 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised and Unsupervised Methods for Heart Sounds Classification in Restricted Data Environments
Jun 04, 2020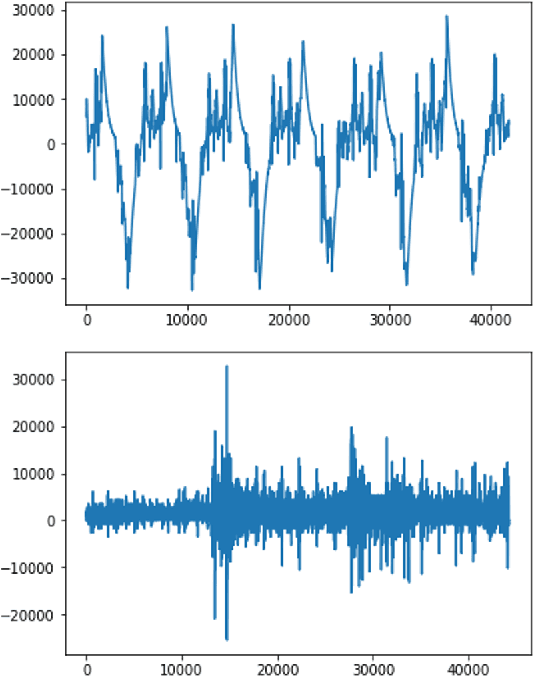


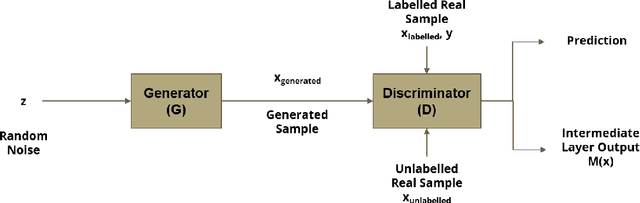
Automated heart sounds classification is a much-required diagnostic tool in the view of increasing incidences of heart related diseases worldwide. In this study, we conduct a comprehensive study of heart sounds classification by using various supervised, semi-supervised and unsupervised approaches on the PhysioNet/CinC 2016 Challenge dataset. Supervised approaches, including deep learning and machine learning methods, require large amounts of labelled data to train the models, which are challenging to obtain in most practical scenarios. In view of the need to reduce the labelling burden for clinical practices, where human labelling is both expensive and time-consuming, semi-supervised or even unsupervised approaches in restricted data setting are desirable. A GAN based semi-supervised method is therefore proposed, which allows the usage of unlabelled data samples to boost the learning of data distribution. It achieves a better performance in terms of AUROC over the supervised baseline when limited data samples exist. Furthermore, several unsupervised methods are explored as an alternative approach by considering the given problem as an anomaly detection scenario. In particular, the unsupervised feature extraction using 1D CNN Autoencoder coupled with one-class SVM obtains good performance without any data labelling. The potential of the proposed semi-supervised and unsupervised methods may lead to a workflow tool in the future for the creation of higher quality datasets.
BiRA-Net: Bilinear Attention Net for Diabetic Retinopathy Grading
May 15, 2019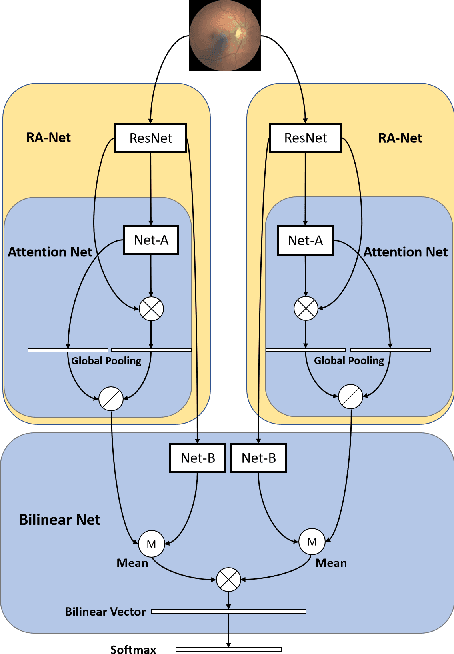
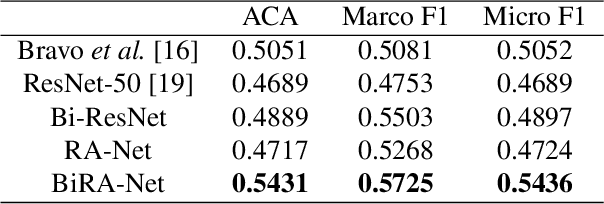


Diabetic retinopathy (DR) is a common retinal disease that leads to blindness. For diagnosis purposes, DR image grading aims to provide automatic DR grade classification, which is not addressed in conventional research methods of binary DR image classification. Small objects in the eye images, like lesions and microaneurysms, are essential to DR grading in medical imaging, but they could easily be influenced by other objects. To address these challenges, we propose a new deep learning architecture, called BiRA-Net, which combines the attention model for feature extraction and bilinear model for fine-grained classification. Furthermore, in considering the distance between different grades of different DR categories, we propose a new loss function, called grading loss, which leads to improved training convergence of the proposed approach. Experimental results are provided to demonstrate the superior performance of the proposed approach.