 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
Improving Methodologies for LLM Evaluations Across Global Languages
Jan 22, 2026As frontier AI models are deployed globally, it is essential that their behaviour remains safe and reliable across diverse linguistic and cultural contexts. To examine how current model safeguards hold up in such settings, participants from the International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the EU, France, Kenya, South Korea and the UK conducted a joint multilingual evaluation exercise. Led by Singapore AISI, two open-weight models were tested across ten languages spanning high and low resourced groups: Cantonese English, Farsi, French, Japanese, Korean, Kiswahili, Malay, Mandarin Chinese and Telugu. Over 6,000 newly translated prompts were evaluated across five harm categories (privacy, non-violent crime, violent crime, intellectual property and jailbreak robustness), using both LLM-as-a-judge and human annotation. The exercise shows how safety behaviours can vary across languages. These include differences in safeguard robustness across languages and harm types and variation in evaluator reliability (LLM-as-judge vs. human review). Further, it also generated methodological insights for improving multilingual safety evaluations, such as the need for culturally contextualised translations, stress-tested evaluator prompts and clearer human annotation guidelines. This work represents an initial step toward a shared framework for multilingual safety testing of advanced AI systems and calls for continued collaboration with the wider research community and industry.
Environment-Aware Code Generation: How far are We?
Jan 18, 2026Recent progress in large language models (LLMs) has improved code generation, but most evaluations still test isolated, small-scale code (e.g., a single function) under default or unspecified software environments. As a result, it is unclear whether LLMs can reliably generate executable code tailored to a user's specific environment. We present the first systematic study of Environment-Aware Code Generation (EACG), where generated code must be functionally correct and directly executable under arbitrary software configurations. To enable realistic evaluation, we introduce VersiBCB, a benchmark that is multi-package, execution-verified, and deprecation-aware, capturing complex and evolving environments that prior datasets often overlook. Using VersiBCB, we investigate three complementary adaptation axes: data, parameters, and cache, and develop representative strategies for each. Our results show that current LLMs struggle with environment-specific code generation, while our adaptations improve environment compatibility and executability. These findings highlight key challenges and opportunities for deploying LLMs in practical software engineering workflows.
MARIA: A Framework for Marginal Risk Assessment without Ground Truth in AI Systems
Oct 31, 2025Before deploying an AI system to replace an existing process, it must be compared with the incumbent to ensure improvement without added risk. Traditional evaluation relies on ground truth for both systems, but this is often unavailable due to delayed or unknowable outcomes, high costs, or incomplete data, especially for long-standing systems deemed safe by convention. The more practical solution is not to compute absolute risk but the difference between systems. We therefore propose a marginal risk assessment framework, that avoids dependence on ground truth or absolute risk. It emphasizes three kinds of relative evaluation methodology, including predictability, capability and interaction dominance. By shifting focus from absolute to relative evaluation, our approach equips software teams with actionable guidance: identifying where AI enhances outcomes, where it introduces new risks, and how to adopt such systems responsibly.
Foundation Models for Anomaly Detection: Vision and Challenges
Feb 10, 2025



As data continues to grow in volume and complexity across domains such as finance, manufacturing, and healthcare, effective anomaly detection is essential for identifying irregular patterns that may signal critical issues. Recently, foundation models (FMs) have emerged as a powerful tool for advancing anomaly detection. They have demonstrated unprecedented capabilities in enhancing anomaly identification, generating detailed data descriptions, and providing visual explanations. This survey presents the first comprehensive review of recent advancements in FM-based anomaly detection. We propose a novel taxonomy that classifies FMs into three categories based on their roles in anomaly detection tasks, i.e., as encoders, detectors, or interpreters. We provide a systematic analysis of state-of-the-art methods and discuss key challenges in leveraging FMs for improved anomaly detection. We also outline future research directions in this rapidly evolving field.
VersiCode: Towards Version-controllable Code Generation
Jun 11, 2024

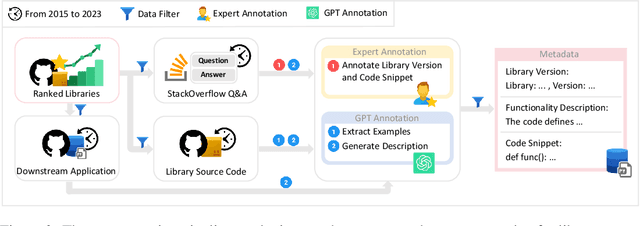

Significant research has focused on improving the performance of large language model on code-related tasks due to their practical importance. Although performance is typically evaluated using public benchmark datasets, the existing datasets do not account for the concept of \emph{version}, which is crucial in professional software development. In this paper, we introduce VersiCode, the first comprehensive dataset designed to assess the ability of large language models to generate verifiable code for specific library versions. VersiCode encompasses 300 libraries across more than 2,000 versions spanning 9 years. We design two dedicated evaluation tasks: version-specific code completion (VSCC) and version-aware code editing (VACE). Comprehensive experiments are conducted to benchmark the performance of LLMs, revealing the challenging nature of these tasks and VersiCode, that even state-of-the-art LLMs struggle to generate version-correct code. This dataset, together with the proposed tasks, sheds light on LLMs' capabilities and limitations in handling version-specific code generation, and opens up an important new area of research for further investigation. The resources can be found at https://github.com/wutong8023/VersiCode.