 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic AutoResearch forSpace Autonomy: An Auditable, LLM-Driven Research Agent for Aerospace Control Problems
Jun 18, 2026Spacecraft guidance, navigation, and control functions are increasingly realized as learned policies distilled from expert solvers. Developing such a policy is itself a research process: an investigator selects an architecture and hyperparameters, runs experiments, and must determine whether an apparent improvement is genuine or merely seed noise. This paper presents AutoResearch, a framework in which a large language model autonomously drives that loop for aerospace control problems, coupled with a credibility layer, built into the loop, that certifies each reported result against the problem's own measured seed noise. The language model serves only as the offline research agent that develops the control policy; the trained policy it produces is then deployed onboard the spacecraft, while the model itself never operates the vehicle. At each iteration the agent reads a plain-language problem description and the run history, proposes a single edit to the training script, executes it, and logs the outcome. No reported result is credited until it passes the same three checks: measured per-problem seed noise, reseeded verification of the best configuration, and leave-one-out pruning of the agent's edits. The same loop is applied, unchanged, to two aerospace control problems: a Clohessy-Wiltshire relative rendezvous and a safety-constrained collision-avoidance docking past a keep-out zone, each calibrated against a known optimal control benchmark. In both, the audited policy clears the measured seed noise by many standard deviations; an undirected search over the same parameters does not. On the docking problem the gap becomes categorical: undirected search yields no feasible policy, while the learned policy stays outside the keep-out zone on every seed.
Memory-Efficient Meta-Reinforcement Learning for Adaptive Safety-Critical Control in Adversarial Spacecraft Proximity Operations
Jun 16, 2026Autonomous spacecraft rendezvous and proximity operations (RPO) require controllers that guarantee safety under thrust constraints while minimizing fuel expenditure. Input-constrained control barrier functions (ICCBFs) provide a control method for nonlinear systems with actuation constraints that construct a forward-invariant safe set. Previous work has shown that learning class-$\mathcal{K}$ functions defining the ICCBF recursion via meta reinforcement learning (meta-RL) yields a robust, non-greedy approach to safety-critical control in RPO. This paper extends that framework further by investigating the performance of three recurrent network architectures (Long Short Term Memory (LSTM), Gated Recurrent Unit (GRU), Selective State Space Model (Mamba)) and two training algorithms (Proximal Policy Optimization (PPO) and Soft Actor Critic (SAC)) to identify the best setup for tuning ICCBF class-K functions via meta-RL. In addition to cooperative test cases, performance is evaluated in the presence of adversarial behavior where the target spacecraft behaves in a way that worsens the safety of the chaser spacecraft. Results indicate that state space models such as Mamba when used with PPO achieve superior task completion, safety, and fuel-savings compared to other architectures, across all cooperative and uncooperative scenarios tested.
GUIDE: Guided Updates for In-context Decision Evolution in LLM-Driven Spacecraft Operations
Mar 28, 2026Large language models (LLMs) have been proposed as supervisory agents for spacecraft operations, but existing approaches rely on static prompting and do not improve across repeated executions. We introduce \textsc{GUIDE}, a non-parametric policy improvement framework that enables cross-episode adaptation without weight updates by evolving a structured, state-conditioned playbook of natural-language decision rules. A lightweight acting model performs real-time control, while offline reflection updates the playbook from prior trajectories. Evaluated on an adversarial orbital interception task in the Kerbal Space Program Differential Games environment, GUIDE's evolution consistently outperforms static baselines. Results indicate that context evolution in LLM agents functions as policy search over structured decision rules in real-time closed-loop spacecraft interaction.
Autonomous Reasoning for Spacecraft Control: A Large Language Model Framework with Group Relative Policy Optimization
Jan 07, 2026This paper presents a learning-based guidance-and-control approach that couples a reasoning-enabled Large Language Model (LLM) with Group Relative Policy Optimization (GRPO). A two-stage procedure consisting of Supervised Fine-Tuning (SFT) to learn formatting and control primitives, followed by GRPO for interaction-driven policy improvement, trains controllers for each environment. The framework is demonstrated on four control problems spanning a gradient of dynamical complexity, from canonical linear systems through nonlinear oscillatory dynamics to three-dimensional spacecraft attitude control with gyroscopic coupling and thrust constraints. Results demonstrate that an LLM with explicit reasoning, optimized via GRPO, can synthesize feasible stabilizing policies under consistent training settings across both linear and nonlinear systems. The two-stage training methodology enables models to generate control sequences while providing human-readable explanations of their decision-making process. This work establishes a foundation for applying GRPO-based reasoning to autonomous control systems, with potential applications in aerospace and other safety-critical domains.
Tiny Recursive Control: Iterative Reasoning for Efficient Optimal Control
Dec 18, 2025Neural network controllers increasingly demand millions of parameters, and language model approaches push into the billions. For embedded aerospace systems with strict power and latency constraints, this scaling is prohibitive. We present Tiny Recursive Control (TRC), a neural architecture based on a counterintuitive principle: capacity can emerge from iteration depth rather than parameter count. TRC applies compact networks (approximately 1.5M parameters) repeatedly through a two-level hierarchical latent structure, refining control sequences by simulating trajectories and correcting based on tracking error. Because the same weights process every refinement step, adding iterations increases computation without increasing memory. We evaluate TRC on nonlinear control problems including oscillator stabilization and powered descent with fuel constraints. Across these domains, TRC achieves near-optimal control costs while requiring only millisecond-scale inference on GPU and under 10~MB memory, two orders of magnitude smaller than language model baselines. These results demonstrate that recursive reasoning, previously confined to discrete tasks, transfers effectively to continuous control synthesis.
Multi-Phase Spacecraft Trajectory Optimization via Transformer-Based Reinforcement Learning
Nov 14, 2025
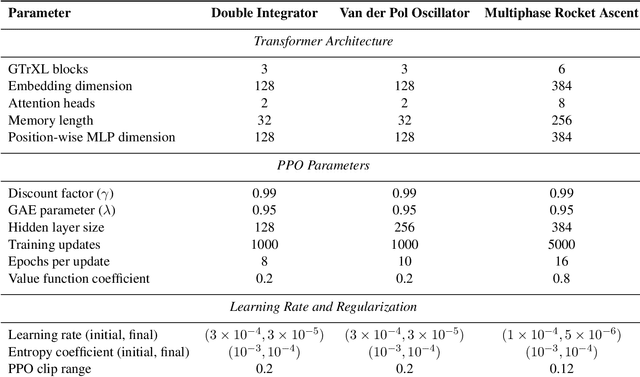
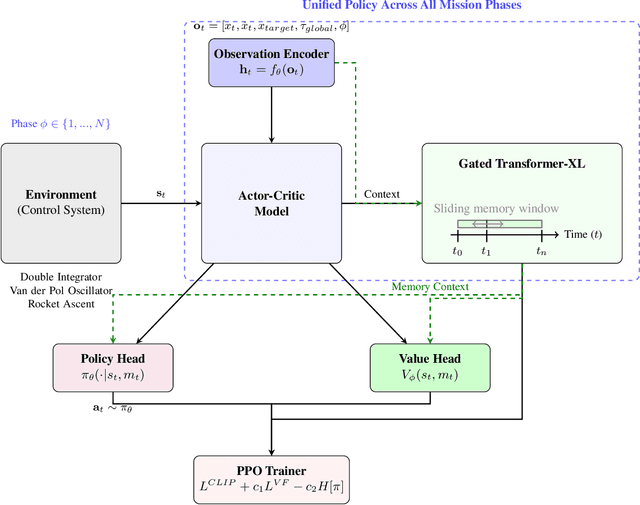
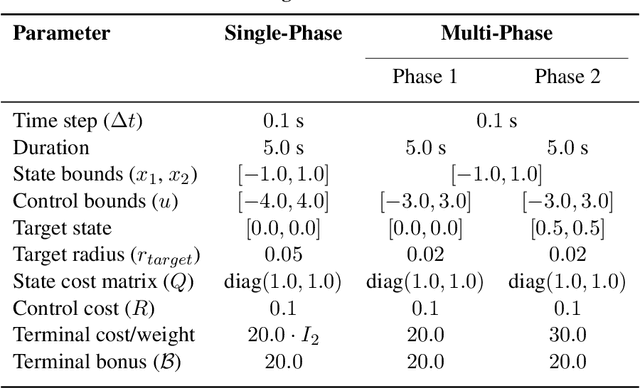
Autonomous spacecraft control for mission phases such as launch, ascent, stage separation, and orbit insertion remains a critical challenge due to the need for adaptive policies that generalize across dynamically distinct regimes. While reinforcement learning (RL) has shown promise in individual astrodynamics tasks, existing approaches often require separate policies for distinct mission phases, limiting adaptability and increasing operational complexity. This work introduces a transformer-based RL framework that unifies multi-phase trajectory optimization through a single policy architecture, leveraging the transformer's inherent capacity to model extended temporal contexts. Building on proximal policy optimization (PPO), our framework replaces conventional recurrent networks with a transformer encoder-decoder structure, enabling the agent to maintain coherent memory across mission phases spanning seconds to minutes during critical operations. By integrating a Gated Transformer-XL (GTrXL) architecture, the framework eliminates manual phase transitions while maintaining stability in control decisions. We validate our approach progressively: first demonstrating near-optimal performance on single-phase benchmarks (double integrator and Van der Pol oscillator), then extending to multiphase waypoint navigation variants, and finally tackling a complex multiphase rocket ascent problem that includes atmospheric flight, stage separation, and vacuum operations. Results demonstrate that the transformer-based framework not only matches analytical solutions in simple cases but also effectively learns coherent control policies across dynamically distinct regimes, establishing a foundation for scalable autonomous mission planning that reduces reliance on phase-specific controllers while maintaining compatibility with safety-critical verification protocols.
Action Chunking with Transformers for Image-Based Spacecraft Guidance and Control
Sep 04, 2025We present an imitation learning approach for spacecraft guidance, navigation, and control(GNC) that achieves high performance from limited data. Using only 100 expert demonstrations, equivalent to 6,300 environment interactions, our method, which implements Action Chunking with Transformers (ACT), learns a control policy that maps visual and state observations to thrust and torque commands. ACT generates smoother, more consistent trajectories than a meta-reinforcement learning (meta-RL) baseline trained with 40 million interactions. We evaluate ACT on a rendezvous task: in-orbit docking with the International Space Station (ISS). We show that our approach achieves greater accuracy, smoother control, and greater sample efficiency.
Large Language Models as Autonomous Spacecraft Operators in Kerbal Space Program
May 26, 2025Recent trends are emerging in the use of Large Language Models (LLMs) as autonomous agents that take actions based on the content of the user text prompts. We intend to apply these concepts to the field of Control in space, enabling LLMs to play a significant role in the decision-making process for autonomous satellite operations. As a first step towards this goal, we have developed a pure LLM-based solution for the Kerbal Space Program Differential Games (KSPDG) challenge, a public software design competition where participants create autonomous agents for maneuvering satellites involved in non-cooperative space operations, running on the KSP game engine. Our approach leverages prompt engineering, few-shot prompting, and fine-tuning techniques to create an effective LLM-based agent that ranked 2nd in the competition. To the best of our knowledge, this work pioneers the integration of LLM agents into space research. The project comprises several open repositories to facilitate replication and further research. The codebase is accessible on \href{https://github.com/ARCLab-MIT/kspdg}{GitHub}, while the trained models and datasets are available on \href{https://huggingface.co/OhhTuRnz}{Hugging Face}. Additionally, experiment tracking and detailed results can be reviewed on \href{https://wandb.ai/carrusk/huggingface}{Weights \& Biases
Fine-Tuned Language Models as Space Systems Controllers
Jan 28, 2025



Large language models (LLMs), or foundation models (FMs), are pretrained transformers that coherently complete sentences auto-regressively. In this paper, we show that LLMs can control simplified space systems after some additional training, called fine-tuning. We look at relatively small language models, ranging between 7 and 13 billion parameters. We focus on four problems: a three-dimensional spring toy problem, low-thrust orbit transfer, low-thrust cislunar control, and powered descent guidance. The fine-tuned LLMs are capable of controlling systems by generating sufficiently accurate outputs that are multi-dimensional vectors with up to 10 significant digits. We show that for several problems the amount of data required to perform fine-tuning is smaller than what is generally required of traditional deep neural networks (DNNs), and that fine-tuned LLMs are good at generalizing outside of the training dataset. Further, the same LLM can be fine-tuned with data from different problems, with only minor performance degradation with respect to LLMs trained for a single application. This work is intended as a first step towards the development of a general space systems controller.
Visual Language Models as Operator Agents in the Space Domain
Jan 14, 2025



This paper explores the application of Vision-Language Models (VLMs) as operator agents in the space domain, focusing on both software and hardware operational paradigms. Building on advances in Large Language Models (LLMs) and their multimodal extensions, we investigate how VLMs can enhance autonomous control and decision-making in space missions. In the software context, we employ VLMs within the Kerbal Space Program Differential Games (KSPDG) simulation environment, enabling the agent to interpret visual screenshots of the graphical user interface to perform complex orbital maneuvers. In the hardware context, we integrate VLMs with robotic systems equipped with cameras to inspect and diagnose physical space objects, such as satellites. Our results demonstrate that VLMs can effectively process visual and textual data to generate contextually appropriate actions, competing with traditional methods and non-multimodal LLMs in simulation tasks, and showing promise in real-world applications.