 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Chunking with Transformers for Image-Based Spacecraft Guidance and Control
Sep 04, 2025We present an imitation learning approach for spacecraft guidance, navigation, and control(GNC) that achieves high performance from limited data. Using only 100 expert demonstrations, equivalent to 6,300 environment interactions, our method, which implements Action Chunking with Transformers (ACT), learns a control policy that maps visual and state observations to thrust and torque commands. ACT generates smoother, more consistent trajectories than a meta-reinforcement learning (meta-RL) baseline trained with 40 million interactions. We evaluate ACT on a rendezvous task: in-orbit docking with the International Space Station (ISS). We show that our approach achieves greater accuracy, smoother control, and greater sample efficiency.
Deep Reinforcement Learning for Weapons to Targets Assignment in a Hypersonic strike
Oct 27, 2023We use deep reinforcement learning (RL) to optimize a weapons to target assignment (WTA) policy for multi-vehicle hypersonic strike against multiple targets. The objective is to maximize the total value of destroyed targets in each episode. Each randomly generated episode varies the number and initial conditions of the hypersonic strike weapons (HSW) and targets, the value distribution of the targets, and the probability of a HSW being intercepted. We compare the performance of this WTA policy to that of a benchmark WTA policy derived using non-linear integer programming (NLIP), and find that the RL WTA policy gives near optimal performance with a 1000X speedup in computation time, allowing real time operation that facilitates autonomous decision making in the mission end game.
Line of Sight Curvature for Missile Guidance using Reinforcement Meta-Learning
Apr 29, 2022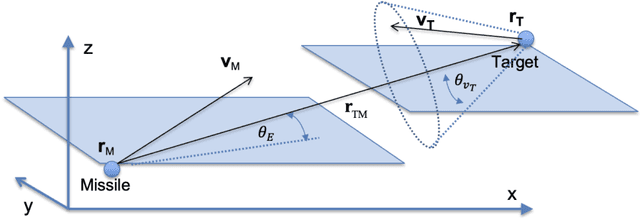

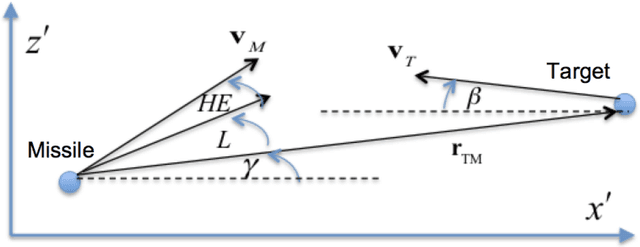
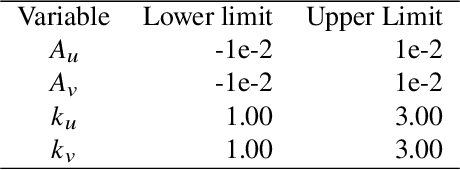
We use reinforcement meta learning to optimize a line of sight curvature policy that increases the effectiveness of a guidance system against maneuvering targets. The policy is implemented as a recurrent neural network that maps navigation system outputs to a Euler 321 attitude representation. The attitude representation is then used to construct a direction cosine matrix that biases the observed line of sight vector. The line of sight rotation rate derived from the biased line of sight is then mapped to a commanded acceleration by the guidance system. By varying the bias as a function of navigation system outputs, the policy enhances accuracy against highly maneuvering targets. Importantly, our method does not require an estimate of target acceleration. In our experiments, we demonstrate that when our method is combined with proportional navigation, the system significantly outperforms augmented proportional navigation with perfect knowledge of target acceleration, achieving improved accuracy with less control effort against a wide range of target maneuvers.
Extracting Space Situational Awareness Events from News Text
Jan 15, 2022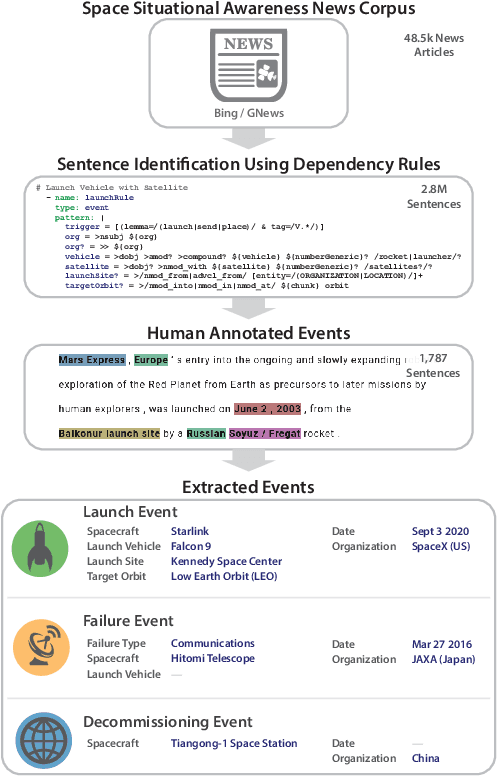
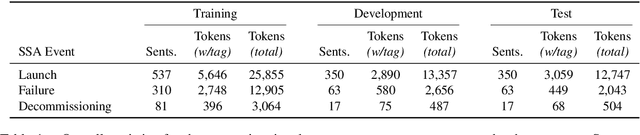

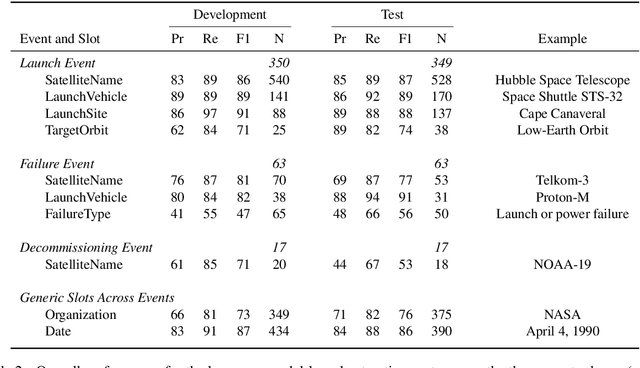
Space situational awareness typically makes use of physical measurements from radar, telescopes, and other assets to monitor satellites and other spacecraft for operational, navigational, and defense purposes. In this work we explore using textual input for the space situational awareness task. We construct a corpus of 48.5k news articles spanning all known active satellites between 2009 and 2020. Using a dependency-rule-based extraction system designed to target three high-impact events -- spacecraft launches, failures, and decommissionings, we identify 1,787 space-event sentences that are then annotated by humans with 15.9k labels for event slots. We empirically demonstrate a state-of-the-art neural extraction system achieves an overall F1 between 53 and 91 per slot for event extraction in this low-resource, high-impact domain.
Integrated Guidance and Control for Lunar Landing using a Stabilized Seeker
Dec 16, 2021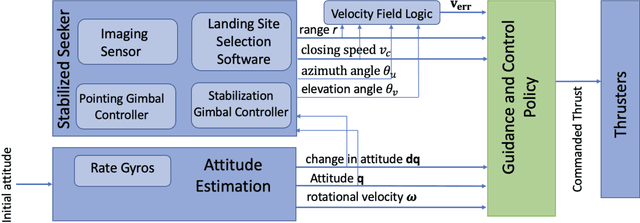

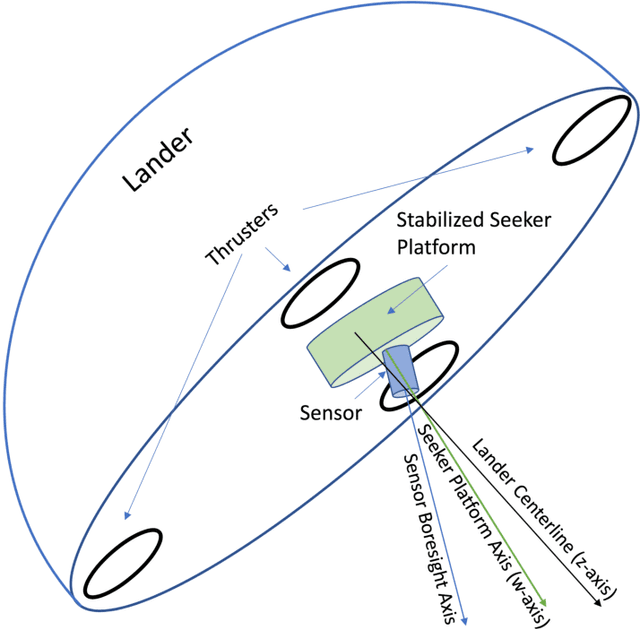
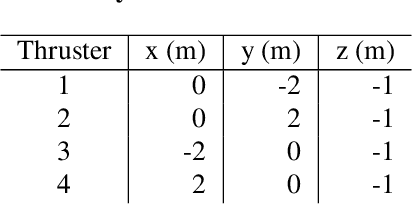
We develop an integrated guidance and control system that in conjunction with a stabilized seeker and landing site detection software can achieve precise and safe planetary landing. The seeker tracks the designated landing site by adjusting seeker elevation and azimuth angles to center the designated landing site in the sensor field of view. The seeker angles, closing speed, and range to the designated landing site are used to formulate a velocity field that is used by the guidance and control system to achieve a safe landing at the designated landing site. The guidance and control system maps this velocity field, attitude, and rotational velocity directly to a commanded thrust vector for the lander's four engines. The guidance and control system is implemented as a policy optimized using reinforcement meta learning. We demonstrate that the guidance and control system is compatible with multiple diverts during the powered descent phase, and is robust to seeker lag, actuator lag and degradation, and center of mass variation induced by fuel consumption. We outline several concepts of operations, including an approach using a preplaced landing beacon.
VisualEnv: visual Gym environments with Blender
Dec 01, 2021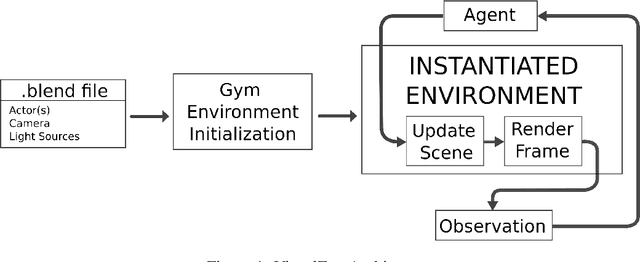



In this paper VisualEnv, a new tool for creating visual environment for reinforcement learning is introduced. It is the product of an integration of an open-source modelling and rendering software, Blender, and a python module used to generate environment model for simulation, OpenAI Gym. VisualEnv allows the user to create custom environments with photorealistic rendering capabilities and full integration with python. The framework is described and tested on a series of example problems that showcase its features for training reinforcement learning agents.
Terminal Adaptive Guidance for Autonomous Hypersonic Strike Weapons via Reinforcement Learning
Oct 16, 2021

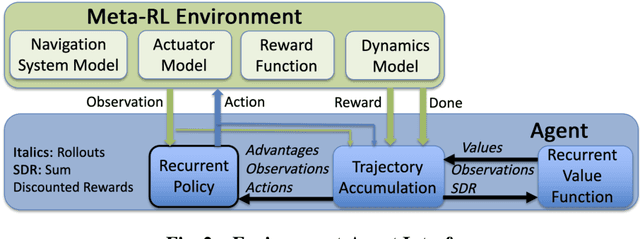
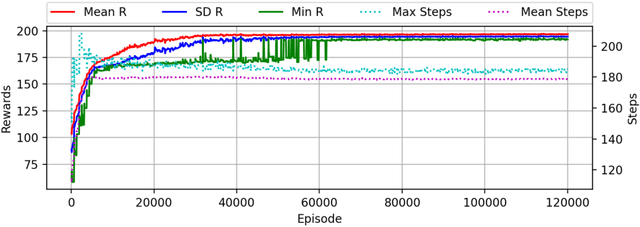
An adaptive guidance system suitable for the terminal phase trajectory of a hypersonic strike weapon is optimized using reinforcement meta learning. The guidance system maps observations directly to commanded bank angle, angle of attack, and sideslip angle rates. Importantly, the observations are directly measurable from radar seeker outputs with minimal processing. The optimization framework implements a shaping reward that minimizes the line of sight rotation rate, with a terminal reward given if the agent satisfies path constraints and meets terminal accuracy and speed criteria. We show that the guidance system can adapt to off-nominal flight conditions including perturbation of aerodynamic coefficient parameters, actuator failure scenarios, sensor scale factor errors, and actuator lag, while satisfying heating rate, dynamic pressure, and load path constraints, as well as a minimum impact speed constraint. We demonstrate precision strike capability against a maneuvering ground target and the ability to divert to a new target, the latter being important to maximize strike effectiveness for a group of hypersonic strike weapons. Moreover, we demonstrate a threat evasion strategy against interceptors with limited midcourse correction capability, where the hypersonic strike weapon implements multiple diverts to alternate targets, with the last divert to the actual target. Finally, we include preliminary results for an integrated guidance and control system in a six degrees-of-freedom environment.
Integrated and Adaptive Guidance and Control for Endoatmospheric Missiles via Reinforcement Learning
Sep 08, 2021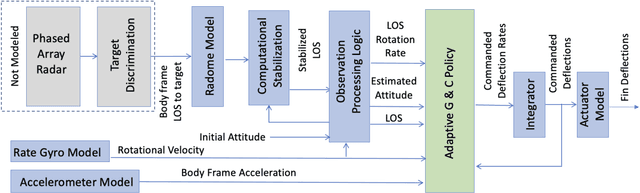
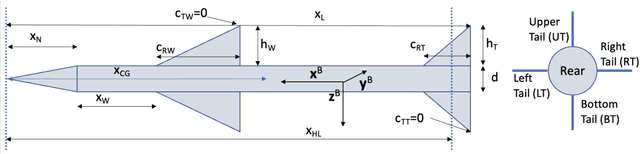
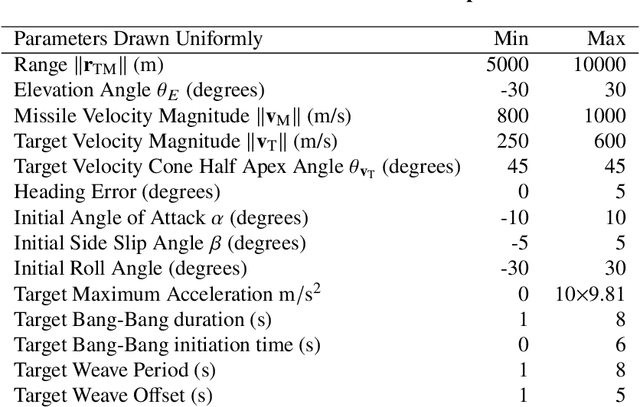
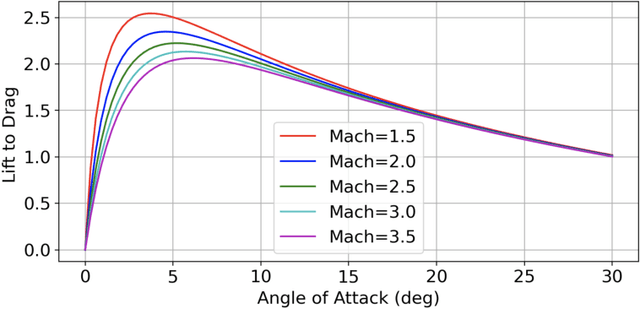
We apply the meta reinforcement learning framework to optimize an integrated and adaptive guidance and flight control system for an air-to-air missile, implementing the system as a deep neural network (the policy). The policy maps observations directly to commanded rates of change for the missile's control surface deflections, with the observations derived with minimal processing from the computationally stabilized line of sight unit vector measured by a strap down seeker, estimated rotational velocity from rate gyros, and control surface deflection angles. The system induces intercept trajectories against a maneuvering target that satisfy control constraints on fin deflection angles, and path constraints on look angle and load. We test the optimized system in a six degrees-of-freedom simulator that includes a non-linear radome model and a strapdown seeker model. Through extensive simulation, we demonstrate that the system can adapt to a large flight envelope and off nominal flight conditions that include perturbation of aerodynamic coefficient parameters and center of pressure locations. Moreover, we find that the system is robust to the parasitic attitude loop induced by radome refraction, imperfect seeker stabilization, and sensor scale factor errors. Finally, we compare our system's performance to two benchmarks: a proportional navigation guidance system benchmark in a simplified 3-DOF environment, which we take as an upper bound on performance attainable with separate guidance and flight control systems, and a longitudinal model of proportional navigation coupled with a three loop autopilot. We find that our system moderately outperforms the former, and outperforms the latter by a large margin.
Adaptive Approach Phase Guidance for a Hypersonic Glider via Reinforcement Meta Learning
Jul 30, 2021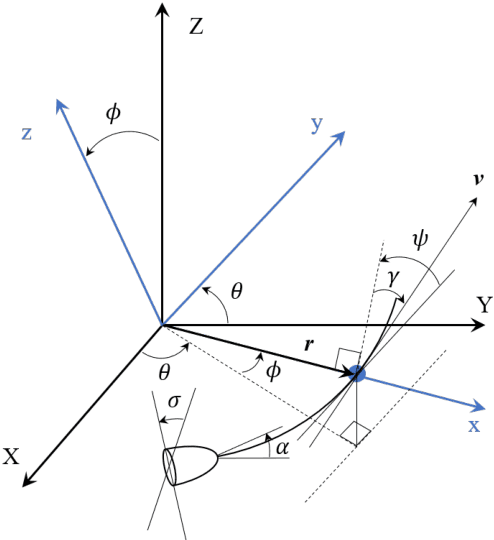
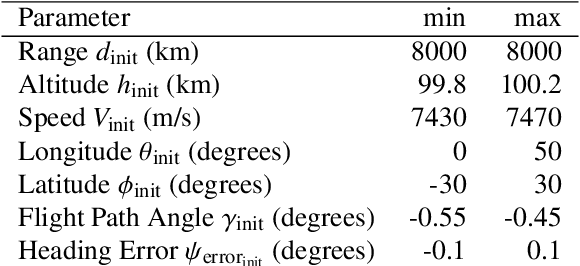
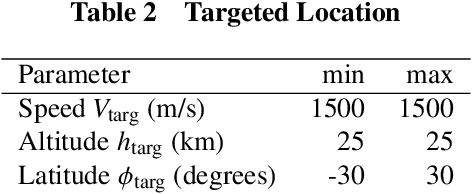
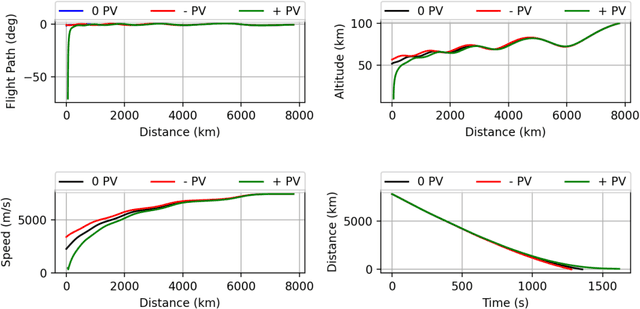
We use Reinforcement Meta Learning to optimize an adaptive guidance system suitable for the approach phase of a gliding hypersonic vehicle. Adaptability is achieved by optimizing over a range of off-nominal flight conditions including perturbation of aerodynamic coefficient parameters, actuator failure scenarios, and sensor noise. The system maps observations directly to commanded bank angle and angle of attack rates. These observations include a velocity field tracking error formulated using parallel navigation, but adapted to work over long trajectories where the Earth's curvature must be taken into account. Minimizing the tracking error keeps the curved space line of sight to the target location aligned with the vehicle's velocity vector. The optimized guidance system will then induce trajectories that bring the vehicle to the target location with a high degree of accuracy at the designated terminal speed, while satisfying heating rate, load, and dynamic pressure constraints. We demonstrate the adaptability of the guidance system by testing over flight conditions that were not experienced during optimization. The guidance system's performance is then compared to that of a linear quadratic regulator tracking an optimal trajectory.
Extreme Theory of Functional Connections: A Physics-Informed Neural Network Method for Solving Parametric Differential Equations
May 15, 2020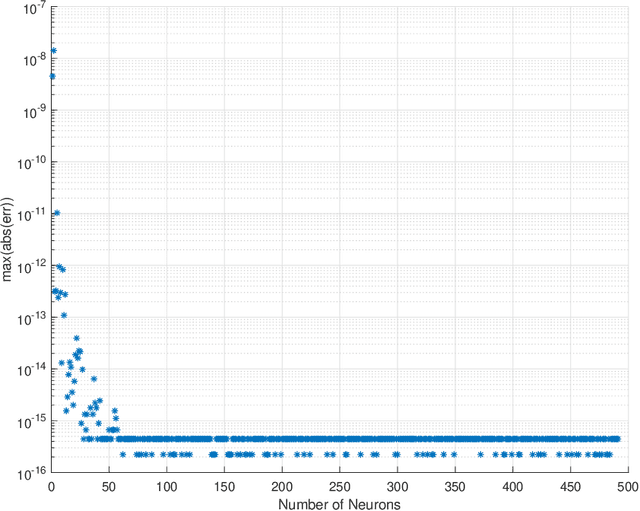
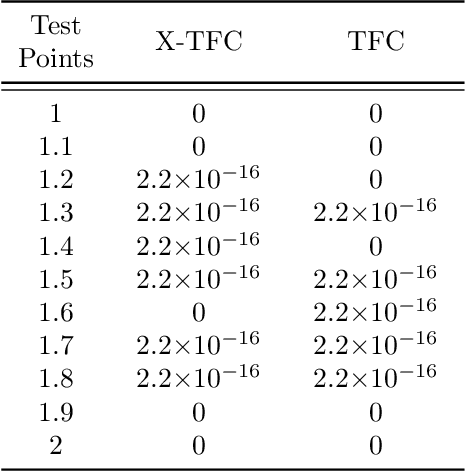
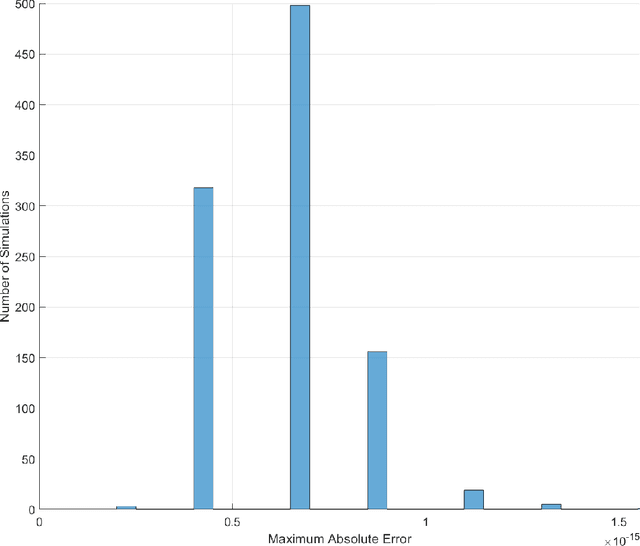
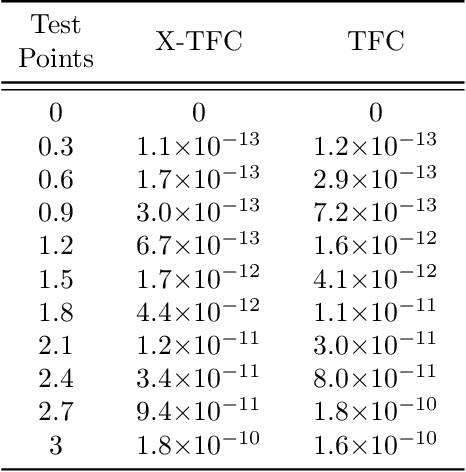
In this work we present a novel, accurate, and robust physics-informed method for solving problems involving parametric differential equations (DEs) called the Extreme Theory of Functional Connections, or X-TFC. The proposed method is a synergy of two recently developed frameworks for solving problems involving parametric DEs, 1) the Theory of Functional Connections, TFC, and the Physics-Informed Neural Networks, PINN. Although this paper focuses on the solution of exact problems involving parametric DEs (i.e. problems where the modeling error is negligible) with known parameters, X-TFC can also be used for data-driven solutions and data-driven discovery of parametric DEs. In the proposed method, the latent solution of the parametric DEs is approximated by a TFC constrained expression that uses a Neural Network (NN) as the free-function. This approximate solution form always analytically satisfies the constraints of the DE, while maintaining a NN with unconstrained parameters, like the Deep-TFC method. X-TFC differs from PINN and Deep-TFC; whereas PINN and Deep-TFC use a deep-NN, X-TFC uses a single-layer NN, or more precisely, an Extreme Learning Machine, ELM. This choice is based on the properties of the ELM algorithm. In order to numerically validate the method, it was tested over a range of problems including the approximation of solutions to linear and non-linear ordinary DEs (ODEs), systems of ODEs (SODEs), and partial DEs (PDEs). Furthermore, a few of these problems are of interest in physics and engineering such as the Classic Emden-Fowler equation, the Radiative Transfer (RT) equation, and the Heat-Transfer (HT) equation. The results show that X-TFC achieves high accuracy with low computational time and thus it is comparable with the other state-of-the-art methods.