 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNICA: A Unified Neural Framework for Controllable 3D Avatars
Apr 03, 2026Controllable 3D human avatars have found widespread applications in 3D games, the metaverse, and AR/VR scenarios. The conventional approach to creating such a 3D avatar requires a lengthy, intricate pipeline encompassing appearance modeling, motion planning, rigging, and physical simulation. In this paper, we introduce UNICA (UNIfied neural Controllable Avatar), a skeleton-free generative model that unifies all avatar control components into a single neural framework. Given keyboard inputs akin to video game controls, UNICA generates the next frame of a 3D avatar's geometry through an action-conditioned diffusion model operating on 2D position maps. A point transformer then maps the resulting geometry to 3D Gaussian Splatting for high-fidelity free-view rendering. Our approach naturally captures hair and loose clothing dynamics without manually designed physical simulation, and supports extra-long autoregressive generation. To the best of our knowledge, UNICA is the first model to unify the workflow of "motion planning, rigging, physical simulation, and rendering". Code is released at https://github.com/zjh21/UNICA.
CrowdGaussian: Reconstructing High-Fidelity 3D Gaussians for Human Crowd from a Single Image
Mar 18, 2026Single-view 3D human reconstruction has garnered significant attention in recent years. Despite numerous advancements, prior research has concentrated on reconstructing 3D models from clear, close-up images of individual subjects, often yielding subpar results in the more prevalent multi-person scenarios. Reconstructing 3D human crowd models is a highly intricate task, laden with challenges such as: 1) extensive occlusions, 2) low clarity, and 3) numerous and various appearances. To address this task, we propose CrowdGaussian, a unified framework that directly reconstructs multi-person 3D Gaussian Splatting (3DGS) representations from single-image inputs. To handle occlusions, we devise a self-supervised adaptation pipeline that enables the pretrained large human model to reconstruct complete 3D humans with plausible geometry and appearance from heavily occluded inputs. Furthermore, we introduce Self-Calibrated Learning (SCL). This training strategy enables single-step diffusion models to adaptively refine coarse renderings to optimal quality by blending identity-preserving samples with clean/corrupted image pairs. The outputs can be distilled back to enhance the quality of multi-person 3DGS representations. Extensive experiments demonstrate that CrowdGaussian generates photorealistic, geometrically coherent reconstructions of multi-person scenes.
ArtVIP: Articulated Digital Assets of Visual Realism, Modular Interaction, and Physical Fidelity for Robot Learning
Jun 06, 2025Robot learning increasingly relies on simulation to advance complex ability such as dexterous manipulations and precise interactions, necessitating high-quality digital assets to bridge the sim-to-real gap. However, existing open-source articulated-object datasets for simulation are limited by insufficient visual realism and low physical fidelity, which hinder their utility for training models mastering robotic tasks in real world. To address these challenges, we introduce ArtVIP, a comprehensive open-source dataset comprising high-quality digital-twin articulated objects, accompanied by indoor-scene assets. Crafted by professional 3D modelers adhering to unified standards, ArtVIP ensures visual realism through precise geometric meshes and high-resolution textures, while physical fidelity is achieved via fine-tuned dynamic parameters. Meanwhile, the dataset pioneers embedded modular interaction behaviors within assets and pixel-level affordance annotations. Feature-map visualization and optical motion capture are employed to quantitatively demonstrate ArtVIP's visual and physical fidelity, with its applicability validated across imitation learning and reinforcement learning experiments. Provided in USD format with detailed production guidelines, ArtVIP is fully open-source, benefiting the research community and advancing robot learning research. Our project is at https://x-humanoid-artvip.github.io/ .
HCDN: A Change Detection Network for Construction Housekeeping Using Feature Fusion and Large Vision Models
Oct 23, 2024Workplace safety has received increasing attention as millions of workers worldwide suffer from work-related accidents. Despite poor housekeeping is a significant contributor to construction accidents, there remains a significant lack of technological research focused on improving housekeeping practices in construction sites. Recognizing and locating poor housekeeping in a dynamic construction site is an important task that can be improved through computer vision approaches. Despite advances in AI and computer vision, existing methods for detecting poor housekeeping conditions face many challenges, including limited explanations, lack of locating of poor housekeeping, and lack of annotated datasets. On the other hand, change detection which aims to detect the changed environmental conditions (e.g., changing from good to poor housekeeping) and 'where' the change has occurred (e.g., location of objects causing poor housekeeping), has not been explored to the problem of housekeeping management. To address these challenges, we propose the Housekeeping Change Detection Network (HCDN), an advanced change detection neural network that integrates a feature fusion module and a large vision model, achieving state-of-the-art performance. Additionally, we introduce the approach to establish a novel change detection dataset (named Housekeeping-CCD) focused on housekeeping in construction sites, along with a housekeeping segmentation dataset. Our contributions include significant performance improvements compared to existing methods, providing an effective tool for enhancing construction housekeeping and safety. To promote further development, we share our source code and trained models for global researchers: https://github.com/NUS-DBE/Housekeeping-CD.
An Image-Guided Robotic System for Transcranial Magnetic Stimulation: System Development and Experimental Evaluation
Oct 20, 2024



Transcranial magnetic stimulation (TMS) is a noninvasive medical procedure that can modulate brain activity, and it is widely used in neuroscience and neurology research. Compared to manual operators, robots may improve the outcome of TMS due to their superior accuracy and repeatability. However, there has not been a widely accepted standard protocol for performing robotic TMS using fine-segmented brain images, resulting in arbitrary planned angles with respect to the true boundaries of the modulated cortex. Given that the recent study in TMS simulation suggests a noticeable difference in outcomes when using different anatomical details, cortical shape should play a more significant role in deciding the optimal TMS coil pose. In this work, we introduce an image-guided robotic system for TMS that focuses on (1) establishing standardized planning methods and heuristics to define a reference (true zero) for the coil poses and (2) solving the issue that the manual coil placement requires expert hand-eye coordination which often leading to low repeatability of the experiments. To validate the design of our robotic system, a phantom study and a preliminary human subject study were performed. Our results show that the robotic method can half the positional error and improve the rotational accuracy by up to two orders of magnitude. The accuracy is proven to be repeatable because the standard deviation of multiple trials is lowered by an order of magnitude. The improved actuation accuracy successfully translates to the TMS application, with a higher and more stable induced voltage in magnetic field sensors.
UVCPNet: A UAV-Vehicle Collaborative Perception Network for 3D Object Detection
Jun 07, 2024With the advancement of collaborative perception, the role of aerial-ground collaborative perception, a crucial component, is becoming increasingly important. The demand for collaborative perception across different perspectives to construct more comprehensive perceptual information is growing. However, challenges arise due to the disparities in the field of view between cross-domain agents and their varying sensitivity to information in images. Additionally, when we transform image features into Bird's Eye View (BEV) features for collaboration, we need accurate depth information. To address these issues, we propose a framework specifically designed for aerial-ground collaboration. First, to mitigate the lack of datasets for aerial-ground collaboration, we develop a virtual dataset named V2U-COO for our research. Second, we design a Cross-Domain Cross-Adaptation (CDCA) module to align the target information obtained from different domains, thereby achieving more accurate perception results. Finally, we introduce a Collaborative Depth Optimization (CDO) module to obtain more precise depth estimation results, leading to more accurate perception outcomes. We conduct extensive experiments on both our virtual dataset and a public dataset to validate the effectiveness of our framework. Our experiments on the V2U-COO dataset and the DAIR-V2X dataset demonstrate that our method improves detection accuracy by 6.1% and 2.7%, respectively.
SSF-Net: Spatial-Spectral Fusion Network with Spectral Angle Awareness for Hyperspectral Object Tracking
Mar 09, 2024



Hyperspectral video (HSV) offers valuable spatial, spectral, and temporal information simultaneously, making it highly suitable for handling challenges such as background clutter and visual similarity in object tracking. However, existing methods primarily focus on band regrouping and rely on RGB trackers for feature extraction, resulting in limited exploration of spectral information and difficulties in achieving complementary representations of object features. In this paper, a spatial-spectral fusion network with spectral angle awareness (SST-Net) is proposed for hyperspectral (HS) object tracking. Firstly, to address the issue of insufficient spectral feature extraction in existing networks, a spatial-spectral feature backbone ($S^2$FB) is designed. With the spatial and spectral extraction branch, a joint representation of texture and spectrum is obtained. Secondly, a spectral attention fusion module (SAFM) is presented to capture the intra- and inter-modality correlation to obtain the fused features from the HS and RGB modalities. It can incorporate the visual information into the HS spectral context to form a robust representation. Thirdly, to ensure a more accurate response of the tracker to the object position, a spectral angle awareness module (SAAM) investigates the region-level spectral similarity between the template and search images during the prediction stage. Furthermore, we develop a novel spectral angle awareness loss (SAAL) to offer guidance for the SAAM based on similar regions. Finally, to obtain the robust tracking results, a weighted prediction method is considered to combine the HS and RGB predicted motions of objects to leverage the strengths of each modality. Extensive experiments on the HOTC dataset demonstrate the effectiveness of the proposed SSF-Net, compared with state-of-the-art trackers.
Wide-Beam Array Antenna Power Gain Maximization via ADMM Framework
Apr 21, 2021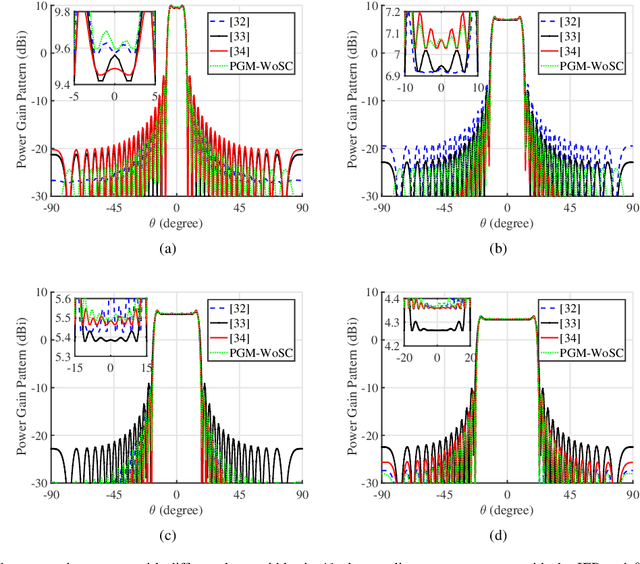
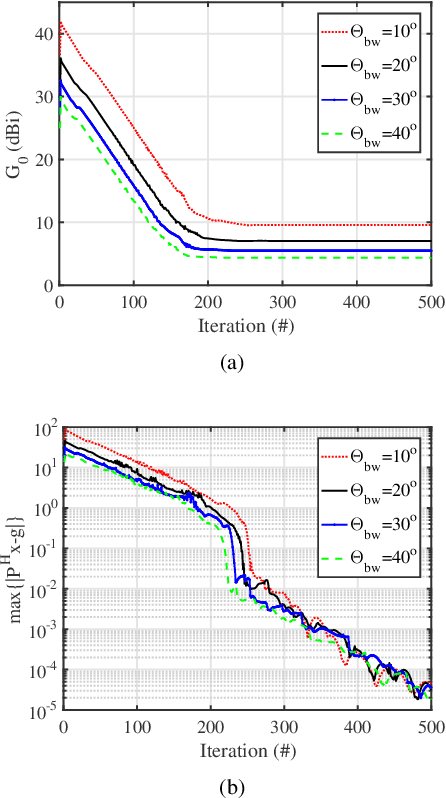
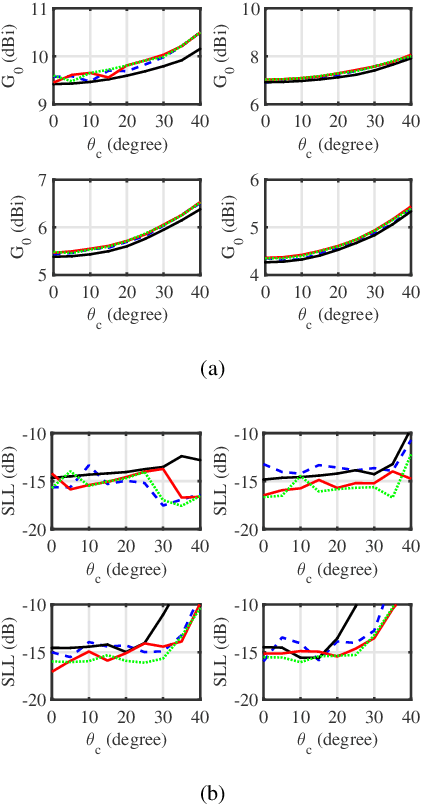
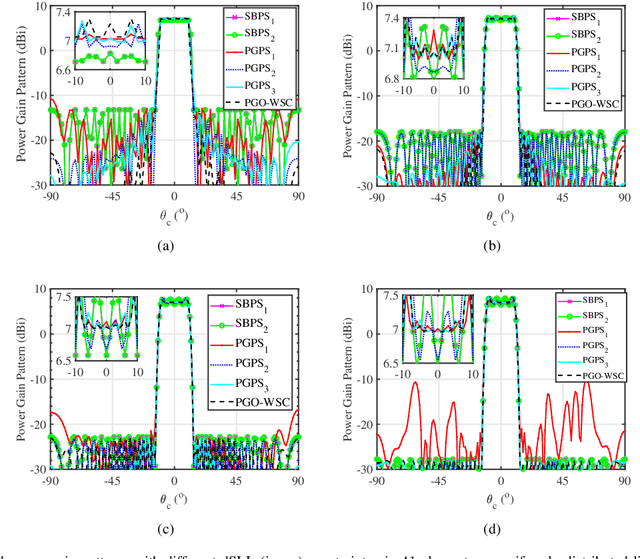
This paper proposes two algorithms to maximize the minimum array power gain in a wide-beam mainlobe by solving the power gain pattern synthesis (PGPS) problem with and without sidelobe constraints. Firstly, the nonconvex PGPS problem is transformed into a nonconvex linear inequality optimization problem and then converted to an augmented Lagrangian problem by introducing auxiliary variables via the Alternating Direction Method of Multipliers (ADMM) framework. Next,the original intractable problem is converted into a series of nonconvex and convex subproblems. The nonconvex subproblems are solved by dividing their solution space into a finite set of smaller ones, in which the solution would be obtained pseudoanalytically. In such a way, the proposed algorithms are superior to the existing PGPS-based ones as their convergence can be theoretically guaranteed with a lower computational burden. Numerical examples with both isotropic element pattern (IEP) and active element pattern (AEP) arrays are simulated to show the effectiveness and superiority of the proposed algorithms by comparing with the related existing algorithms.
Deep Learning Methods for Signature Verification
Dec 08, 2019

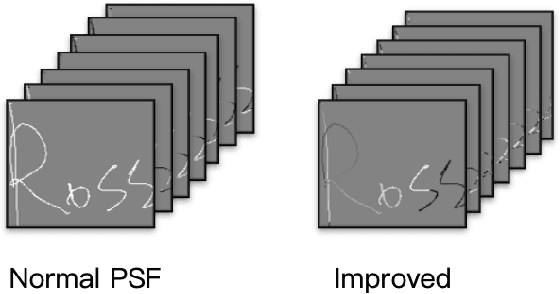
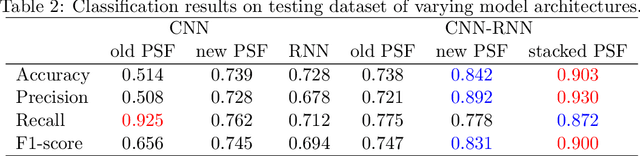
Signature is widely used in human daily lives, and serves as a supplementary characteristic for verifying human identity. However, there is rare work of verifying signature. In this paper, we propose a few deep learning architectures to tackle this task, ranging from CNN, RNN to CNN-RNN compact model. We also improve Path Signature Features by encoding temporal information in order to enlarge the discrepancy between genuine and forgery signatures. Our numerical experiments demonstrate the effectiveness of our constructed models and features representations.
BiRA-Net: Bilinear Attention Net for Diabetic Retinopathy Grading
May 15, 2019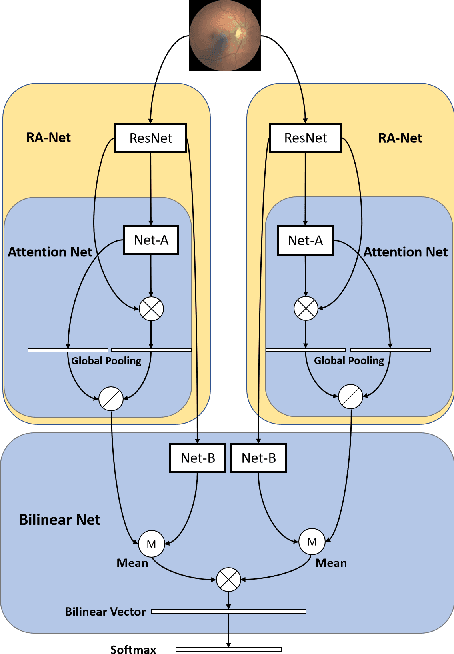
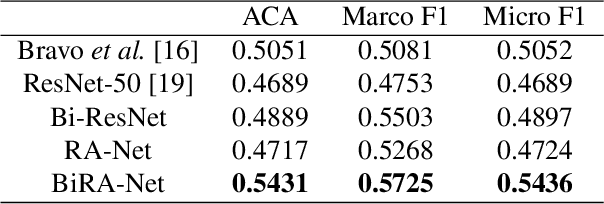


Diabetic retinopathy (DR) is a common retinal disease that leads to blindness. For diagnosis purposes, DR image grading aims to provide automatic DR grade classification, which is not addressed in conventional research methods of binary DR image classification. Small objects in the eye images, like lesions and microaneurysms, are essential to DR grading in medical imaging, but they could easily be influenced by other objects. To address these challenges, we propose a new deep learning architecture, called BiRA-Net, which combines the attention model for feature extraction and bilinear model for fine-grained classification. Furthermore, in considering the distance between different grades of different DR categories, we propose a new loss function, called grading loss, which leads to improved training convergence of the proposed approach. Experimental results are provided to demonstrate the superior performance of the proposed approach.