 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Korean Legal Judgment Prediction Dataset for Insurance Disputes
Jan 26, 2024This paper introduces a Korean legal judgment prediction (LJP) dataset for insurance disputes. Successful LJP models on insurance disputes can benefit insurance companies and their customers. It can save both sides' time and money by allowing them to predict how the result would come out if they proceed to the dispute mediation process. As is often the case with low-resource languages, there is a limitation on the amount of data available for this specific task. To mitigate this issue, we investigate how one can achieve a good performance despite the limitation in data. In our experiment, we demonstrate that Sentence Transformer Fine-tuning (SetFit, Tunstall et al., 2022) is a good alternative to standard fine-tuning when training data are limited. The models fine-tuned with the SetFit approach on our data show similar performance to the Korean LJP benchmark models (Hwang et al., 2022) despite the much smaller data size.
Validity Assessment of Legal Will Statements as Natural Language Inference
Oct 30, 2022



This work introduces a natural language inference (NLI) dataset that focuses on the validity of statements in legal wills. This dataset is unique because: (a) each entailment decision requires three inputs: the statement from the will, the law, and the conditions that hold at the time of the testator's death; and (b) the included texts are longer than the ones in current NLI datasets. We trained eight neural NLI models in this dataset. All the models achieve more than 80% macro F1 and accuracy, which indicates that neural approaches can handle this task reasonably well. However, group accuracy, a stricter evaluation measure that is calculated with a group of positive and negative examples generated from the same statement as a unit, is in mid 80s at best, which suggests that the models' understanding of the task remains superficial. Further ablative analyses and explanation experiments indicate that all three text segments are used for prediction, but some decisions rely on semantically irrelevant tokens. This indicates that overfitting on these longer texts likely happens, and that additional research is required for this task to be solved.
Extracting Space Situational Awareness Events from News Text
Jan 15, 2022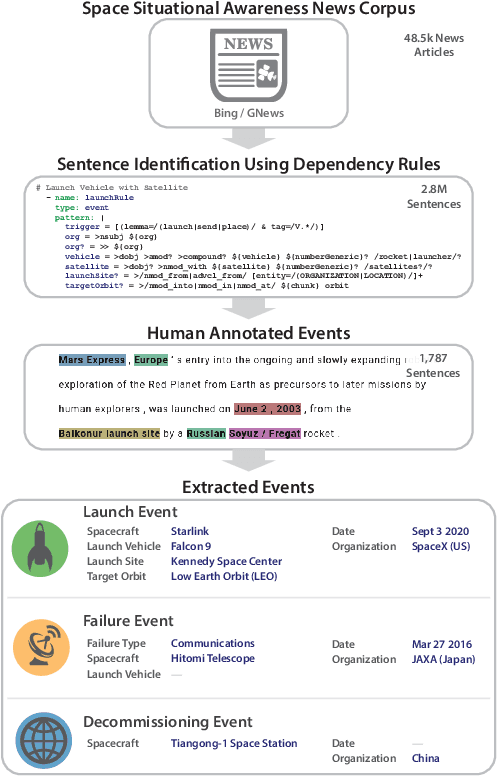
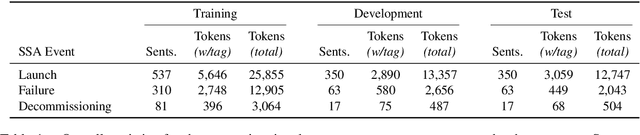

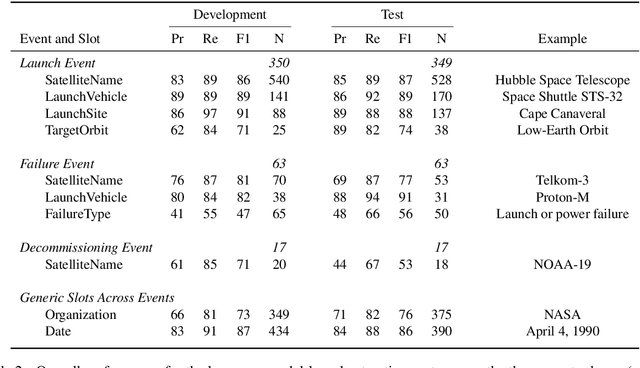
Space situational awareness typically makes use of physical measurements from radar, telescopes, and other assets to monitor satellites and other spacecraft for operational, navigational, and defense purposes. In this work we explore using textual input for the space situational awareness task. We construct a corpus of 48.5k news articles spanning all known active satellites between 2009 and 2020. Using a dependency-rule-based extraction system designed to target three high-impact events -- spacecraft launches, failures, and decommissionings, we identify 1,787 space-event sentences that are then annotated by humans with 15.9k labels for event slots. We empirically demonstrate a state-of-the-art neural extraction system achieves an overall F1 between 53 and 91 per slot for event extraction in this low-resource, high-impact domain.