 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Traceability for Transparent ML Pipelines
Jan 21, 2026Modern machine learning systems are increasingly realised as multistage pipelines, yet existing transparency mechanisms typically operate at a model level: they describe what a system is and why it behaves as it does, but not how individual data samples are operationally recorded, tracked, and verified as they traverse the pipeline. This absence of verifiable, sample-level traceability leaves practitioners and users unable to determine whether a specific sample was used, when it was processed, or whether the corresponding records remain intact over time. We introduce FG-Trac, a model-agnostic framework that establishes verifiable, fine-grained sample-level traceability throughout machine learning pipelines. FG-Trac defines an explicit mechanism for capturing and verifying sample lifecycle events across preprocessing and training, computes contribution scores explicitly grounded in training checkpoints, and anchors these traces to tamper-evident cryptographic commitments. The framework integrates without modifying model architectures or training objectives, reconstructing complete and auditable data-usage histories with practical computational overhead. Experiments on a canonical convolutional neural network and a multimodal graph learning pipeline demonstrate that FG-Trac preserves predictive performance while enabling machine learning systems to furnish verifiable evidence of how individual samples were used and propagated during model execution.
When to Invoke: Refining LLM Fairness with Toxicity Assessment
Jan 14, 2026Large Language Models (LLMs) are increasingly used for toxicity assessment in online moderation systems, where fairness across demographic groups is essential for equitable treatment. However, LLMs often produce inconsistent toxicity judgements for subtle expressions, particularly those involving implicit hate speech, revealing underlying biases that are difficult to correct through standard training. This raises a key question that existing approaches often overlook: when should corrective mechanisms be invoked to ensure fair and reliable assessments? To address this, we propose FairToT, an inference-time framework that enhances LLM fairness through prompt-guided toxicity assessment. FairToT identifies cases where demographic-related variation is likely to occur and determines when additional assessment should be applied. In addition, we introduce two interpretable fairness indicators that detect such cases and improve inference consistency without modifying model parameters. Experiments on benchmark datasets show that FairToT reduces group-level disparities while maintaining stable and reliable toxicity predictions, demonstrating that inference-time refinement offers an effective and practical approach for fairness improvement in LLM-based toxicity assessment systems. The source code can be found at https://aisuko.github.io/fair-tot/.
When to Trust: A Causality-Aware Calibration Framework for Accurate Knowledge Graph Retrieval-Augmented Generation
Jan 14, 2026Knowledge Graph Retrieval-Augmented Generation (KG-RAG) extends the RAG paradigm by incorporating structured knowledge from knowledge graphs, enabling Large Language Models (LLMs) to perform more precise and explainable reasoning. While KG-RAG improves factual accuracy in complex tasks, existing KG-RAG models are often severely overconfident, producing high-confidence predictions even when retrieved sub-graphs are incomplete or unreliable, which raises concerns for deployment in high-stakes domains. To address this issue, we propose Ca2KG, a Causality-aware Calibration framework for KG-RAG. Ca2KG integrates counterfactual prompting, which exposes retrieval-dependent uncertainties in knowledge quality and reasoning reliability, with a panel-based re-scoring mechanism that stabilises predictions across interventions. Extensive experiments on two complex QA datasets demonstrate that Ca2KG consistently improves calibration while maintaining or even enhancing predictive accuracy.
Less Is More? Examining Fairness in Pruned Large Language Models for Summarising Opinions
Aug 25, 2025Model compression through post-training pruning offers a way to reduce model size and computational requirements without significantly impacting model performance. However, the effect of pruning on the fairness of LLM-generated summaries remains unexplored, particularly for opinion summarisation where biased outputs could influence public views.In this paper, we present a comprehensive empirical analysis of opinion summarisation, examining three state-of-the-art pruning methods and various calibration sets across three open-source LLMs using four fairness metrics. Our systematic analysis reveals that pruning methods have a greater impact on fairness than calibration sets. Building on these insights, we propose High Gradient Low Activation (HGLA) pruning, which identifies and removes parameters that are redundant for input processing but influential in output generation. Our experiments demonstrate that HGLA can better maintain or even improve fairness compared to existing methods, showing promise across models and tasks where traditional methods have limitations. Our human evaluation shows HGLA-generated outputs are fairer than existing state-of-the-art pruning methods. Code is available at: https://github.com/amberhuang01/HGLA.
Foundation Models for Anomaly Detection: Vision and Challenges
Feb 10, 2025



As data continues to grow in volume and complexity across domains such as finance, manufacturing, and healthcare, effective anomaly detection is essential for identifying irregular patterns that may signal critical issues. Recently, foundation models (FMs) have emerged as a powerful tool for advancing anomaly detection. They have demonstrated unprecedented capabilities in enhancing anomaly identification, generating detailed data descriptions, and providing visual explanations. This survey presents the first comprehensive review of recent advancements in FM-based anomaly detection. We propose a novel taxonomy that classifies FMs into three categories based on their roles in anomaly detection tasks, i.e., as encoders, detectors, or interpreters. We provide a systematic analysis of state-of-the-art methods and discuss key challenges in leveraging FMs for improved anomaly detection. We also outline future research directions in this rapidly evolving field.
Bias in Opinion Summarisation from Pre-training to Adaptation: A Case Study in Political Bias
Feb 01, 2024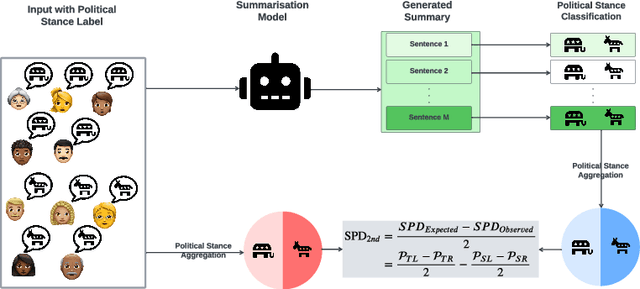



Opinion summarisation aims to summarise the salient information and opinions presented in documents such as product reviews, discussion forums, and social media texts into short summaries that enable users to effectively understand the opinions therein. Generating biased summaries has the risk of potentially swaying public opinion. Previous studies focused on studying bias in opinion summarisation using extractive models, but limited research has paid attention to abstractive summarisation models. In this study, using political bias as a case study, we first establish a methodology to quantify bias in abstractive models, then trace it from the pre-trained models to the task of summarising social media opinions using different models and adaptation methods. We find that most models exhibit intrinsic bias. Using a social media text summarisation dataset and contrasting various adaptation methods, we find that tuning a smaller number of parameters is less biased compared to standard fine-tuning; however, the diversity of topics in training data used for fine-tuning is critical.
Examining Bias in Opinion Summarisation Through the Perspective of Opinion Diversity
Jun 07, 2023


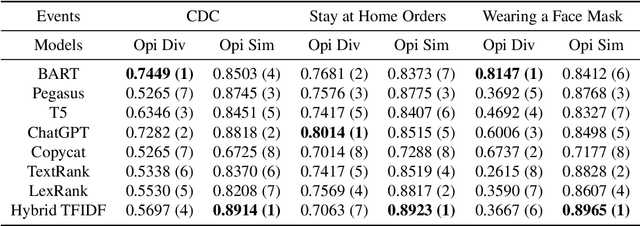
Opinion summarisation is a task that aims to condense the information presented in the source documents while retaining the core message and opinions. A summary that only represents the majority opinions will leave the minority opinions unrepresented in the summary. In this paper, we use the stance towards a certain target as an opinion. We study bias in opinion summarisation from the perspective of opinion diversity, which measures whether the model generated summary can cover a diverse set of opinions. In addition, we examine opinion similarity, a measure of how closely related two opinions are in terms of their stance on a given topic, and its relationship with opinion diversity. Through the lens of stances towards a topic, we examine opinion diversity and similarity using three debatable topics under COVID-19. Experimental results on these topics revealed that a higher degree of similarity of opinions did not indicate good diversity or fairly cover the various opinions originally presented in the source documents. We found that BART and ChatGPT can better capture diverse opinions presented in the source documents.
Knowledge Capture and Replay for Continual Learning
Dec 12, 2020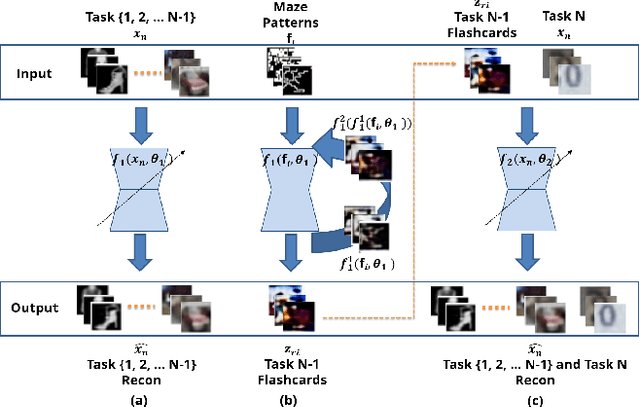
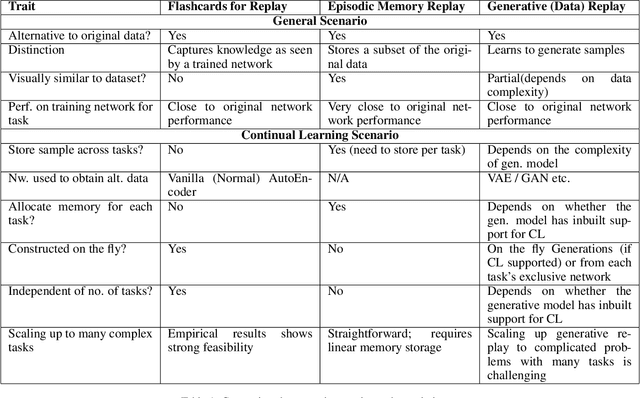
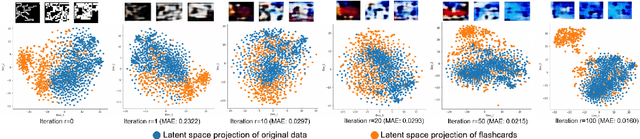
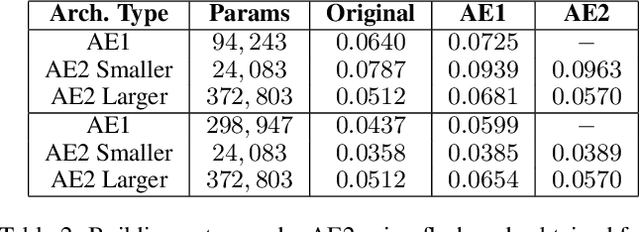
Deep neural networks have shown promise in several domains, and the learned task-specific information is implicitly stored in the network parameters. It will be vital to utilize representations from these networks for downstream tasks such as continual learning. In this paper, we introduce the notion of {\em flashcards} that are visual representations to {\em capture} the encoded knowledge of a network, as a function of random image patterns. We demonstrate the effectiveness of flashcards in capturing representations and show that they are efficient replay methods for general and task agnostic continual learning setting. Thus, while adapting to a new task, a limited number of constructed flashcards, help to prevent catastrophic forgetting of the previously learned tasks. Most interestingly, such flashcards neither require external memory storage nor need to be accumulated over multiple tasks and only need to be constructed just before learning the subsequent new task, irrespective of the number of tasks trained before and are hence task agnostic. We first demonstrate the efficacy of flashcards in capturing knowledge representation from a trained network, and empirically validate the efficacy of flashcards on a variety of continual learning tasks: continual unsupervised reconstruction, continual denoising, and new-instance learning classification, using a number of heterogeneous benchmark datasets. These studies also indicate that continual learning algorithms with flashcards as the replay strategy perform better than other state-of-the-art replay methods, and exhibits on par performance with the best possible baseline using coreset sampling, with the least additional computational complexity and storage.