 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Capture and Replay for Continual Learning
Dec 12, 2020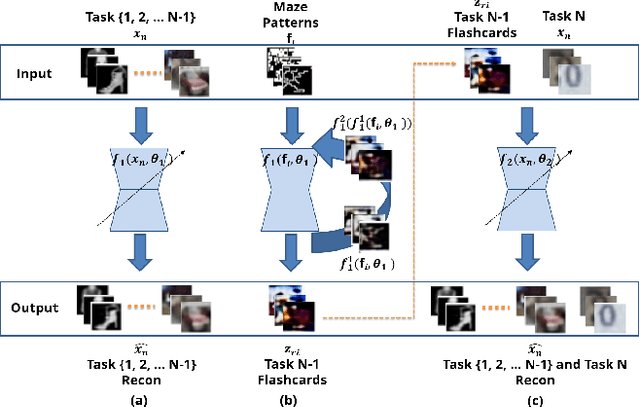
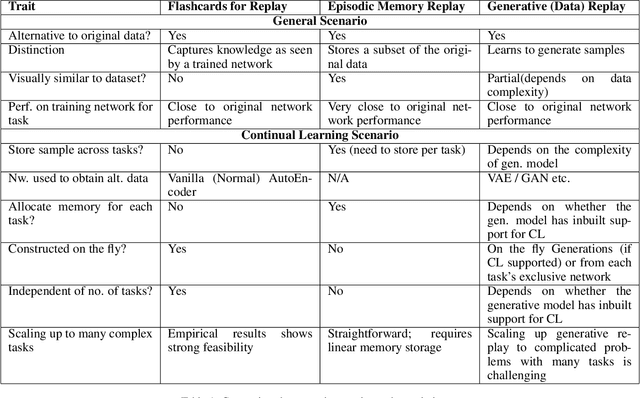
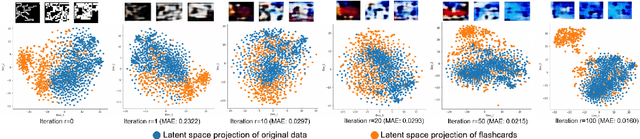
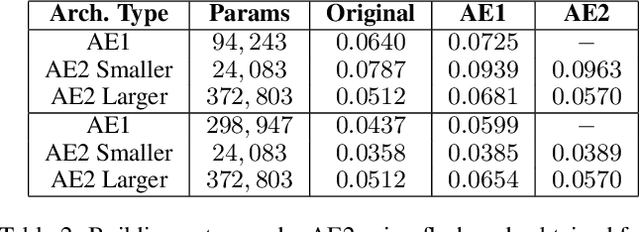
Deep neural networks have shown promise in several domains, and the learned task-specific information is implicitly stored in the network parameters. It will be vital to utilize representations from these networks for downstream tasks such as continual learning. In this paper, we introduce the notion of {\em flashcards} that are visual representations to {\em capture} the encoded knowledge of a network, as a function of random image patterns. We demonstrate the effectiveness of flashcards in capturing representations and show that they are efficient replay methods for general and task agnostic continual learning setting. Thus, while adapting to a new task, a limited number of constructed flashcards, help to prevent catastrophic forgetting of the previously learned tasks. Most interestingly, such flashcards neither require external memory storage nor need to be accumulated over multiple tasks and only need to be constructed just before learning the subsequent new task, irrespective of the number of tasks trained before and are hence task agnostic. We first demonstrate the efficacy of flashcards in capturing knowledge representation from a trained network, and empirically validate the efficacy of flashcards on a variety of continual learning tasks: continual unsupervised reconstruction, continual denoising, and new-instance learning classification, using a number of heterogeneous benchmark datasets. These studies also indicate that continual learning algorithms with flashcards as the replay strategy perform better than other state-of-the-art replay methods, and exhibits on par performance with the best possible baseline using coreset sampling, with the least additional computational complexity and storage.
Semi-supervised and Unsupervised Methods for Heart Sounds Classification in Restricted Data Environments
Jun 04, 2020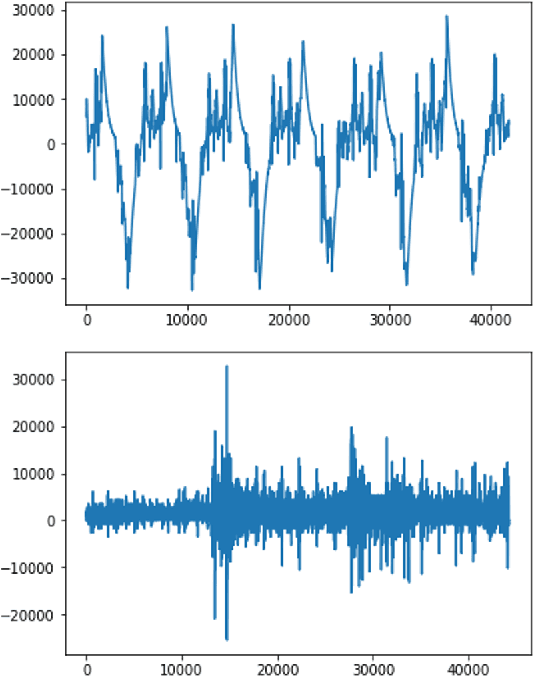


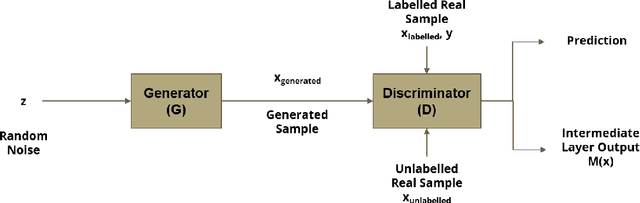
Automated heart sounds classification is a much-required diagnostic tool in the view of increasing incidences of heart related diseases worldwide. In this study, we conduct a comprehensive study of heart sounds classification by using various supervised, semi-supervised and unsupervised approaches on the PhysioNet/CinC 2016 Challenge dataset. Supervised approaches, including deep learning and machine learning methods, require large amounts of labelled data to train the models, which are challenging to obtain in most practical scenarios. In view of the need to reduce the labelling burden for clinical practices, where human labelling is both expensive and time-consuming, semi-supervised or even unsupervised approaches in restricted data setting are desirable. A GAN based semi-supervised method is therefore proposed, which allows the usage of unlabelled data samples to boost the learning of data distribution. It achieves a better performance in terms of AUROC over the supervised baseline when limited data samples exist. Furthermore, several unsupervised methods are explored as an alternative approach by considering the given problem as an anomaly detection scenario. In particular, the unsupervised feature extraction using 1D CNN Autoencoder coupled with one-class SVM obtains good performance without any data labelling. The potential of the proposed semi-supervised and unsupervised methods may lead to a workflow tool in the future for the creation of higher quality datasets.
Classification Representations Can be Reused for Downstream Generations
Apr 16, 2020
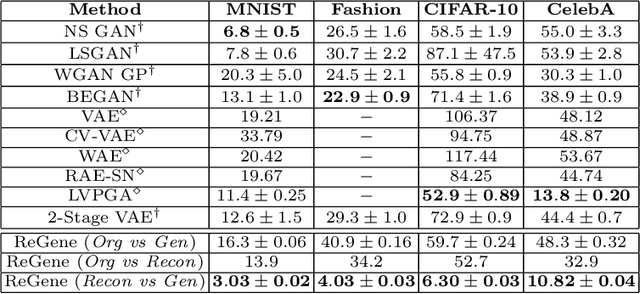
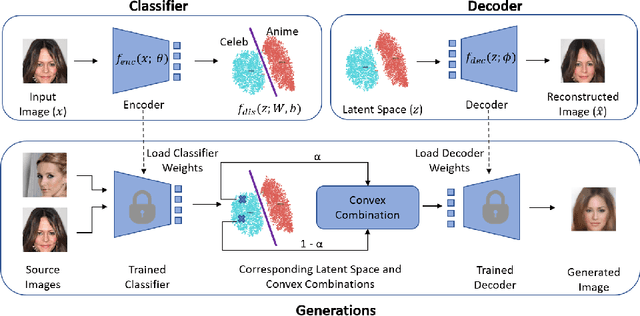

Contrary to the convention of using supervision for class-conditioned $\it{generative}$ $\it{modeling}$, this work explores and demonstrates the feasibility of a learned supervised representation space trained on a discriminative classifier for the $\it{downstream}$ task of sample generation. Unlike generative modeling approaches that aim to $\it{model}$ the manifold distribution, we directly $\it{represent}$ the given data manifold in the classification space and leverage properties of latent space representations to generate new representations that are guaranteed to be in the same class. Interestingly, such representations allow for controlled sample generations for any given class from existing samples and do not require enforcing prior distribution. We show that these latent space representations can be smartly manipulated (using convex combinations of $n$ samples, $n\geq2$) to yield meaningful sample generations. Experiments on image datasets of varying resolutions demonstrate that downstream generations have higher classification accuracy than existing conditional generative models while being competitive in terms of FID.