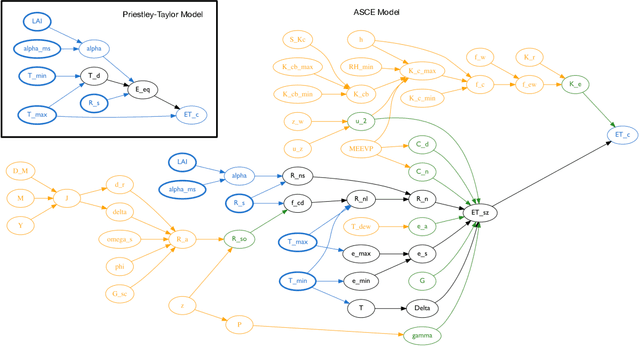
Models of complicated systems can be represented in different ways - in scientific papers, they are represented using natural language text as well as equations. But to be of real use, they must also be implemented as software, thus making code a third form of representing models. We introduce the AutoMATES project, which aims to build semantically-rich unified representations of models from scientific code and publications to facilitate the integration of computational models from different domains and allow for modeling large, complicated systems that span multiple domains and levels of abstraction.
Meta-Learning Initializations for Image Segmentation
Dec 13, 2019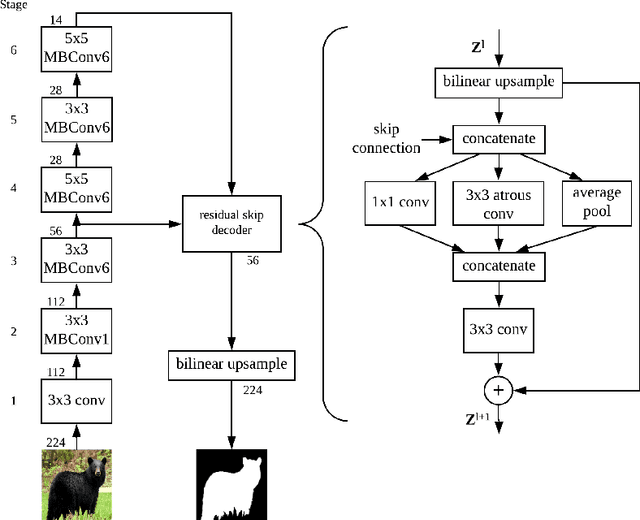


While meta-learning approaches that utilize neural network representations have made progress in few-shot image classification, reinforcement learning, and, more recently, image semantic segmentation, the training algorithms and model architectures have become increasingly specialized to the few-shot domain. A natural question that arises is how to develop learning systems that scale from few-shot to many-shot settings while yielding competitive performance in both. One scalable potential approach that does not require ensembling many models nor the computational costs of relation networks, is to meta-learn an initialization. In this work, we study first-order meta-learning of initializations for deep neural networks that must produce dense, structured predictions given an arbitrary amount of training data for a new task. Our primary contributions include (1), an extension and experimental analysis of first-order model agnostic meta-learning algorithms (including FOMAML and Reptile) to image segmentation, (2) a novel neural network architecture built for parameter efficiency and fast learning which we call EfficientLab, (3) a formalization of the generalization error of meta-learning algorithms, which we leverage to decrease error on unseen tasks, and (4) a small benchmark dataset, FP-k, for the empirical study of how meta-learning systems perform in both few- and many-shot settings. We show that meta-learned initializations for image segmentation provide value for both canonical few-shot learning problems and larger datasets, outperforming ImageNet-trained initializations for up to 400 densely labeled examples. We find that our network, with an empirically estimated optimal update procedure, yields state of the art results on the FSS-1000 dataset while only requiring one forward pass through a single model at evaluation time.