 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamSat: Towards a General 3D Model for Novel View Synthesis of Space Objects
Oct 07, 2024


Novel view synthesis (NVS) enables to generate new images of a scene or convert a set of 2D images into a comprehensive 3D model. In the context of Space Domain Awareness, since space is becoming increasingly congested, NVS can accurately map space objects and debris, improving the safety and efficiency of space operations. Similarly, in Rendezvous and Proximity Operations missions, 3D models can provide details about a target object's shape, size, and orientation, allowing for better planning and prediction of the target's behavior. In this work, we explore the generalization abilities of these reconstruction techniques, aiming to avoid the necessity of retraining for each new scene, by presenting a novel approach to 3D spacecraft reconstruction from single-view images, DreamSat, by fine-tuning the Zero123 XL, a state-of-the-art single-view reconstruction model, on a high-quality dataset of 190 high-quality spacecraft models and integrating it into the DreamGaussian framework. We demonstrate consistent improvements in reconstruction quality across multiple metrics, including Contrastive Language-Image Pretraining (CLIP) score (+0.33%), Peak Signal-to-Noise Ratio (PSNR) (+2.53%), Structural Similarity Index (SSIM) (+2.38%), and Learned Perceptual Image Patch Similarity (LPIPS) (+0.16%) on a test set of 30 previously unseen spacecraft images. Our method addresses the lack of domain-specific 3D reconstruction tools in the space industry by leveraging state-of-the-art diffusion models and 3D Gaussian splatting techniques. This approach maintains the efficiency of the DreamGaussian framework while enhancing the accuracy and detail of spacecraft reconstructions. The code for this work can be accessed on GitHub (https://github.com/ARCLab-MIT/space-nvs).
Self-supervised Machine Learning Based Approach to Orbit Modelling Applied to Space Traffic Management
Dec 11, 2023

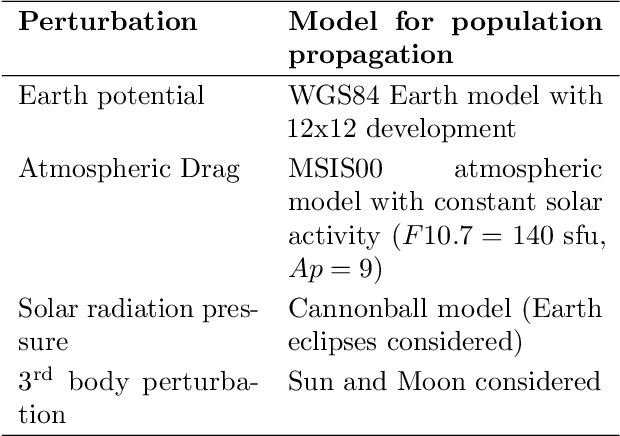

This paper presents a novel methodology for improving the performance of machine learning based space traffic management tasks through the use of a pre-trained orbit model. Taking inspiration from BERT-like self-supervised language models in the field of natural language processing, we introduce ORBERT, and demonstrate the ability of such a model to leverage large quantities of readily available orbit data to learn meaningful representations that can be used to aid in downstream tasks. As a proof of concept of this approach we consider the task of all vs. all conjunction screening, phrased here as a machine learning time series classification task. We show that leveraging unlabelled orbit data leads to improved performance, and that the proposed approach can be particularly beneficial for tasks where the availability of labelled data is limited.
* Presented at the 2021 International Association for the Advancement of Space Safety (IAASS) Conf