 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualVision ArthroNav: Investigating Opportunities to Enhance Localization and Reconstruction in Image-based Arthroscopy Navigation via External Cameras
Nov 12, 2025


Arthroscopic procedures can greatly benefit from navigation systems that enhance spatial awareness, depth perception, and field of view. However, existing optical tracking solutions impose strict workspace constraints and disrupt surgical workflow. Vision-based alternatives, though less invasive, often rely solely on the monocular arthroscope camera, making them prone to drift, scale ambiguity, and sensitivity to rapid motion or occlusion. We propose DualVision ArthroNav, a multi-camera arthroscopy navigation system that integrates an external camera rigidly mounted on the arthroscope. The external camera provides stable visual odometry and absolute localization, while the monocular arthroscope video enables dense scene reconstruction. By combining these complementary views, our system resolves the scale ambiguity and long-term drift inherent in monocular SLAM and ensures robust relocalization. Experiments demonstrate that our system effectively compensates for calibration errors, achieving an average absolute trajectory error of 1.09 mm. The reconstructed scenes reach an average target registration error of 2.16 mm, with high visual fidelity (SSIM = 0.69, PSNR = 22.19). These results indicate that our system provides a practical and cost-efficient solution for arthroscopic navigation, bridging the gap between optical tracking and purely vision-based systems, and paving the way toward clinically deployable, fully vision-based arthroscopic guidance.
A Shape-Aware Total Body Photography System for In-focus Surface Coverage Optimization
May 22, 2025Total Body Photography (TBP) is becoming a useful screening tool for patients at high risk for skin cancer. While much progress has been made, existing TBP systems can be further improved for automatic detection and analysis of suspicious skin lesions, which is in part related to the resolution and sharpness of acquired images. This paper proposes a novel shape-aware TBP system automatically capturing full-body images while optimizing image quality in terms of resolution and sharpness over the body surface. The system uses depth and RGB cameras mounted on a 360-degree rotary beam, along with 3D body shape estimation and an in-focus surface optimization method to select the optimal focus distance for each camera pose. This allows for optimizing the focused coverage over the complex 3D geometry of the human body given the calibrated camera poses. We evaluate the effectiveness of the system in capturing high-fidelity body images. The proposed system achieves an average resolution of 0.068 mm/pixel and 0.0566 mm/pixel with approximately 85% and 95% of surface area in-focus, evaluated on simulation data of diverse body shapes and poses as well as a real scan of a mannequin respectively. Furthermore, the proposed shape-aware focus method outperforms existing focus protocols (e.g. auto-focus). We believe the high-fidelity imaging enabled by the proposed system will improve automated skin lesion analysis for skin cancer screening.
Benchmark of Segmentation Techniques for Pelvic Fracture in CT and X-ray: Summary of the PENGWIN 2024 Challenge
Apr 03, 2025The segmentation of pelvic fracture fragments in CT and X-ray images is crucial for trauma diagnosis, surgical planning, and intraoperative guidance. However, accurately and efficiently delineating the bone fragments remains a significant challenge due to complex anatomy and imaging limitations. The PENGWIN challenge, organized as a MICCAI 2024 satellite event, aimed to advance automated fracture segmentation by benchmarking state-of-the-art algorithms on these complex tasks. A diverse dataset of 150 CT scans was collected from multiple clinical centers, and a large set of simulated X-ray images was generated using the DeepDRR method. Final submissions from 16 teams worldwide were evaluated under a rigorous multi-metric testing scheme. The top-performing CT algorithm achieved an average fragment-wise intersection over union (IoU) of 0.930, demonstrating satisfactory accuracy. However, in the X-ray task, the best algorithm attained an IoU of 0.774, highlighting the greater challenges posed by overlapping anatomical structures. Beyond the quantitative evaluation, the challenge revealed methodological diversity in algorithm design. Variations in instance representation, such as primary-secondary classification versus boundary-core separation, led to differing segmentation strategies. Despite promising results, the challenge also exposed inherent uncertainties in fragment definition, particularly in cases of incomplete fractures. These findings suggest that interactive segmentation approaches, integrating human decision-making with task-relevant information, may be essential for improving model reliability and clinical applicability.
dARt Vinci: Egocentric Data Collection for Surgical Robot Learning at Scale
Mar 07, 2025Data scarcity has long been an issue in the robot learning community. Particularly, in safety-critical domains like surgical applications, obtaining high-quality data can be especially difficult. It poses challenges to researchers seeking to exploit recent advancements in reinforcement learning and imitation learning, which have greatly improved generalizability and enabled robots to conduct tasks autonomously. We introduce dARt Vinci, a scalable data collection platform for robot learning in surgical settings. The system uses Augmented Reality (AR) hand tracking and a high-fidelity physics engine to capture subtle maneuvers in primitive surgical tasks: By eliminating the need for a physical robot setup and providing flexibility in terms of time, space, and hardware resources-such as multiview sensors and actuators-specialized simulation is a viable alternative. At the same time, AR allows the robot data collection to be more egocentric, supported by its body tracking and content overlaying capabilities. Our user study confirms the proposed system's efficiency and usability, where we use widely-used primitive tasks for training teleoperation with da Vinci surgical robots. Data throughput improves across all tasks compared to real robot settings by 41% on average. The total experiment time is reduced by an average of 10%. The temporal demand in the task load survey is improved. These gains are statistically significant. Additionally, the collected data is over 400 times smaller in size, requiring far less storage while achieving double the frequency.
Look Before You Leap: Using Serialized State Machine for Language Conditioned Robotic Manipulation
Mar 07, 2025



Imitation learning frameworks for robotic manipulation have drawn attention in the recent development of language model grounded robotics. However, the success of the frameworks largely depends on the coverage of the demonstration cases: When the demonstration set does not include examples of how to act in all possible situations, the action may fail and can result in cascading errors. To solve this problem, we propose a framework that uses serialized Finite State Machine (FSM) to generate demonstrations and improve the success rate in manipulation tasks requiring a long sequence of precise interactions. To validate its effectiveness, we use environmentally evolving and long-horizon puzzles that require long sequential actions. Experimental results show that our approach achieves a success rate of up to 98 in these tasks, compared to the controlled condition using existing approaches, which only had a success rate of up to 60, and, in some tasks, almost failed completely.
Revisiting Lesion Tracking in 3D Total Body Photography
Dec 10, 2024



Melanoma is the most deadly form of skin cancer. Tracking the evolution of nevi and detecting new lesions across the body is essential for the early detection of melanoma. Despite prior work on longitudinal tracking of skin lesions in 3D total body photography, there are still several challenges, including 1) low accuracy for finding correct lesion pairs across scans, 2) sensitivity to noisy lesion detection, and 3) lack of large-scale datasets with numerous annotated lesion pairs. We propose a framework that takes in a pair of 3D textured meshes, matches lesions in the context of total body photography, and identifies unmatchable lesions. We start by computing correspondence maps bringing the source and target meshes to a template mesh. Using these maps to define source/target signals over the template domain, we construct a flow field aligning the mapped signals. The initial correspondence maps are then refined by advecting forward/backward along the vector field. Finally, lesion assignment is performed using the refined correspondence maps. We propose the first large-scale dataset for skin lesion tracking with 25K lesion pairs across 198 subjects. The proposed method achieves a success rate of 89.9% (at 10 mm criterion) for all pairs of annotated lesions and a matching accuracy of 98.2% for subjects with more than 200 lesions.
An Image-Guided Robotic System for Transcranial Magnetic Stimulation: System Development and Experimental Evaluation
Oct 20, 2024



Transcranial magnetic stimulation (TMS) is a noninvasive medical procedure that can modulate brain activity, and it is widely used in neuroscience and neurology research. Compared to manual operators, robots may improve the outcome of TMS due to their superior accuracy and repeatability. However, there has not been a widely accepted standard protocol for performing robotic TMS using fine-segmented brain images, resulting in arbitrary planned angles with respect to the true boundaries of the modulated cortex. Given that the recent study in TMS simulation suggests a noticeable difference in outcomes when using different anatomical details, cortical shape should play a more significant role in deciding the optimal TMS coil pose. In this work, we introduce an image-guided robotic system for TMS that focuses on (1) establishing standardized planning methods and heuristics to define a reference (true zero) for the coil poses and (2) solving the issue that the manual coil placement requires expert hand-eye coordination which often leading to low repeatability of the experiments. To validate the design of our robotic system, a phantom study and a preliminary human subject study were performed. Our results show that the robotic method can half the positional error and improve the rotational accuracy by up to two orders of magnitude. The accuracy is proven to be repeatable because the standard deviation of multiple trials is lowered by an order of magnitude. The improved actuation accuracy successfully translates to the TMS application, with a higher and more stable induced voltage in magnetic field sensors.
A Novel Method to Improve Quality Surface Coverage in Multi-View Capture
Jul 21, 2024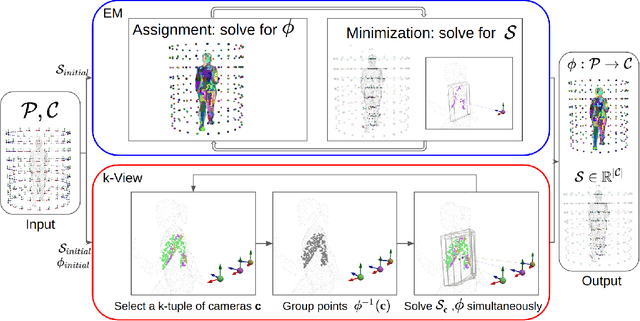
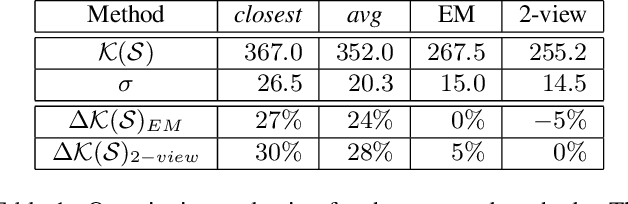
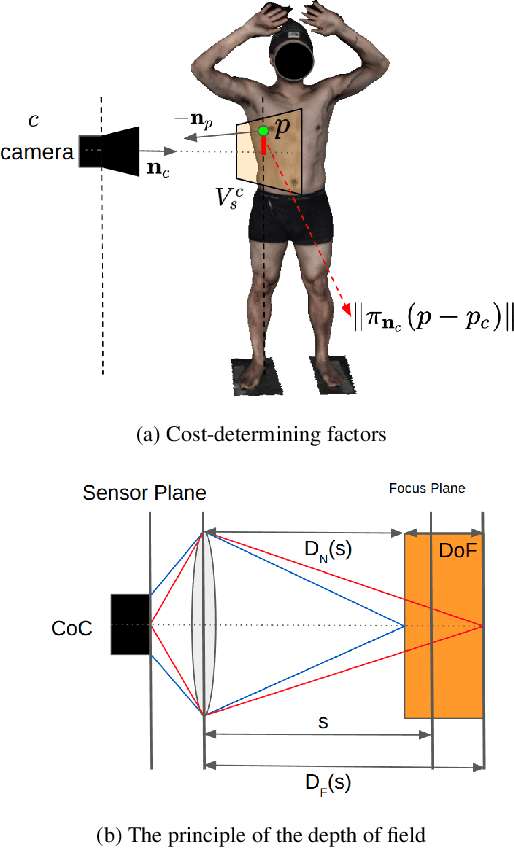

The depth of field of a camera is a limiting factor for applications that require taking images at a short subject-to-camera distance or using a large focal length, such as total body photography, archaeology, and other close-range photogrammetry applications. Furthermore, in multi-view capture, where the target is larger than the camera's field of view, an efficient way to optimize surface coverage captured with quality remains a challenge. Given the 3D mesh of the target object and camera poses, we propose a novel method to derive a focus distance for each camera that optimizes the quality of the covered surface area. We first design an Expectation-Minimization (EM) algorithm to assign points on the mesh uniquely to cameras and then solve for a focus distance for each camera given the associated point set. We further improve the quality surface coverage by proposing a $k$-view algorithm that solves for the points assignment and focus distances by considering multiple views simultaneously. We demonstrate the effectiveness of the proposed method under various simulations for total body photography. The EM and $k$-view algorithms improve the relative cost of the baseline single-view methods by at least $24$% and $28$% respectively, corresponding to increasing the in-focus surface area by roughly $1550$ cm$^2$ and $1780$ cm$^2$. We believe the algorithms can be useful in a number of vision applications that require photogrammetric details but are limited by the depth of field.
Uncertainty-Aware Shape Estimation of a Surgical Continuum Manipulator in Constrained Environments using Fiber Bragg Grating Sensors
May 11, 2024



Continuum Dexterous Manipulators (CDMs) are well-suited tools for minimally invasive surgery due to their inherent dexterity and reachability. Nonetheless, their flexible structure and non-linear curvature pose significant challenges for shape-based feedback control. The use of Fiber Bragg Grating (FBG) sensors for shape sensing has shown great potential in estimating the CDM's tip position and subsequently reconstructing the shape using optimization algorithms. This optimization, however, is under-constrained and may be ill-posed for complex shapes, falling into local minima. In this work, we introduce a novel method capable of directly estimating a CDM's shape from FBG sensor wavelengths using a deep neural network. In addition, we propose the integration of uncertainty estimation to address the critical issue of uncertainty in neural network predictions. Neural network predictions are unreliable when the input sample is outside the training distribution or corrupted by noise. Recognizing such deviations is crucial when integrating neural networks within surgical robotics, as inaccurate estimations can pose serious risks to the patient. We present a robust method that not only improves the precision upon existing techniques for FBG-based shape estimation but also incorporates a mechanism to quantify the models' confidence through uncertainty estimation. We validate the uncertainty estimation through extensive experiments, demonstrating its effectiveness and reliability on out-of-distribution (OOD) data, adding an additional layer of safety and precision to minimally invasive surgical robotics.
GBEC: Geometry-Based Hand-Eye Calibration
Apr 08, 2024

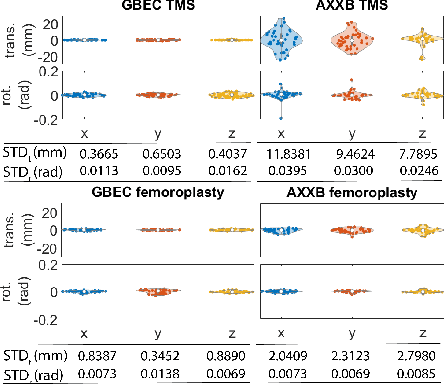

Hand-eye calibration is the problem of solving the transformation from the end-effector of a robot to the sensor attached to it. Commonly employed techniques, such as AXXB or AXZB formulations, rely on regression methods that require collecting pose data from different robot configurations, which can produce low accuracy and repeatability. However, the derived transformation should solely depend on the geometry of the end-effector and the sensor attachment. We propose Geometry-Based End-Effector Calibration (GBEC) that enhances the repeatability and accuracy of the derived transformation compared to traditional hand-eye calibrations. To demonstrate improvements, we apply the approach to two different robot-assisted procedures: Transcranial Magnetic Stimulation (TMS) and femoroplasty. We also discuss the generalizability of GBEC for camera-in-hand and marker-in-hand sensor mounting methods. In the experiments, we perform GBEC between the robot end-effector and an optical tracker's rigid body marker attached to the TMS coil or femoroplasty drill guide. Previous research documents low repeatability and accuracy of the conventional methods for robot-assisted TMS hand-eye calibration. When compared to some existing methods, the proposed method relies solely on the geometry of the flange and the pose of the rigid-body marker, making it independent of workspace constraints or robot accuracy, without sacrificing the orthogonality of the rotation matrix. Our results validate the accuracy and applicability of the approach, providing a new and generalizable methodology for obtaining the transformation from the end-effector to a sensor.