 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Reasoning for Spacecraft Control: A Large Language Model Framework with Group Relative Policy Optimization
Jan 07, 2026This paper presents a learning-based guidance-and-control approach that couples a reasoning-enabled Large Language Model (LLM) with Group Relative Policy Optimization (GRPO). A two-stage procedure consisting of Supervised Fine-Tuning (SFT) to learn formatting and control primitives, followed by GRPO for interaction-driven policy improvement, trains controllers for each environment. The framework is demonstrated on four control problems spanning a gradient of dynamical complexity, from canonical linear systems through nonlinear oscillatory dynamics to three-dimensional spacecraft attitude control with gyroscopic coupling and thrust constraints. Results demonstrate that an LLM with explicit reasoning, optimized via GRPO, can synthesize feasible stabilizing policies under consistent training settings across both linear and nonlinear systems. The two-stage training methodology enables models to generate control sequences while providing human-readable explanations of their decision-making process. This work establishes a foundation for applying GRPO-based reasoning to autonomous control systems, with potential applications in aerospace and other safety-critical domains.
Tiny Recursive Control: Iterative Reasoning for Efficient Optimal Control
Dec 18, 2025Neural network controllers increasingly demand millions of parameters, and language model approaches push into the billions. For embedded aerospace systems with strict power and latency constraints, this scaling is prohibitive. We present Tiny Recursive Control (TRC), a neural architecture based on a counterintuitive principle: capacity can emerge from iteration depth rather than parameter count. TRC applies compact networks (approximately 1.5M parameters) repeatedly through a two-level hierarchical latent structure, refining control sequences by simulating trajectories and correcting based on tracking error. Because the same weights process every refinement step, adding iterations increases computation without increasing memory. We evaluate TRC on nonlinear control problems including oscillator stabilization and powered descent with fuel constraints. Across these domains, TRC achieves near-optimal control costs while requiring only millisecond-scale inference on GPU and under 10~MB memory, two orders of magnitude smaller than language model baselines. These results demonstrate that recursive reasoning, previously confined to discrete tasks, transfers effectively to continuous control synthesis.
Multi-Phase Spacecraft Trajectory Optimization via Transformer-Based Reinforcement Learning
Nov 14, 2025
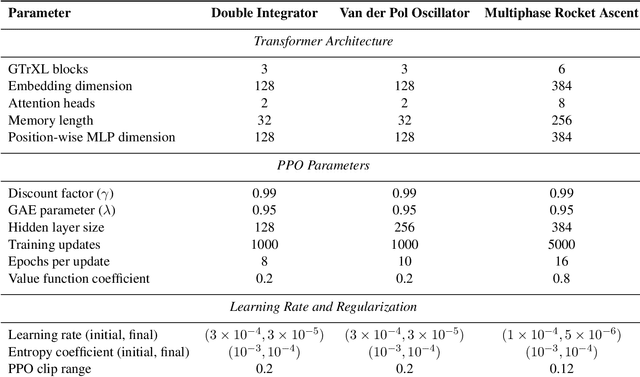
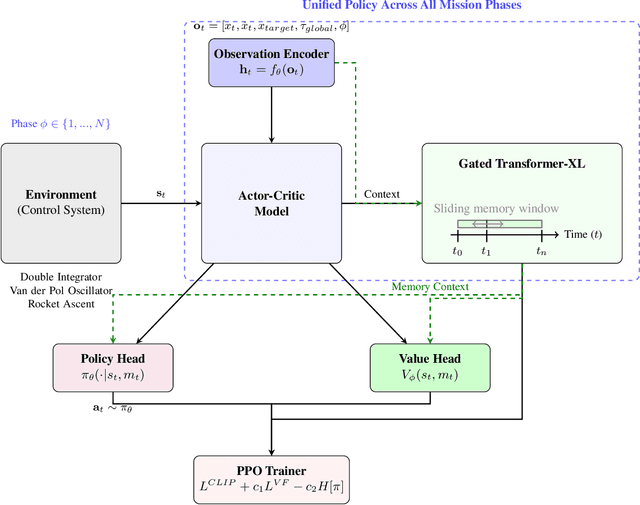
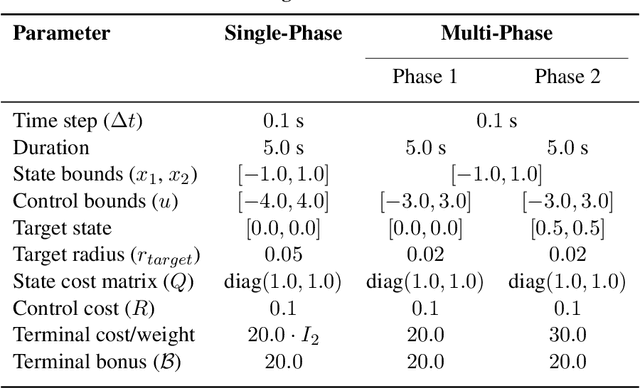
Autonomous spacecraft control for mission phases such as launch, ascent, stage separation, and orbit insertion remains a critical challenge due to the need for adaptive policies that generalize across dynamically distinct regimes. While reinforcement learning (RL) has shown promise in individual astrodynamics tasks, existing approaches often require separate policies for distinct mission phases, limiting adaptability and increasing operational complexity. This work introduces a transformer-based RL framework that unifies multi-phase trajectory optimization through a single policy architecture, leveraging the transformer's inherent capacity to model extended temporal contexts. Building on proximal policy optimization (PPO), our framework replaces conventional recurrent networks with a transformer encoder-decoder structure, enabling the agent to maintain coherent memory across mission phases spanning seconds to minutes during critical operations. By integrating a Gated Transformer-XL (GTrXL) architecture, the framework eliminates manual phase transitions while maintaining stability in control decisions. We validate our approach progressively: first demonstrating near-optimal performance on single-phase benchmarks (double integrator and Van der Pol oscillator), then extending to multiphase waypoint navigation variants, and finally tackling a complex multiphase rocket ascent problem that includes atmospheric flight, stage separation, and vacuum operations. Results demonstrate that the transformer-based framework not only matches analytical solutions in simple cases but also effectively learns coherent control policies across dynamically distinct regimes, establishing a foundation for scalable autonomous mission planning that reduces reliance on phase-specific controllers while maintaining compatibility with safety-critical verification protocols.
Visual Language Models as Operator Agents in the Space Domain
Jan 14, 2025This paper explores the application of Vision-Language Models (VLMs) as operator agents in the space domain, focusing on both software and hardware operational paradigms. Building on advances in Large Language Models (LLMs) and their multimodal extensions, we investigate how VLMs can enhance autonomous control and decision-making in space missions. In the software context, we employ VLMs within the Kerbal Space Program Differential Games (KSPDG) simulation environment, enabling the agent to interpret visual screenshots of the graphical user interface to perform complex orbital maneuvers. In the hardware context, we integrate VLMs with robotic systems equipped with cameras to inspect and diagnose physical space objects, such as satellites. Our results demonstrate that VLMs can effectively process visual and textual data to generate contextually appropriate actions, competing with traditional methods and non-multimodal LLMs in simulation tasks, and showing promise in real-world applications.
Data-Driven Shape Sensing in Continuum Manipulators via Sliding Resistive Flex Sensors
Nov 29, 2023We introduce a novel shape-sensing method using Resistive Flex Sensors (RFS) embedded in cable-driven Continuum Dexterous Manipulators (CDMs). The RFS is predominantly sensitive to deformation rather than direct forces, making it a distinctive tool for shape sensing. The RFS unit we designed is a considerably less expensive and robust alternative, offering comparable accuracy and real-time performance to existing shape sensing methods used for the CDMs proposed for minimally-invasive surgery. Our design allows the RFS to move along and inside the CDM conforming to its curvature, offering the ability to capture resistance metrics from various bending positions without the need for elaborate sensor setups. The RFS unit is calibrated using an overhead camera and a ResNet machine learning framework. Experiments using a 3D printed prototype of the CDM achieved an average shape estimation error of 0.968 mm with a standard error of 0.275 mm. The response time of the model was approximately 1.16 ms, making real-time shape sensing feasible. While this preliminary study successfully showed the feasibility of our approach for C-shape CDM deformations with non-constant curvatures, we are currently extending the results to show the feasibility for adapting to more complex CDM configurations such as S-shape created in obstructed environments or in presence of the external forces.
Data Filtering Networks
Oct 02, 2023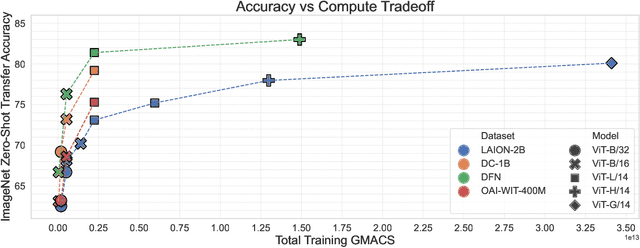
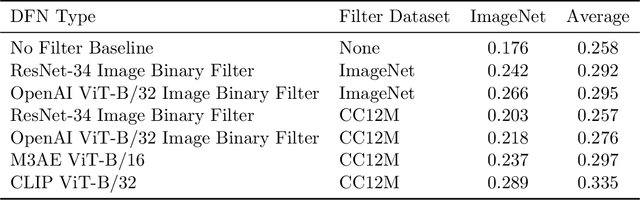
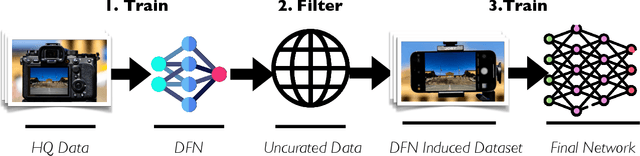
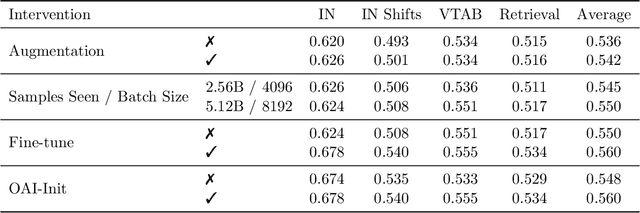
Large training sets have become a cornerstone of machine learning and are the foundation for recent advances in language modeling and multimodal learning. While data curation for pre-training is often still ad-hoc, one common paradigm is to first collect a massive pool of data from the Web and then filter this candidate pool down to an actual training set via various heuristics. In this work, we study the problem of learning a data filtering network (DFN) for this second step of filtering a large uncurated dataset. Our key finding is that the quality of a network for filtering is distinct from its performance on downstream tasks: for instance, a model that performs well on ImageNet can yield worse training sets than a model with low ImageNet accuracy that is trained on a small amount of high-quality data. Based on our insights, we construct new data filtering networks that induce state-of-the-art image-text datasets. Specifically, our best performing dataset DFN-5B enables us to train state-of-the-art models for their compute budgets: among other improvements on a variety of tasks, a ViT-H trained on our dataset achieves 83.0% zero-shot transfer accuracy on ImageNet, out-performing models trained on other datasets such as LAION-2B, DataComp-1B, or OpenAI's WIT. In order to facilitate further research in dataset design, we also release a new 2 billion example dataset DFN-2B and show that high performance data filtering networks can be trained from scratch using only publicly available data.
SDS-200: A Swiss German Speech to Standard German Text Corpus
May 19, 2022
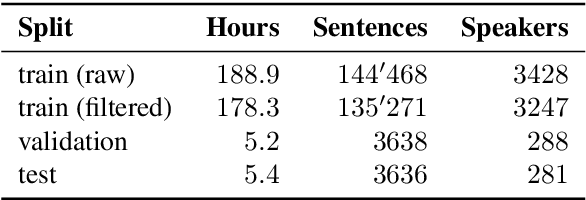
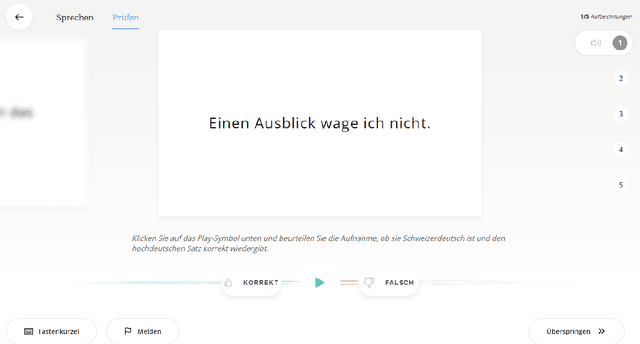
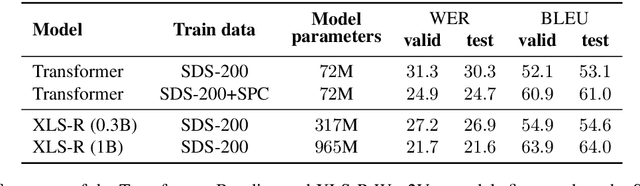
We present SDS-200, a corpus of Swiss German dialectal speech with Standard German text translations, annotated with dialect, age, and gender information of the speakers. The dataset allows for training speech translation, dialect recognition, and speech synthesis systems, among others. The data was collected using a web recording tool that is open to the public. Each participant was given a text in Standard German and asked to translate it to their Swiss German dialect before recording it. To increase the corpus quality, recordings were validated by other participants. The data consists of 200 hours of speech by around 4000 different speakers and covers a large part of the Swiss-German dialect landscape. We release SDS-200 alongside a baseline speech translation model, which achieves a word error rate (WER) of 30.3 and a BLEU score of 53.1 on the SDS-200 test set. Furthermore, we use SDS-200 to fine-tune a pre-trained XLS-R model, achieving 21.6 WER and 64.0 BLEU.